Présentation
Apache Spark est un framework open source qui traite de gros volumes de données de flux provenant de plusieurs sources. Spark est utilisé dans l'informatique distribuée avec des applications d'apprentissage automatique, l'analyse de données et le traitement parallèle des graphes.
Ce guide vous montrera comment installer Apache Spark sur Windows 10 et testez l'installation.

Prérequis
- Un système exécutant Windows 10
- Un compte utilisateur avec des privilèges d'administrateur (requis pour installer le logiciel, modifier les autorisations de fichiers et modifier le PATH du système)
- Invite de commandes ou Powershell
- Un outil pour extraire les fichiers .tar, comme 7-Zip
Installer Apache Spark sous Windows
L'installation d'Apache Spark sur Windows 10 peut sembler compliquée pour les utilisateurs novices, mais ce tutoriel simple vous permettra d'être opérationnel. Si Java 8 et Python 3 sont déjà installés, vous pouvez ignorer les deux premières étapes.
Étape 1 :Installez Java 8
Apache Spark nécessite Java 8. Vous pouvez vérifier si Java est installé à l'aide de l'invite de commande.
Ouvrez la ligne de commande en cliquant sur Démarrer> tapez cmd> cliquez sur Invite de commandes .
Tapez la commande suivante dans l'invite de commande :
java -versionSi Java est installé, il répondra avec la sortie suivante :
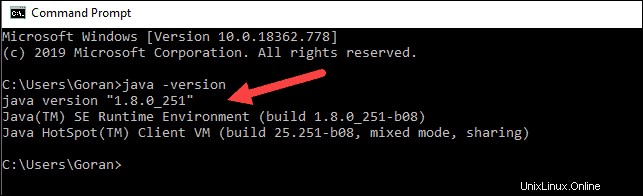
Votre version peut être différente. Le deuxième chiffre est la version de Java - dans ce cas, Java 8.
Si Java n'est pas installé :
1. Ouvrez une fenêtre de navigateur et accédez à https://java.com/en/download/.
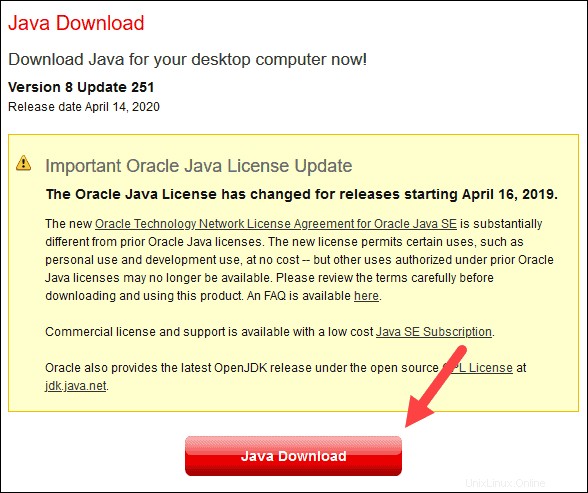
2. Cliquez sur Téléchargement Java et enregistrez le fichier à l'emplacement de votre choix.
3. Une fois le téléchargement terminé, double-cliquez sur le fichier pour installer Java.
Étape 2 :Installer Python
1. Pour installer le gestionnaire de packages Python, accédez à https://www.python.org/ dans votre navigateur Web.
2. Passez la souris sur Télécharger option de menu et cliquez sur Python 3.8.3 . 3.8.3 est la dernière version au moment de la rédaction de l'article.
3. Une fois le téléchargement terminé, exécutez le fichier.
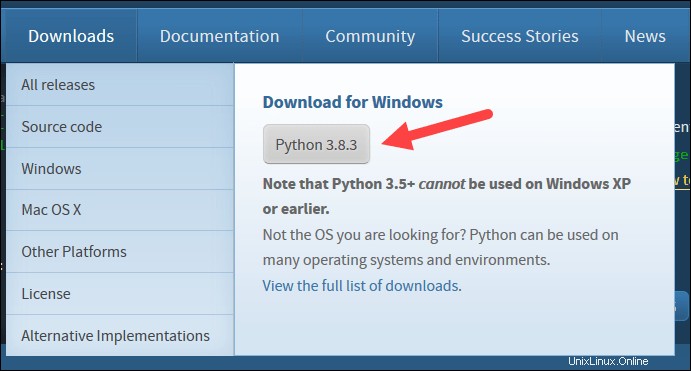
4. Près du bas de la première boîte de dialogue de configuration, cochez Ajouter Python 3.8 à PATH . Laissez l'autre case cochée.
