
Dans ce didacticiel, nous allons vous montrer comment installer Apache Spark sur Ubuntu 20.04 LTS. Pour ceux d'entre vous qui ne le savaient pas, Apache Spark est un système informatique de cluster rapide et polyvalent . Il fournit des API de haut niveau en Java, Scala et Python, ainsi qu'un moteur optimisé qui prend en charge les graphiques d'exécution globaux. Il prend également en charge un riche ensemble d'outils de niveau supérieur, notamment Spark SQL pour SQL et le traitement des informations structurées, MLlib pour la machine l'apprentissage, GraphX pour le traitement des graphes et Spark Streaming.
Cet article suppose que vous avez au moins des connaissances de base sur Linux, que vous savez utiliser le shell et, plus important encore, que vous hébergez votre site sur votre propre VPS. L'installation est assez simple et suppose que vous s'exécutent dans le compte root, sinon vous devrez peut-être ajouter 'sudo ‘ aux commandes pour obtenir les privilèges root. Je vais vous montrer pas à pas l'installation d'Apache Spark sur un serveur 20.04 LTS (Focal Fossa). Vous pouvez suivre les mêmes instructions pour Ubuntu 18.04, 16.04 et toute autre distribution basée sur Debian comme Linux Mint.
Prérequis
- Un serveur exécutant l'un des systèmes d'exploitation suivants :Ubuntu 20.04, 18.04, 16.04 et toute autre distribution basée sur Debian comme Linux Mint.
- Il est recommandé d'utiliser une nouvelle installation du système d'exploitation pour éviter tout problème potentiel.
- Un
non-root sudo userou l'accès à l'root user. Nous vous recommandons d'agir en tant qu'non-root sudo user, cependant, car vous pouvez endommager votre système si vous ne faites pas attention lorsque vous agissez en tant que root.
Installer Apache Spark sur Ubuntu 20.04 LTS Focal Fossa
Étape 1. Tout d'abord, assurez-vous que tous vos packages système sont à jour en exécutant le apt suivant commandes dans le terminal.
sudo apt update sudo apt upgrade
Étape 2. Installation de Java.
Apache Spark nécessite Java pour s'exécuter, assurons-nous que Java est installé sur notre système Ubuntu :
sudo apt install default-jdk
Nous vérifions la version Java, par la ligne de commande ci-dessous :
java -version
Étape 3. Téléchargez et installez Apache Spark.
Téléchargez la dernière version d'Apache Spark depuis la page de téléchargement :
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.0.0/spark-3.0.0-bin-hadoop2.7.tgz tar xvzf spark-3.0.0-bin-hadoop2.7.tgz sudo mv spark-3.0.0-bin-hadoop2.7/ /opt/spark
Ensuite, configuration de l'environnement Apache Spark :
nano ~/.bashrc
Ensuite, ajoutez ces lignes à la fin du fichier .bashrc afin que le chemin puisse contenir le chemin du fichier exécutable Spark :
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Activez les modifications :
source ~/.bashrc
Étape 4. Démarrez le serveur maître Spark autonome.
Maintenant que vous avez terminé la configuration de votre environnement pour Spark, vous pouvez démarrer un serveur maître :
start-master.sh
Pour afficher l'interface utilisateur Spark Web, ouvrez un navigateur Web et entrez l'adresse IP localhost sur le port 8080 :
http://127.0.0.1:8080/
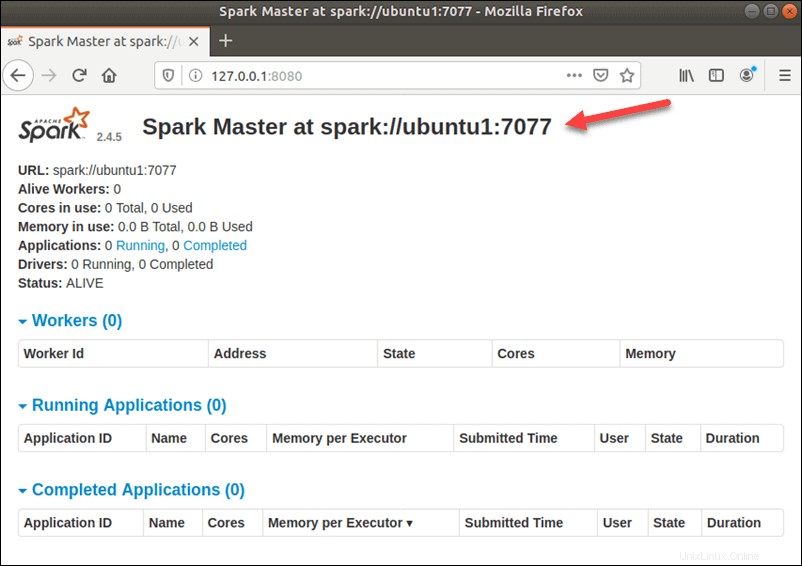
Dans cette configuration autonome à serveur unique, nous allons démarrer un serveur esclave avec le serveur maître. Le start-slave.sh La commande est utilisée pour démarrer le processus de travail Spark :
start-slave.sh spark://ubuntu1:7077
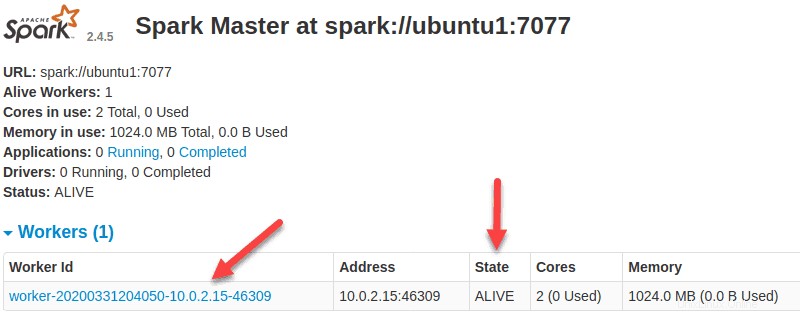
Maintenant qu'un travailleur est opérationnel, si vous rechargez l'interface utilisateur Web de Spark Master, vous devriez le voir dans la liste :
Après cela, terminez la configuration et démarrez le serveur maître et esclave, testez si le shell Spark fonctionne :
spark-shell
Félicitations ! Vous avez installé Apache Spark avec succès. Merci d'avoir utilisé ce didacticiel pour installer Apache Spark sur le système Ubuntu 20.04 (Focal Fossa). Pour obtenir de l'aide supplémentaire ou des informations utiles, nous vous recommandons de consulter le Site Web Apache Spark.