Présentation
Apache Spark est un cadre de calcul open-source distribué qui est_créé pour fournir des résultats de calcul plus rapides.
Il s'agit d'un moteur de calcul en mémoire, ce qui signifie que les données seront traitées en mémoire.
Étincelle prend en charge diverses API pour le streaming, le traitement de graphes, SQL, MLLib. Il prend également en charge Java, Python, Scala et R comme langages préférés. Spark est principalement installé dans les clusters Hadoop, mais vous pouvez également installer et configurer Spark en mode autonome.
Dans cet article, nous allons voir comment installer Apache Spark dans Debian et Ubuntu distributions basées sur .
Installer Java dans Ubuntu
Pour installer Apache Spark dans Ubuntu, vous devez avoir Java installé sur votre machine. La plupart des distributions modernes sont livrées avec Java installé par défaut et vous pouvez le vérifier à l'aide de la commande suivante.
$ java -version
S'il n'y a pas de sortie, vous pouvez installer Java à l'aide de notre article sur l'installation de Java sur Ubuntu ou simplement exécuter les commandes suivantes pour installer Java sur les distributions basées sur Ubuntu et Debian.
$ sudo apt update
$ sudo apt install default-jre
$ java -versionInstaller Scala dans Ubuntu
Ensuite, vous pouvez installer Scala depuis le référentiel apt en exécutant les commandes suivantes pour rechercher scala et l'installer.
Rechercher le colis
$ sudo apt search scalaInstallez le paquet
$ sudo apt install scala -yPour vérifier l'installation de Scala , exécutez la commande suivante.
$ scala -version 
Installer Apache Spark dans Ubuntu
Allez maintenant sur la page de téléchargement officielle d'Apache Spark et récupérez la dernière version (c'est-à-dire 3.1.2) au moment de la rédaction de cet article. Vous pouvez également utiliser la commande wget pour télécharger le fichier directement dans le terminal.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Ouvrez maintenant votre terminal et basculez vers l'emplacement de votre fichier téléchargé et exécutez la commande suivante pour extraire le fichier tar Apache Spark.
$ tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz 
Enfin, déplacez le Spark extrait répertoire vers /opt répertoire.
sudo mv spark-3.1.2-bin-hadoop3.2 /opt/sparkConfigurer les variables pour Spark
Vous devez maintenant définir quelques variables d'environnement dans votre .profile fichier avant de démarrer l'étincelle.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profilePour vous assurer que ces nouvelles variables d'environnement sont accessibles dans le shell et disponibles pour Apache Spark, il est également obligatoire d'exécuter la commande suivante pour que les modifications récentes prennent effet.
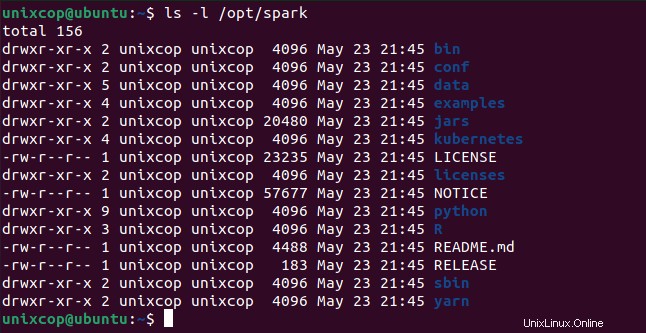
$ source ~/.profileTous les binaires liés à Spark pour démarrer et arrêter les services se trouvent sous le sbin dossier.
$ ls -l /opt/spark
Démarrer Apache Spark dans Ubuntu
Exécutez la commande suivante pour démarrer le Spark service maître et service esclave.
$ start-master.sh
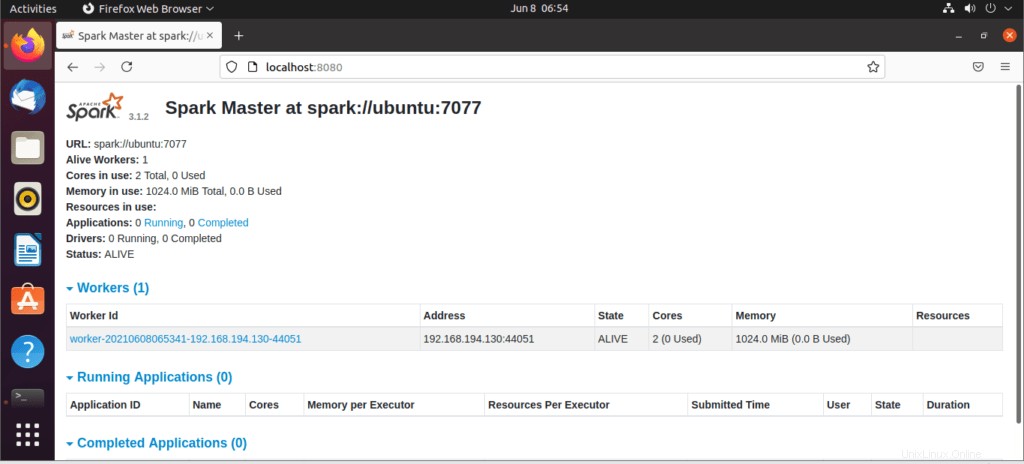
Une fois le service démarré, accédez au navigateur et tapez la page d'étincelle d'accès à l'URL suivante. À partir de la page, vous pouvez voir que mon service principal est démarré.
http://localhost:8080/Ensuite vous pouvez ajouter un worker avec cette commande :
$ start-workers.sh spark://localhost:7077
Le travailleur sera ajouté comme indiqué :
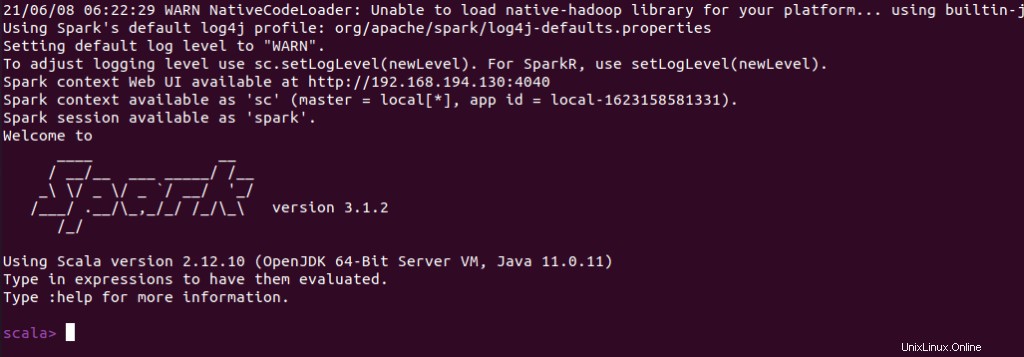
Vous pouvez également vérifier si spark-shell fonctionne bien en lançant le spark-shell commande.
$ spark-shell