5. Ensuite, cliquez sur Personnaliser l'installation .
6. Vous pouvez laisser toutes les cases cochées à cette étape, ou vous pouvez décocher les options que vous ne voulez pas.
7. Cliquez sur Suivant .
8. Cochez la case Installer pour tous les utilisateurs et laissez les autres cases telles quelles.
9. Sous Personnaliser l'emplacement d'installation cliquez sur Parcourir et accédez au lecteur C. Ajoutez un nouveau dossier et nommez-le Python .
10. Sélectionnez ce dossier et cliquez sur OK .
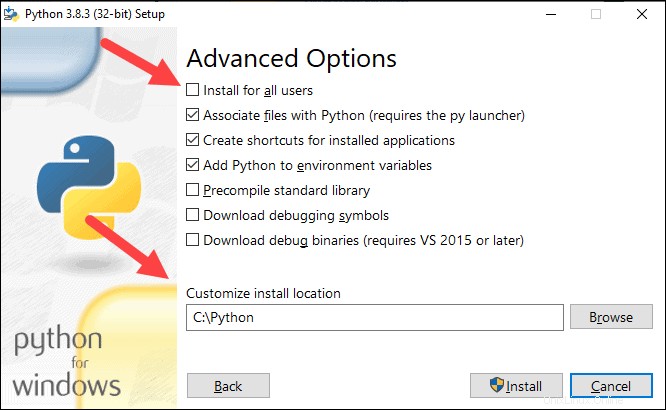
11. Cliquez sur Installer , et laissez l'installation se terminer.
12. Une fois l'installation terminée, cliquez sur Désactiver la limite de longueur de chemin option en bas, puis cliquez sur Fermer .
13. Si une invite de commande est ouverte, redémarrez-la. Vérifiez l'installation en vérifiant la version de Python :
python --version
La sortie doit imprimer Python 3.8.3 .
Étape 3 :Téléchargez Apache Spark
1. Ouvrez un navigateur et accédez à https://spark.apache.org/downloads.html.
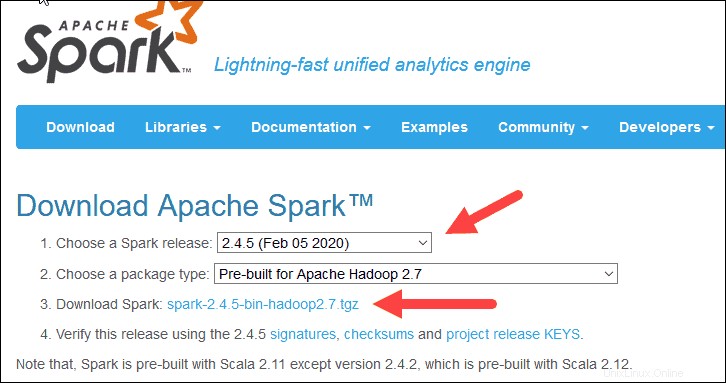
2. Sous Télécharger Apache Spark titre, il y a deux menus déroulants. Utilisez la version actuelle sans prévisualisation.
- Dans notre cas, dans Choisissez une release Spark menu déroulant sélectionnez 2.4.5 (05 février 2020) .
- Dans le deuxième menu déroulant, Choisissez un type de package , laissez la sélection Pré-construit pour Apache Hadoop 2.7 .
3. Cliquez sur spark-2.4.5-bin-hadoop2.7.tgz lien.
4. Une page avec une liste de miroirs se charge où vous pouvez voir différents serveurs à partir desquels télécharger. Choisissez-en un dans la liste et enregistrez le fichier dans votre dossier Téléchargements.
