Présentation
Apache Spark est un framework utilisé dans les environnements informatiques en cluster pour analyser le Big Data . Cette plate-forme est devenue très populaire en raison de sa facilité d'utilisation et de l'amélioration de la vitesse de traitement des données par rapport à Hadoop.
Apache Spark est capable de répartir une charge de travail sur un groupe d'ordinateurs dans un cluster pour traiter plus efficacement de grands ensembles de données. Ce moteur open source prend en charge un large éventail de langages de programmation. Cela inclut Java, Scala, Python et R.
Dans ce tutoriel, vous apprendrez comment installer Spark sur une machine Ubuntu . Le guide vous montrera comment démarrer un serveur maître et esclave et comment charger les shells Scala et Python. Il fournit également les commandes Spark les plus importantes.

Prérequis
- Un système Ubuntu.
- Accès à un terminal ou à une ligne de commande.
- Un utilisateur avec sudo ou root autorisations.
Installer les packages requis pour Spark
Avant de télécharger et de configurer Spark, vous devez installer les dépendances nécessaires. Cette étape inclut l'installation des packages suivants :
- JDK
- Échelle
- Git
Ouvrez une fenêtre de terminal et exécutez la commande suivante pour installer les trois packages en même temps :
sudo apt install default-jdk scala git -yVous verrez quels packages seront installés.
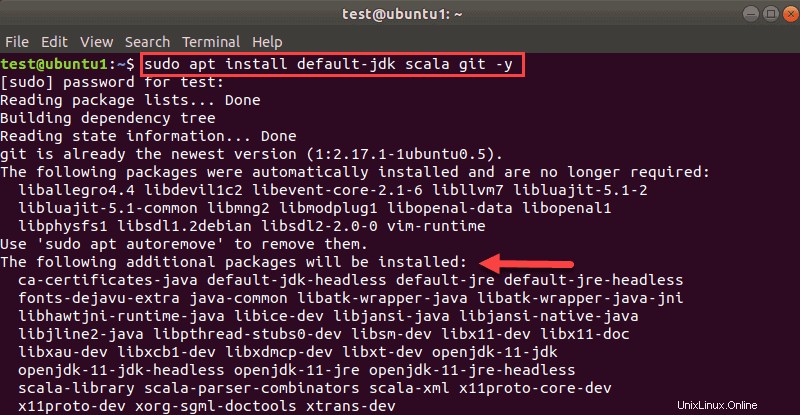
Une fois le processus terminé, vérifiez les dépendances installées en exécutant ces commandes :
java -version; javac -version; scala -version; git --version
La sortie imprime les versions si l'installation s'est terminée avec succès pour tous les packages.
Télécharger et configurer Spark sur Ubuntu
Maintenant, vous devez télécharger la version de Spark que vous voulez forment leur site Web. Nous allons opter pour Spark 3.0.1 avec Hadoop 2.7 car il s'agit de la dernière version au moment de la rédaction de cet article.
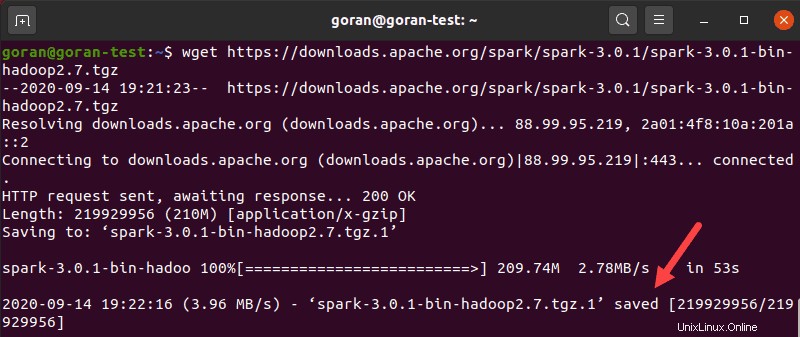
Utilisez le wget commande et le lien direct pour télécharger l'archive Spark :
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzUne fois le téléchargement terminé, vous verrez l'élément sauvegardé message.
Maintenant, extrayez l'archive enregistrée à l'aide de tar :
tar xvf spark-*Laissez le processus se terminer. La sortie montre les fichiers en cours de décompression de l'archive.
Enfin, déplacez le répertoire décompressé spark-3.0.1-bin-hadoop2.7 à l' opt/spark répertoire.
Utilisez le mv commande pour le faire :
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkLe terminal ne renvoie aucune réponse s'il déplace avec succès le répertoire. Si vous saisissez mal le nom, vous obtiendrez un message semblable à :
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Configurer l'environnement Spark
Avant de démarrer un serveur maître, vous devez configurer les variables d'environnement. Il y a quelques chemins d'accès Spark home que vous devez ajouter au profil utilisateur.
Utilisez l'echo commande pour ajouter ces trois lignes à .profile :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileVous pouvez également ajouter les chemins d'exportation en modifiant le .profile fichier dans l'éditeur de votre choix, tel que nano ou vim.
