Présentation
Apache Storm et Spark sont des plates-formes de traitement de données volumineuses qui fonctionnent avec des flux de données en temps réel. La principale différence entre les deux technologies réside dans la manière dont elles gèrent le traitement des données. Storm parallélise le calcul des tâches tandis que Spark parallélise les calculs de données. Cependant, il existe d'autres différences fondamentales entre les API.
Cet article fournit une comparaison approfondie entre Apache Storm et Spark Streaming.

Orage contre étincelle :définitions
Tempête Apache est un framework de traitement de flux en temps réel. Le Trident La couche d'abstraction fournit à Storm une interface alternative, ajoutant des opérations d'analyse en temps réel.
D'autre part, Apache Spark est un cadre d'analyse à usage général pour les données à grande échelle. L'API Spark Streaming est disponible pour diffuser des données en temps quasi réel, aux côtés d'autres outils d'analyse dans le cadre.
Storm vs Spark :Comparaison
Storm et Spark sont des projets Apache gratuits et open source avec une intention similaire. Le tableau ci-dessous présente la principale différence entre les deux technologies :
| Tempête | Étincelle | |
|---|---|---|
| Langages de programmation | Intégration multilingue | Prise en charge de Python, R, Java, Scala |
| Modèle de traitement | Traitement de flux avec micro-batch disponible via Trident | Traitement par lots avec micro-lots disponible via Streaming |
| Primitives | Flux de tuple Lot de tuples Partitionner | DStream |
| Fiabilité | Exactement une fois (Trident) Au moins une fois Au plus une fois | Exactement une fois |
| Tolérance aux pannes | Redémarrage automatique par le processus superviseur | Redémarrage du travailleur via les gestionnaires de ressources |
| Gestion des états | Prise en charge via Trident | Prise en charge via le streaming |
| Facilité d'utilisation | Plus difficile à exploiter et à déployer | Plus facile à gérer et à déployer |
Langages de programmation
La disponibilité de l'intégration avec d'autres langages de programmation est l'un des principaux facteurs lors du choix entre Storm et Spark et l'une des principales différences entre les deux technologies.
Orage
Storm a un multilingue fonctionnalité, ce qui le rend disponible pour pratiquement tous les langages de programmation. L'API Trident pour le streaming et le traitement est compatible avec :
- Java
- Clojure
- Échelle
Étincelle
Spark fournit des API de streaming de haut niveau pour les langages suivants :
- Java
- Échelle
- Python
Certaines fonctionnalités avancées, telles que la diffusion en continu à partir de sources personnalisées, ne sont pas disponibles pour Python. Cependant, le streaming à partir de sources externes avancées telles que Kafka ou Kinesis est disponible pour les trois langues.
Modèle de traitement
Le modèle de traitement définit la façon dont le flux de données est actualisé. Les informations sont traitées de l'une des manières suivantes :
- Un enregistrement à la fois.
- En lots discrétisés.
Orage
Le modèle de traitement du noyau Storm fonctionne directement sur les flux de tuples, un enregistrement à la fois , ce qui en fait une véritable technologie de streaming en temps réel. L'API Trident ajoute la possibilité d'utiliser des micro-lots .
Étincelle
Le modèle de traitement Spark divise les données en lots , regroupant les enregistrements avant un traitement ultérieur. L'API Spark Streaming offre la possibilité de diviser les données en micro-lots .
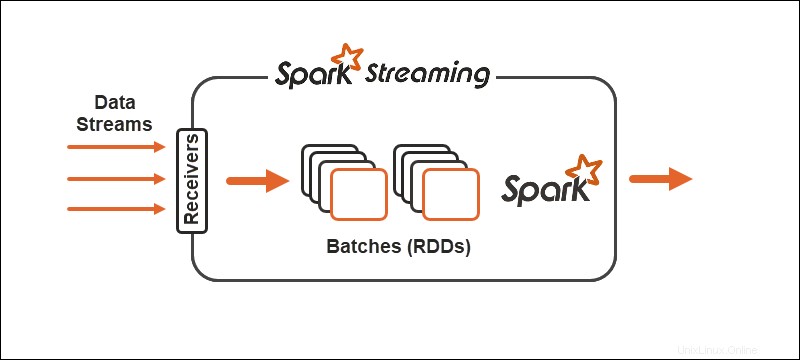
Primitives
Les primitives représentent les blocs de construction de base des deux technologies et la manière dont les opérations de transformation s'exécutent sur les données.
Orage
Core Storm fonctionne sur des tuple streams , tandis que Trident fonctionne sur des lots de tuples et partitions . L'API Trident fonctionne sur les collections de la même manière que les abstractions de haut niveau pour Hadoop. Les principales primitives de Storm sont :
- Becs qui génèrent un flux en temps réel à partir d'une source.
