Apache Spark est un framework open source et un système informatique en cluster à usage général. Spark fournit des API de haut niveau en Java, Scala, Python et R qui prennent en charge les graphiques d'exécution généraux. Il est livré avec des modules intégrés utilisés pour le streaming, SQL, l'apprentissage automatique et le traitement des graphes. Il est capable d'analyser une grande quantité de données et de la distribuer à travers le cluster et de traiter les données en parallèle.
Dans ce tutoriel, nous expliquerons comment installer la pile de calcul de cluster Apache Spark sur Ubuntu 20.04.
Prérequis
- Un serveur exécutant le serveur Ubuntu 20.04.
- Un mot de passe root est configuré sur le serveur.
Mise en route
Tout d'abord, vous devrez mettre à jour vos packages système vers la dernière version. Vous pouvez tous les mettre à jour avec la commande suivante :
apt-get update -y
Une fois tous les packages mis à jour, vous pouvez passer à l'étape suivante.
Installer Java
Apache Spark est une application basée sur Java. Java doit donc être installé sur votre système. Vous pouvez l'installer avec la commande suivante :
apt-get install default-jdk -y
Une fois Java installé, vérifiez la version installée de Java avec la commande suivante :
java --version
Vous devriez voir le résultat suivant :
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Installer Scala
Apache Spark est développé à l'aide de Scala. Vous devrez donc installer Scala dans votre système. Vous pouvez l'installer avec la commande suivante :
apt-get install scala -y
Après avoir installé Scala. Vous pouvez vérifier la version de Scala à l'aide de la commande suivante :
scala -version
Vous devriez voir le résultat suivant :
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Maintenant, connectez-vous à l'interface Scala avec la commande suivante :
scala
Vous devriez obtenir le résultat suivant :
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8). Type in expressions for evaluation. Or try :help.
Maintenant, testez Scala avec la commande suivante :
scala> println("Hitesh Jethva") Vous devriez obtenir le résultat suivant :
Hitesh Jethva
Installer Apache Spark
Tout d'abord, vous devrez télécharger la dernière version d'Apache Spark à partir de son site officiel. Au moment de la rédaction de ce tutoriel, la dernière version d'Apache Spark est la 2.4.6. Vous pouvez le télécharger dans le répertoire /opt avec la commande suivante :
cd /opt
wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Une fois téléchargé, extrayez le fichier téléchargé avec la commande suivante :
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
Ensuite, renommez le répertoire extrait en spark comme indiqué ci-dessous :
mv spark-2.4.6-bin-hadoop2.7 spark
Ensuite, vous devrez configurer l'environnement Spark afin de pouvoir exécuter facilement les commandes Spark. Vous pouvez le configurer en éditant le fichier .bashrc :
nano ~/.bashrc
Ajoutez les lignes suivantes à la fin du fichier :
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Enregistrez et fermez le fichier puis activez l'environnement avec la commande suivante :
source ~/.bashrc
Démarrer le serveur maître Spark
À ce stade, Apache Spark est installé et configuré. Maintenant, démarrez le serveur maître Spark à l'aide de la commande suivante :
start-master.sh
Vous devriez voir le résultat suivant :
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Par défaut, Spark écoute sur le port 8080. Vous pouvez le vérifier à l'aide de la commande suivante :
ss -tpln | grep 8080
Vous devriez voir le résultat suivant :
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Maintenant, ouvrez votre navigateur Web et accédez à l'interface Web Spark à l'aide de l'URL http://your-server-ip:8080. Vous devriez voir l'écran suivant :
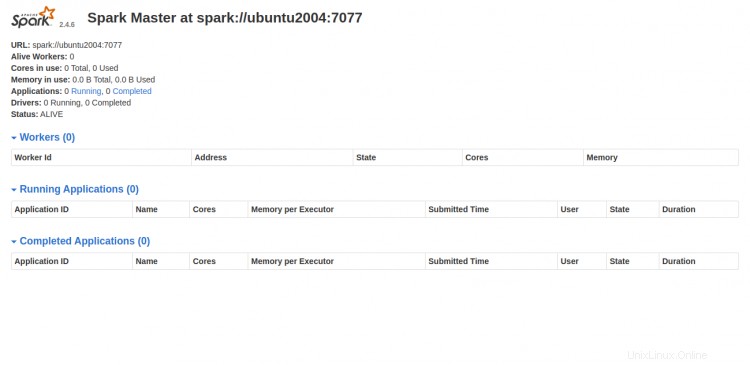
Démarrer le processus de travail Spark
Comme vous pouvez le voir, le service maître Spark s'exécute sur spark://your-server-ip:7077. Vous pouvez donc utiliser cette adresse pour démarrer le processus de travail Spark à l'aide de la commande suivante :
start-slave.sh spark://your-server-ip:7077
Vous devriez voir le résultat suivant :
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Maintenant, accédez au tableau de bord Spark et actualisez l'écran. Vous devriez voir le processus de travail Spark dans l'écran suivant :
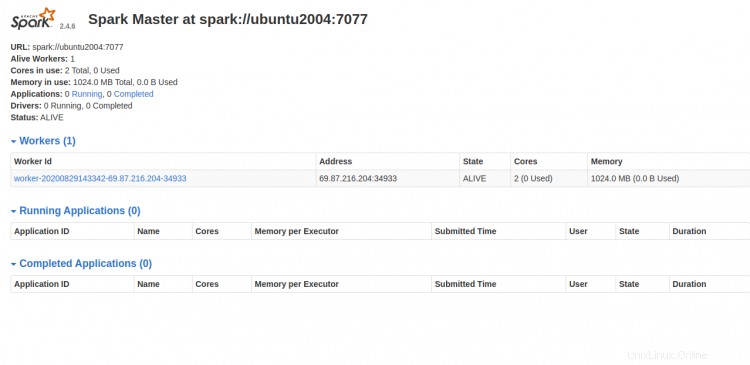
Travailler avec Spark Shell
Vous pouvez également connecter le serveur Spark à l'aide de la ligne de commande. Vous pouvez le connecter à l'aide de la commande spark-shell comme indiqué ci-dessous :
spark-shell
Une fois connecté, vous devriez voir la sortie suivante :
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:35:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Si vous souhaitez utiliser Python dans Spark. Vous pouvez utiliser l'utilitaire de ligne de commande pyspark.
Tout d'abord, installez la version 2 de Python avec la commande suivante :
apt-get install python -y
Une fois installé, vous pouvez connecter le Spark avec la commande suivante :
pyspark
Une fois connecté, vous devriez obtenir le résultat suivant :
Python 2.7.18rc1 (default, Apr 7 2020, 12:05:55)
[GCC 9.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:36:40 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55)
SparkSession available as 'spark'.
>>>
Si vous souhaitez arrêter le serveur maître et esclave. Vous pouvez le faire avec la commande suivante :
stop-slave.sh
stop-master.sh
Conclusion
Toutes nos félicitations! vous avez installé avec succès Apache Spark sur le serveur Ubuntu 20.04. Vous devriez maintenant pouvoir effectuer des tests de base avant de commencer à configurer un cluster Spark. N'hésitez pas à me demander si vous avez des questions.