Par exemple, pour utiliser nano, saisissez :
nano .profileLorsque le profil se charge, faites défiler jusqu'au bas du fichier.
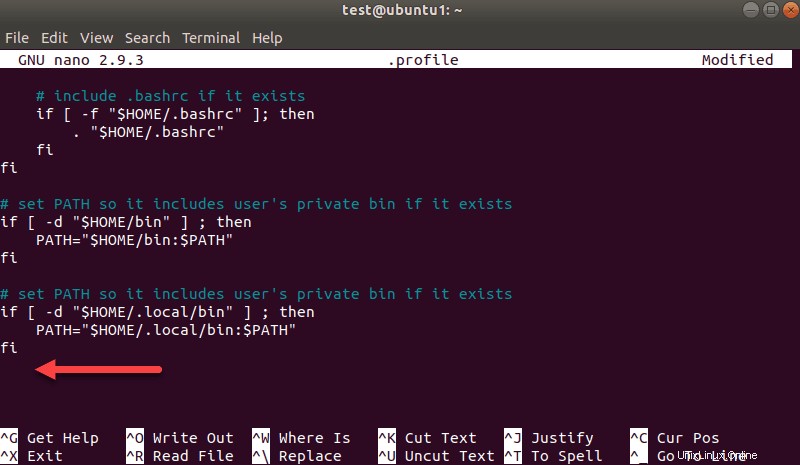
Ajoutez ensuite ces trois lignes :
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Quittez et enregistrez les modifications lorsque vous y êtes invité.
Lorsque vous avez terminé d'ajouter les chemins, chargez le .profile fichier dans la ligne de commande en tapant :
source ~/.profileDémarrer le serveur maître Spark autonome
Maintenant que vous avez terminé la configuration de votre environnement pour Spark, vous pouvez démarrer un serveur maître.
Dans le terminal, tapez :
start-master.shPour afficher l'interface utilisateur Spark Web, ouvrez un navigateur Web et entrez l'adresse IP de l'hôte local sur le port 8080.
http://127.0.0.1:8080/La page affiche votre URL Spark , informations sur l'état des travailleurs, utilisation des ressources matérielles, etc.
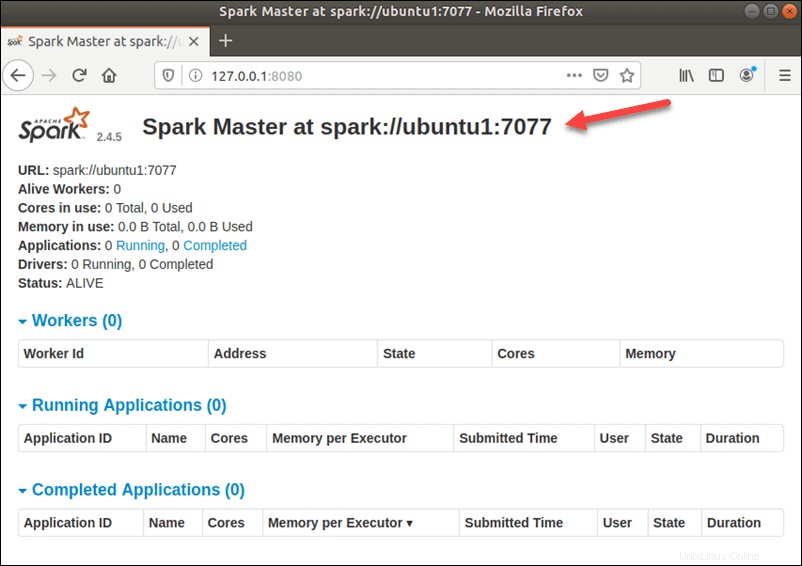
L'URL de Spark Master est le nom de votre appareil sur le port 8080. Dans notre cas, il s'agit de ubuntu1:8080 . Ainsi, il existe trois façons possibles de charger l'interface utilisateur Web de Spark Master :
- 127.0.0.1:8080
- localhost :8080
- NomAppareil :8080
Démarrer le serveur esclave Spark (démarrer un processus de travail)
Dans cette configuration autonome à serveur unique, nous allons démarrer un serveur esclave avec le serveur maître.
Pour ce faire, exécutez la commande suivante dans ce format :
start-slave.sh spark://master:port
Le master dans la commande peut être une adresse IP ou un nom d'hôte.