- Boulons qui effectuent le traitement des données et conservent la persistance.
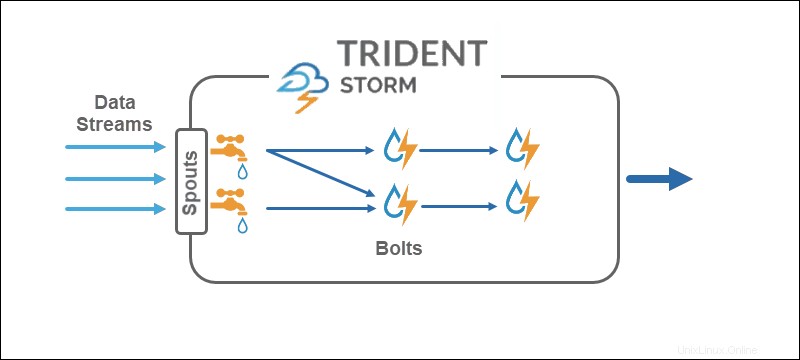
Dans la topologie Trident, les opérations sont regroupées en boulons. Les regroupements, les jointures, les agrégations, les fonctions d'exécution et les filtres sont disponibles sur des lots isolés et sur différentes collections. L'agrégation stocke de manière persistante en mémoire soutenue par HDFS ou dans un autre magasin comme Cassandra.
Étincelle
Avec Spark Streaming, le flux continu de données se divise en flux discrétisés (DStreams), une séquence de bases de données distribuées résilientes (RDD).
Spark autorise deux types généraux d'opérateurs sur les primitives :
1. Opérateurs de transformation de flux où un DStream se transforme en un autre DStream.
2. Opérateurs de sortie aider à écrire des informations sur des systèmes externes.
Fiabilité
La fiabilité fait référence à l'assurance de la livraison des données. Il y a trois garanties possibles en matière de fiabilité des flux de données :
- Au moins une fois . Les données ne sont livrées qu'une seule fois, plusieurs livraisons étant également possibles.
- Au plus une fois . Les données ne sont livrées qu'une seule fois et les doublons disparaissent. Il est possible que les données n'arrivent pas.
- Exactement une fois . Les données sont livrées une seule fois, sans pertes ni doublons. L'option de garantie est optimale pour le streaming de données, bien que difficile à atteindre.
Orage
Storm est flexible en ce qui concerne la fiabilité du streaming de données. À la base, au moins une fois et au plus une fois options sont possibles. Avec l'API Trident, les trois configurations sont disponibles .
Étincelle
Spark essaie d'emprunter l'itinéraire optimal en se concentrant sur exactement une fois configuration du flux de données. Si un travailleur ou un conducteur échoue, au moins une fois la sémantique s'applique.
Tolérance aux pannes
La tolérance aux pannes définit le comportement des technologies de streaming en cas de panne. Spark et Storm sont tolérants aux pannes à un niveau similaire.
Étincelle
En cas d'échec du nœud de calcul, Spark redémarre les nœuds de calcul via le gestionnaire de ressources, tel que YARN. L'échec du pilote utilise un point de contrôle des données pour la récupération.
Orage
Si un processus échoue dans Storm ou Trident, le processus de supervision gère automatiquement le redémarrage. ZooKeeper joue un rôle crucial dans la récupération et la gestion de l'état.
Gestion des états
Spark Streaming et Storm Trident disposent tous deux de technologies de gestion d'état intégrées. Le suivi des états aide à atteindre la tolérance aux pannes ainsi que la garantie de livraison unique.
Facilité d'utilisation et de développement
La facilité d'utilisation et de développement dépend de la qualité de la documentation de la technologie et de la facilité d'exploitation des flux.
Étincelle
Spark est plus facile à déployer et à développer à partir des deux technologies. Le streaming est bien documenté et se déploie sur les clusters Spark. Les tâches de flux sont interchangeables avec les tâches par lots.
Orage
Storm est un peu plus délicat à configurer et à développer car il contient une dépendance au cluster ZooKeeper. L'avantage lors de l'utilisation de Storm est dû à la fonctionnalité multilingue.
Storm contre Spark :comment choisir ?
Le choix entre Storm et Spark dépend du projet ainsi que des technologies disponibles. L'un des principaux facteurs est le langage de programmation et les garanties de fiabilité de la livraison des données.
Bien qu'il existe des différences entre les deux flux de données et le traitement, la meilleure voie à suivre consiste à tester les deux technologies pour voir ce qui fonctionne le mieux pour vous et le flux de données à portée de main.