Étape 4 :Vérifier le fichier du logiciel Spark
1. Vérifiez l'intégrité de votre téléchargement en vérifiant la somme de contrôle du dossier. Cela garantit que vous travaillez avec un logiciel non modifié et non corrompu.
2. Revenez au téléchargement Spark page et ouvrez la Checksum lien, de préférence dans un nouvel onglet.
3. Ensuite, ouvrez une ligne de commande et saisissez la commande suivante :
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Remplacez le nom d'utilisateur par votre nom d'utilisateur. Le système affiche un long code alphanumérique, ainsi que le message Certutil: -hashfile completed successfully .
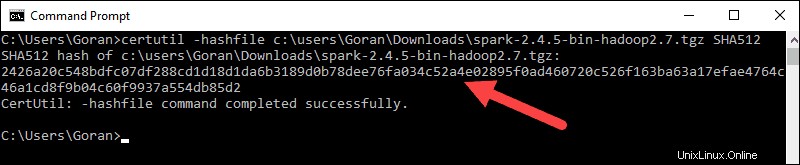
5. Comparez le code à celui que vous avez ouvert dans un nouvel onglet du navigateur. S'ils correspondent, votre fichier de téléchargement n'est pas corrompu.
Étape 5 :Installer Apache Spark
L'installation d'Apache Spark implique l'extraction du fichier téléchargé à l'emplacement souhaité.
1. Créez un nouveau dossier nommé Spark à la racine de votre lecteur C:. À partir d'une ligne de commande, saisissez ce qui suit :
cd \
mkdir Spark2. Dans l'explorateur, localisez le fichier Spark que vous avez téléchargé.
3. Cliquez avec le bouton droit sur le fichier et extrayez-le vers C:\Spark en utilisant l'outil que vous avez sur votre système (par exemple, 7-Zip).
4. Maintenant, votre C:\Spark dossier a un nouveau dossier spark-2.4.5-bin-hadoop2.7 avec les fichiers nécessaires à l'intérieur.
Étape 6 :Ajouter le fichier winutils.exe
Téléchargez le fichier winutils.exe fichier pour la version sous-jacente de Hadoop pour l'installation de Spark que vous avez téléchargée.
1. Accédez à cette URL https://github.com/cdarlint/winutils et à l'intérieur du bin dossier, localisez winutils.exe , et cliquez dessus.
2. Trouvez le téléchargement bouton sur le côté droit pour télécharger le fichier.
3. Maintenant, créez de nouveaux dossiers Hadoop et bin sur C :à l'aide de l'Explorateur Windows ou de l'invite de commande.
4. Copiez le fichier winutils.exe du dossier Téléchargements vers C:\hadoop\bin .
Étape 7 :Configurer les variables d'environnement
La configuration des variables d'environnement dans Windows ajoute les emplacements Spark et Hadoop à votre système PATH. Il vous permet d'exécuter le shell Spark directement à partir d'une fenêtre d'invite de commande.
1. Cliquez sur Démarrer et tapez environnement .
2. Sélectionnez le résultat intitulé Modifier les variables d'environnement système .
3. Une boîte de dialogue Propriétés système s'affiche. Dans le coin inférieur droit, cliquez sur Variables d'environnement puis cliquez sur Nouveau dans la fenêtre suivante.