Dans notre cas, il s'agit de ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Maintenant qu'un travailleur est opérationnel, si vous rechargez l'interface utilisateur Web de Spark Master, vous devriez le voir dans la liste :
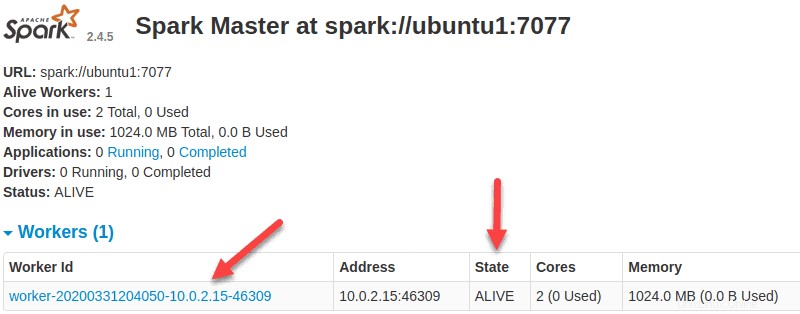
Spécifier l'allocation des ressources pour les travailleurs
Le paramètre par défaut lors du démarrage d'un travailleur sur une machine consiste à utiliser tous les cœurs de processeur disponibles. Vous pouvez spécifier le nombre de cœurs en passant le -c flag au start-slave commande.
Par exemple, pour démarrer un nœud de calcul et n'attribuer qu'un seul cœur de processeur pour cela, entrez cette commande :
start-slave.sh -c 1 spark://ubuntu1:7077Rechargez l'interface utilisateur Web de Spark Master pour confirmer la configuration du travailleur.

De même, vous pouvez affecter une quantité spécifique de mémoire lors du démarrage d'un travailleur. Le paramètre par défaut consiste à utiliser la quantité de RAM dont dispose votre ordinateur, moins 1 Go.
Pour démarrer un nœud de calcul et lui attribuer une quantité de mémoire spécifique, ajoutez le -m option et un numéro. Pour les gigaoctets, utilisez G et pour les mégaoctets, utilisez M .
Par exemple, pour démarrer un nœud de calcul avec 512 Mo de mémoire, entrez cette commande :
start-slave.sh -m 512M spark://ubuntu1:7077Rechargez l'interface utilisateur Web Spark Master pour afficher le statut du travailleur et confirmer la configuration.

Tester la coque d'étincelle
Après avoir terminé la configuration et démarré le serveur maître et esclave, testez si le shell Spark fonctionne.
Chargez le shell en saisissant :
spark-shellVous devriez obtenir un écran avec des notifications et des informations Spark. Scala est l'interface par défaut, de sorte que le shell se charge lorsque vous exécutez spark-shell .
La fin de la sortie ressemble à ceci pour la version que nous utilisons au moment de la rédaction de ce guide :
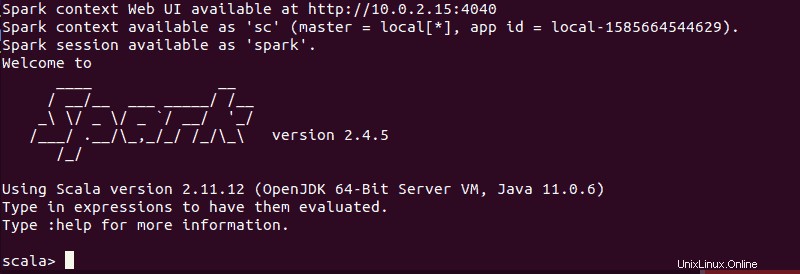
Tapez :q et appuyez sur Entrée pour quitter Scala.
Tester Python dans Spark
Si vous ne souhaitez pas utiliser l'interface Scala par défaut, vous pouvez passer à Python.
Assurez-vous de quitter Scala, puis exécutez cette commande :
pysparkLa sortie résultante ressemble à la précédente. Vers le bas, vous verrez la version de Python.
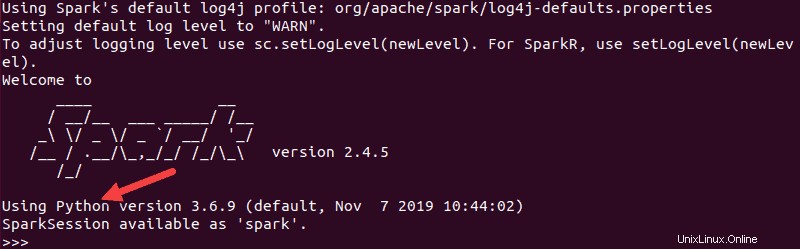
Pour quitter ce shell, tapez quit() et appuyez sur Entrée .
Commandes de base pour démarrer et arrêter le serveur maître et les nœuds de calcul
Vous trouverez ci-dessous les commandes de base pour démarrer et arrêter le serveur maître et les nœuds de calcul Apache Spark. Étant donné que cette configuration ne concerne qu'une seule machine, les scripts que vous exécutez par défaut sur l'hôte local.
Pour commencer un maître serveur instance sur la machine actuelle, exécutez la commande que nous avons utilisée précédemment dans le guide :
start-master.shPour arrêter le maître instance démarrée en exécutant le script ci-dessus, exécutez :
stop-master.shPour arrêter un nœud de calcul en cours d'exécution processus, entrez cette commande :
stop-slave.shLa page Spark Master, dans ce cas, affiche le statut du travailleur comme MORT.

Vous pouvez démarrer à la fois le maître et le serveur instances en utilisant la commande start-all :
start-all.shDe même, vous pouvez arrêter toutes les instances en utilisant la commande suivante :
stop-all.sh