Apache Spark est un cadre de calcul open source pour les données analytiques à grande échelle et le traitement de l'apprentissage automatique. Il prend en charge divers langages préférés tels que scala, R, Python et Java. Il fournit des outils de haut niveau pour le Spark Streaming, GraphX pour le traitement des graphes, SQL, MLLib.
Dans cet article, vous découvrirez comment installer et configurer Apache Spark sur Ubuntu. Pour démontrer le flux dans cet article, j'ai utilisé le système de version Ubuntu 20.04 LTS. Avant d'installer Apache Spark, vous devez installer Scala ainsi que scala sur votre système.
Installer Scala
Si vous n'avez pas installé Java et Scala, vous pouvez suivre le processus suivant pour l'installer.
Pour Java, nous installerons open JDK 8 ou vous pouvez installer votre version préférée.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Si vous avez besoin de vérifier l'installation de Java, vous pouvez exécuter la commande suivante.
$ java -version

Quant à Scala, scala est un langage de programmation orienté objet et fonctionnel qui le combine en un seul concis. Scala est compatible à la fois avec l'environnement d'exécution javascript et la JVM, ce qui vous permet d'accéder facilement à l'écosystème des grandes bibliothèques, ce qui aide à créer un système haute performance. Exécutez la commande apt suivante pour installer scala.
$ sudo apt update
$ sudo apt install scala
Maintenant, vérifiez la version pour vérifier l'installation.
$ scala -version

