Présentation
Aujourd'hui, nous avons de nombreuses solutions gratuites pour le traitement du Big Data. De nombreuses entreprises proposent également des fonctionnalités d'entreprise spécialisées pour compléter les plates-formes open source.
La tendance a commencé en 1999 avec le développement d'Apache Lucene. Le framework est rapidement devenu open-source et a conduit à la création de Hadoop. Deux des frameworks de traitement de Big Data les plus populaires utilisés aujourd'hui sont open source :Apache Hadoop et Apache Spark.
On se demande toujours quel framework utiliser, Hadoop ou Spark.
Dans cet article, découvrez différences clés entre Hadoop et Spark et quand choisir l'un ou l'autre, ou les utiliser ensemble.

Remarque :Avant de plonger dans la comparaison directe entre Hadoop et Spark, nous allons jeter un bref coup d'œil à ces deux frameworks.
Qu'est-ce qu'Hadoop ?
Apache Hadoop est une plate-forme qui gère de grands ensembles de données de manière distribuée. Le framework utilise MapReduce pour diviser les données en blocs et affecter les morceaux aux nœuds d'un cluster. MapReduce traite ensuite les données en parallèle sur chaque nœud pour produire une sortie unique.
Chaque machine d'un cluster stocke et traite les données. Hadoop stocke les données sur des disques à l'aide de HDFS . Le logiciel offre des options d'évolutivité transparentes. Vous pouvez commencer avec une seule machine, puis passer à des milliers, en ajoutant n'importe quel type de matériel d'entreprise ou de base.
L'écosystème Hadoop est hautement tolérant aux pannes. Hadoop ne dépend pas du matériel pour atteindre une haute disponibilité. À la base, Hadoop est conçu pour rechercher les défaillances au niveau de la couche application. En répliquant les données sur un cluster, lorsqu'un élément matériel tombe en panne, le framework peut créer les parties manquantes à partir d'un autre emplacement.
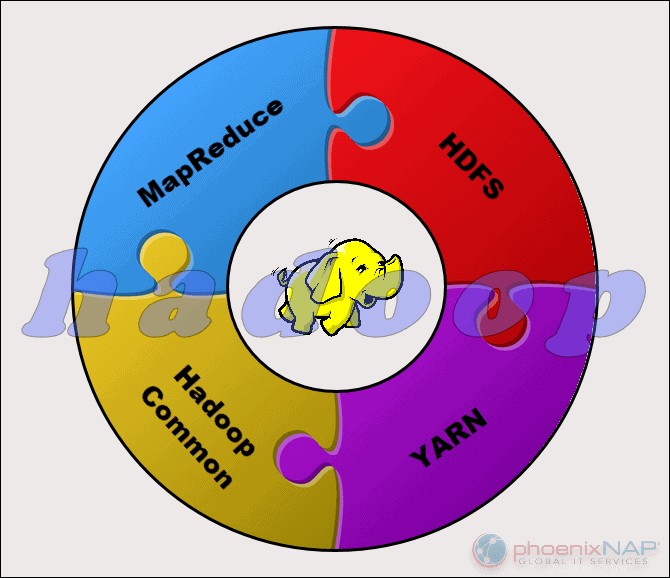
Le projet Apache Hadoop se compose de quatre modules principaux :
- HDFS – Système de fichiers distribué Hadoop. Il s'agit du système de fichiers qui gère le stockage de grands ensembles de données sur un cluster Hadoop. HDFS peut gérer à la fois des données structurées et non structurées. Le matériel de stockage peut aller de n'importe quel disque dur grand public aux disques d'entreprise.
- MapReduce. Le composant de traitement de l'écosystème Hadoop. Il affecte les fragments de données du HDFS à des tâches de mappage distinctes dans le cluster. MapReduce traite les morceaux en parallèle pour combiner les morceaux dans le résultat souhaité.
- FIL. Encore un autre négociateur de ressources. Responsable de la gestion des ressources informatiques et de la planification des tâches.
- Hadoop commun. L'ensemble des bibliothèques et utilitaires communs dont dépendent les autres modules. Un autre nom pour ce module est Hadoop core, car il prend en charge tous les autres composants Hadoop.
La nature de Hadoop le rend accessible à tous ceux qui en ont besoin. La communauté open source est vaste et a ouvert la voie au traitement accessible du Big Data.
Qu'est-ce que Spark ?
Apache Spark est un outil open source. Ce framework peut s'exécuter en mode autonome ou sur un gestionnaire de cloud ou de cluster tel qu'Apache Mesos et d'autres plates-formes. Il est conçu pour des performances rapides et utilise de la RAM pour la mise en cache et le traitement des données.
Spark exécute différents types de charges de travail Big Data. Cela inclut le traitement par lots de type MapReduce, ainsi que le traitement de flux en temps réel, l'apprentissage automatique, le calcul de graphes et les requêtes interactives. Avec des API de haut niveau faciles à utiliser, Spark peut s'intégrer à de nombreuses bibliothèques différentes, y compris PyTorch et TensorFlow. Pour connaître la différence entre ces deux bibliothèques, consultez notre article sur PyTorch et TensorFlow.