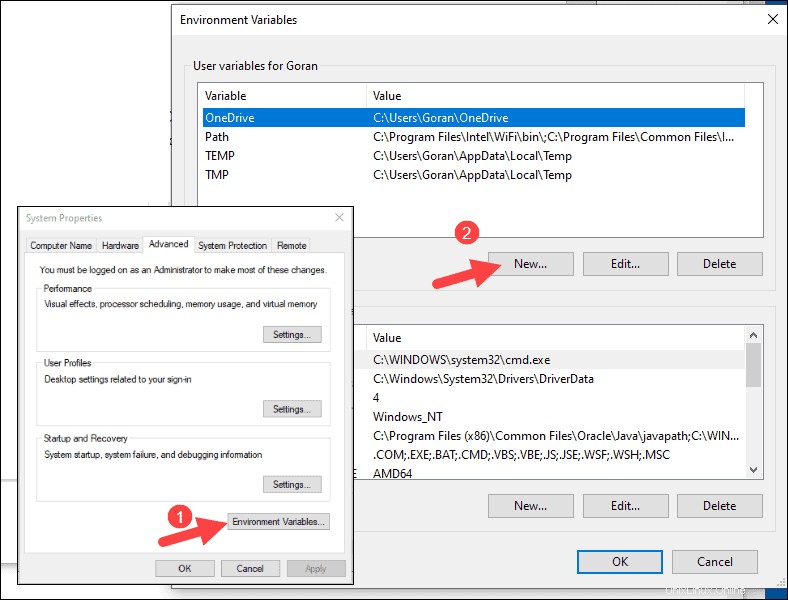
4. Pour Nom de la variable tapez SPARK_HOME .
5. Pour Valeur variable saisissez C:\Spark\spark-2.4.5-bin-hadoop2.7 et cliquez sur OK. Si vous avez modifié le chemin du dossier, utilisez celui-ci à la place.
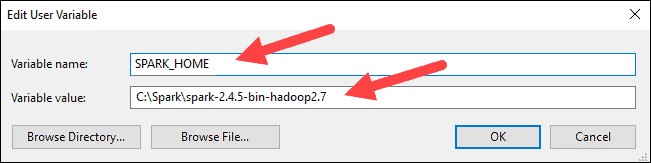
6. Dans la zone supérieure, cliquez sur Chemin entrée, puis cliquez sur Modifier . Soyez prudent lorsque vous modifiez le chemin du système. Évitez de supprimer des entrées déjà sur la liste.
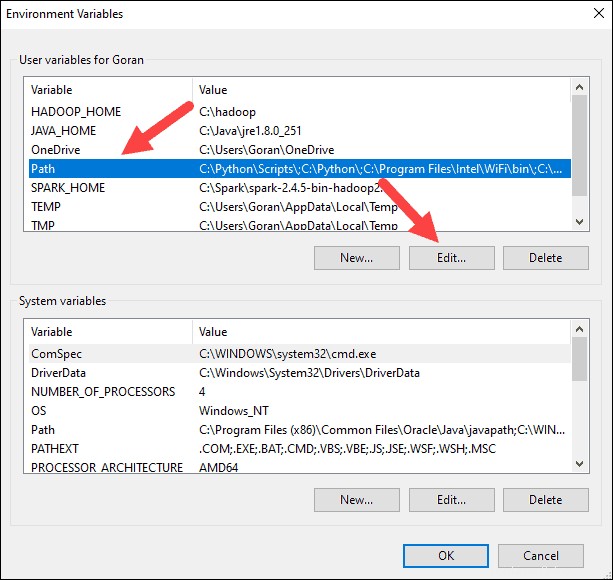
7. Vous devriez voir une boîte avec des entrées sur la gauche. Sur la droite, cliquez sur Nouveau .
8. Le système met en surbrillance une nouvelle ligne. Entrez le chemin d'accès au dossier Spark C:\Spark\spark-2.4.5-bin-hadoop2.7\bin . Nous vous recommandons d'utiliser %SPARK_HOME%\bin pour éviter d'éventuels problèmes avec le chemin.