Installation d'Apache Spark
Il n'y a pas de référentiel apt officiel pour installer apache-spark mais vous pouvez pré-compiler le binaire à partir du site officiel. Utilisez la commande wget et le lien suivants pour télécharger le fichier binaire.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Maintenant, extrayez le fichier binaire téléchargé à l'aide de la commande tar suivante.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Enfin, déplacez les fichiers spark extraits vers le répertoire /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Configuration des variables d'environnement
Votre variable de chemin pour spark dans votre .profile dans le fichier nécessaire pour que la commande fonctionne sans chemin complet, vous pouvez le faire en utilisant la commande echo ou le faire manuellement en utilisant un éditeur de texte préférable. Pour un moyen plus simple, exécutez la commande echo suivante.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
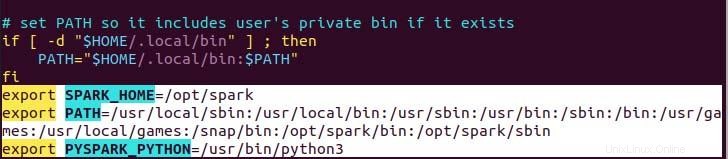
Comme vous pouvez le voir, la variable de chemin est ajoutée au bas du fichier .profile en utilisant echo avec>> opération.
Maintenant, exécutez la commande suivante pour appliquer les nouvelles modifications de variable d'environnement.
$ source ~/.profile
Déployer Apache Spark
Maintenant, nous avons configuré tout ce que nous pouvons exécuter le service maître ainsi que le service de travail à l'aide de la commande suivante.
$ start-master.sh
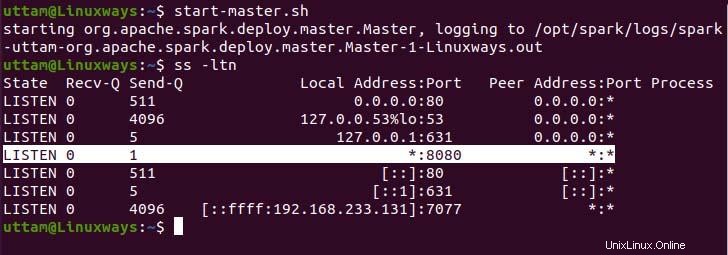
Comme vous pouvez le constater, notre service Spark Master s'exécute sur le port 8080. Si vous parcourez l'hôte local sur le port 8080, le port par défaut de Spark. Vous pouvez rencontrer le type d'interface utilisateur suivant lorsque vous parcourez l'URL. Vous ne trouverez peut-être aucun processeur de travail en cours d'exécution en démarrant uniquement le service maître. Lorsque vous démarrez le service de travail, vous trouverez un nouveau nœud répertorié comme dans l'exemple suivant.
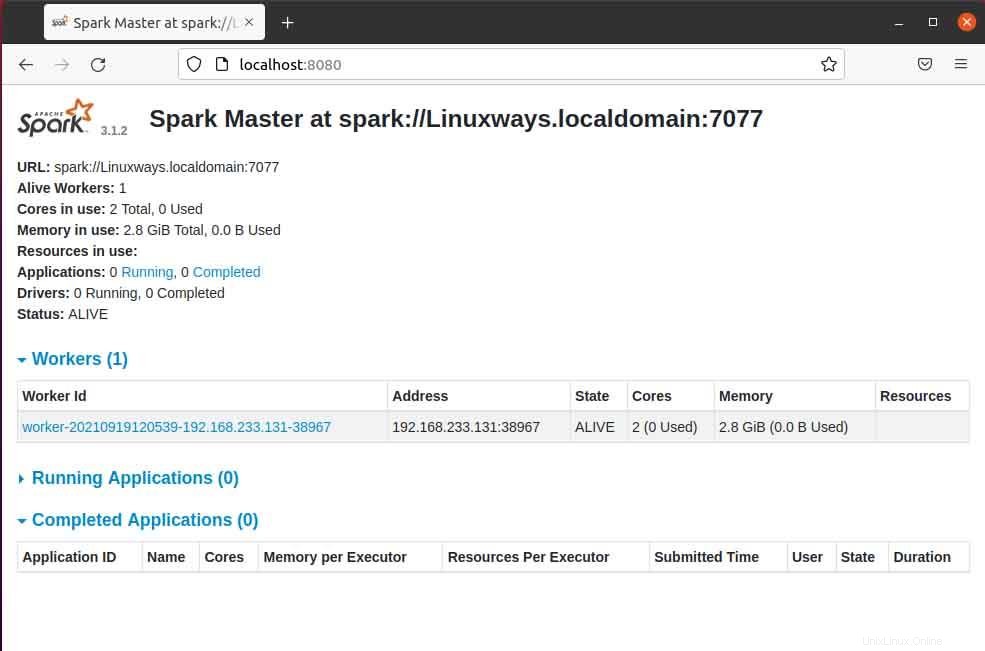
Lorsque vous ouvrez la page maître dans le navigateur, vous pouvez voir l'URL spark master spark://HOST:PORT qui est utilisée pour connecter les services de travail via cet hôte. Pour mon hôte actuel, mon URL principale Spark est spark://Linuxways.localdomain:7077, vous devez donc exécuter la commande de la manière suivante pour démarrer le processus de travail.
$ start-workers.sh <spark-master-url>
Pour exécuter la commande suivante pour exécuter les services de travail.
$ start-workers.sh spark://Linuxways.localdomain:7077

Vous pouvez également utiliser spark-shell en exécutant la commande suivante.
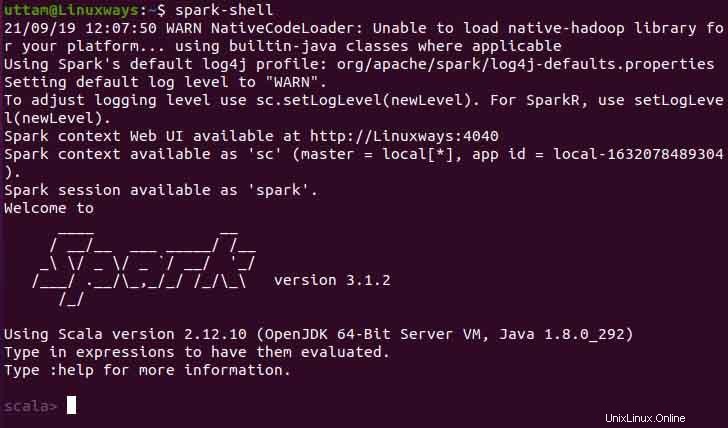
$ spark-shell
Conclusion
J'espère que cet article vous apprendra comment installer et configurer Apache Spark sur Ubuntu. Dans cet article, j'ai essayé de rendre le processus aussi compréhensible que possible.