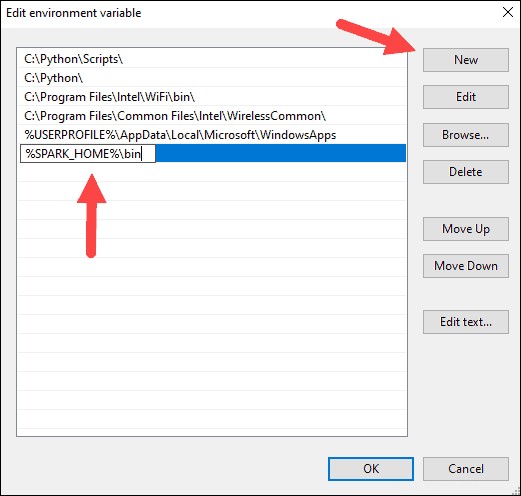
9. Répétez ce processus pour Hadoop et Java.
- Pour Hadoop, le nom de la variable est HADOOP_HOME et pour la valeur, utilisez le chemin du dossier que vous avez créé précédemment :C:\hadoop. Ajouter C:\hadoop\bin à la variable de chemin champ, mais nous vous recommandons d'utiliser %HADOOP_HOME%\bin .
- Pour Java, le nom de la variable est JAVA_HOME et pour la valeur, utilisez le chemin vers votre répertoire Java JDK (dans notre cas, c'est C:\Program Files\Java\jdk1.8.0_251 ).
10. Cliquez sur OK pour fermer toutes les fenêtres ouvertes.
Étape 8 :Lancer Spark
1. Ouvrez une nouvelle fenêtre d'invite de commande à l'aide du clic droit et Exécuter en tant qu'administrateur :
2. Pour démarrer Spark, saisissez :
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Si vous définissez le chemin d'accès à l'environnement correctement, vous pouvez taper spark-shell pour lancer Spark.
3. Le système devrait afficher plusieurs lignes indiquant le statut de la demande. Vous pouvez obtenir une fenêtre contextuelle Java. Sélectionnez Autoriser l'accès pour continuer.
Enfin, le logo Spark apparaît et l'invite affiche le shell Scala .
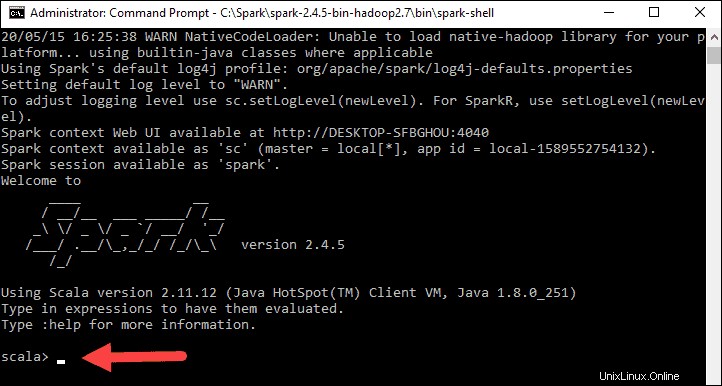
4., Ouvrez un navigateur Web et accédez à http://localhost:4040/ .
5. Vous pouvez remplacer localhost avec le nom de votre système.
6. Vous devriez voir une interface utilisateur Web du shell Apache Spark. L'exemple ci-dessous montre les exécuteurs page.
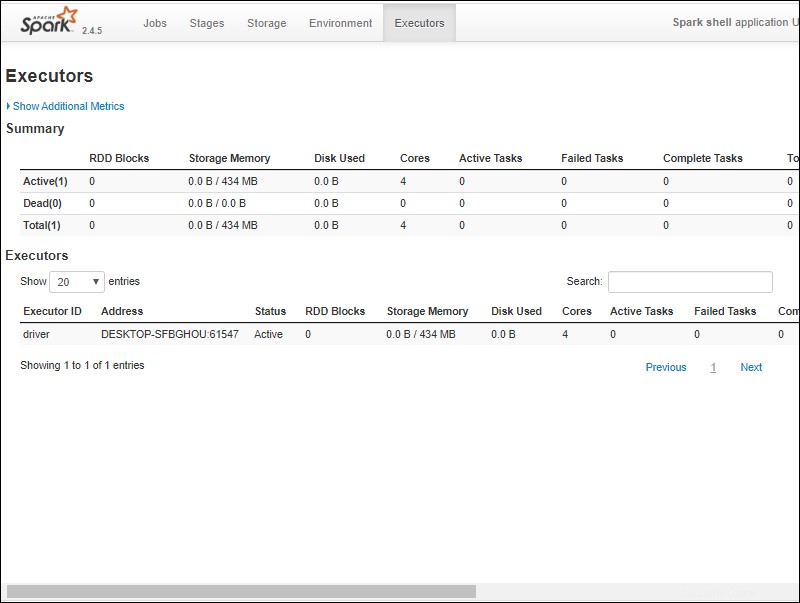
7. Pour quitter Spark et fermer le shell Scala, appuyez sur ctrl-d dans la fenêtre d'invite de commande.
Tester l'étincelle
Dans cet exemple, nous allons lancer le shell Spark et utiliser Scala pour lire le contenu d'un fichier. Vous pouvez utiliser un fichier existant, tel que le README fichier dans le répertoire Spark, ou vous pouvez créer le vôtre. Nous avons créé pnaptest avec du texte.
1. Ouvrez une fenêtre d'invite de commande et accédez au dossier contenant le fichier que vous souhaitez utiliser et lancez le shell Spark.
2. Tout d'abord, indiquez une variable à utiliser dans le contexte Spark avec le nom du fichier. N'oubliez pas d'ajouter l'extension de fichier s'il y en a.
val x =sc.textFile("pnaptest")3. La sortie montre qu'un RDD est créé. Ensuite, nous pouvons afficher le contenu du fichier en utilisant cette commande pour appeler une action :
x.take(11).foreach(println)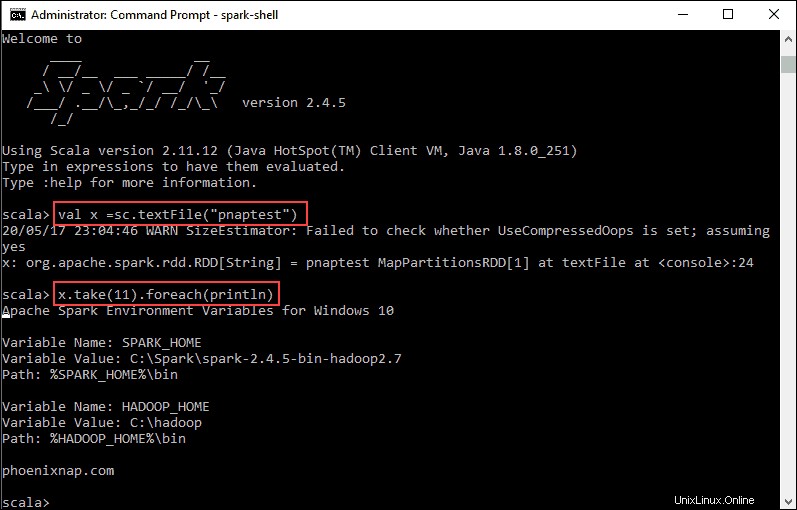
Cette commande demande à Spark d'imprimer 11 lignes à partir du fichier que vous avez spécifié. Pour effectuer une action sur ce fichier (valeur x ), ajoutez une autre valeur y , et effectuez une transformation de carte.
4. Par exemple, vous pouvez imprimer les caractères à l'envers avec cette commande :
val y = x.map(_.reverse)5. Le système crée un RDD enfant par rapport au premier. Ensuite, spécifiez le nombre de lignes que vous souhaitez imprimer à partir de la valeur y :
y.take(11).foreach(println)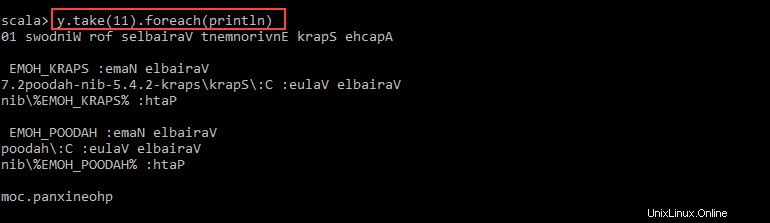
La sortie imprime 11 lignes du pnaptest fichier dans l'ordre inverse.
Une fois terminé, quittez le shell en utilisant ctrl-d .