Le moteur Spark a été créé pour améliorer l'efficacité de MapReduce et conserver ses avantages. Même si Spark n'a pas son système de fichiers, il peut accéder aux données sur de nombreuses solutions de stockage différentes. La structure de données utilisée par Spark s'appelle Resilient Distributed Dataset , ou RDD.
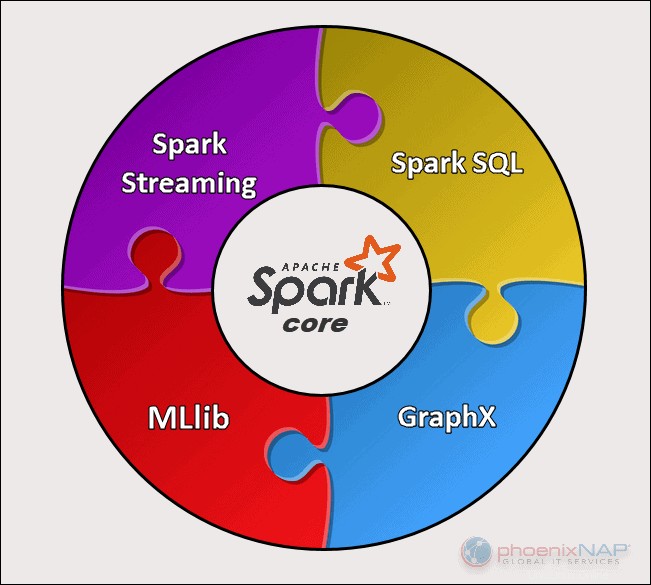
Il existe cinq composants principaux d'Apache Spark :
- Apache Spark Core . La base de tout le projet. Spark Core est responsable des fonctions nécessaires telles que la planification, la répartition des tâches, les opérations d'entrée et de sortie, la récupération des pannes, etc. D'autres fonctionnalités sont construites par-dessus.
- Diffusion Spark. Ce composant permet le traitement des flux de données en direct. Les données peuvent provenir de nombreuses sources différentes, notamment Kafka, Kinesis, Flume, etc.
- Spark SQL . Spark utilise ce composant pour collecter des informations sur les données structurées et sur la manière dont les données sont traitées.
- Bibliothèque d'apprentissage automatique (MLlib) . Cette bibliothèque se compose de nombreux algorithmes d'apprentissage automatique. L'objectif de MLlib est d'évoluer et de rendre l'apprentissage automatique plus accessible.
- GraphX . Ensemble d'API utilisées pour faciliter les tâches d'analyse de graphes.
Différences clés entre Hadoop et Spark
Les sections suivantes décrivent les principales différences et similitudes entre les deux cadres. Nous examinerons Hadoop contre Spark sous plusieurs angles.
Certains d'entre eux sont coût , performances , sécurité , et facilité d'utilisation .
Le tableau ci-dessous donne un aperçu des conclusions tirées dans les sections suivantes.
Comparaison Hadoop et Spark
| Catégorie de comparaison | Hadoop | Étincelle |
| Performances | Performances plus lentes, utilise des disques pour le stockage et dépend de la vitesse de lecture et d'écriture du disque. | Performances en mémoire rapides avec des opérations de lecture et d'écriture sur disque réduites. |
| Coût | Une plate-forme open source, moins coûteuse à exécuter. Utilise du matériel grand public abordable. Trouver plus facilement des professionnels Hadoop formés. | Une plate-forme open source, mais s'appuie sur la mémoire pour le calcul, ce qui augmente considérablement les coûts de fonctionnement. |
| Traitement des données | Idéal pour le traitement par lots. Utilise MapReduce pour diviser un grand ensemble de données sur un cluster pour une analyse parallèle. | Convient pour l'analyse de données itérative et en direct. Fonctionne avec les RDD et les DAG pour exécuter des opérations. |
| Tolérance aux pannes | Un système hautement tolérant aux pannes. Réplique les données sur les nœuds et les utilise en cas de problème. | Suit le processus de création de bloc RDD, puis il peut reconstruire un ensemble de données lorsqu'une partition échoue. Spark peut également utiliser un DAG pour reconstruire les données sur les nœuds. |
| Évolutivité | Facilement évolutif en ajoutant des nœuds et des disques pour le stockage. Prend en charge des dizaines de milliers de nœuds sans limite connue. | Un peu plus difficile à mettre à l'échelle car il s'appuie sur la RAM pour les calculs. Prend en charge des milliers de nœuds dans un cluster. |
| Sécurité | Extrêmement sécurisé. Prend en charge LDAP, ACL, Kerberos, SLA, etc. | Non sécurisé. Par défaut, la sécurité est désactivée. S'appuie sur l'intégration avec Hadoop pour atteindre le niveau de sécurité nécessaire. |
| Facilité d'utilisation et Assistance linguistique | Plus difficile à utiliser avec des langues moins prises en charge. Utilise Java ou Python pour les applications MapReduce. | Plus convivial. Permet le mode shell interactif. Les API peuvent être écrites en Java, Scala, R, Python, Spark SQL. |
| Apprentissage automatique | Plus lent que Spark. Les fragments de données peuvent être trop volumineux et créer des goulots d'étranglement. Mahout est la bibliothèque principale. | Beaucoup plus rapide avec le traitement en mémoire. Utilise MLlib pour les calculs. |
| Planification et gestion des ressources | Utilise des solutions externes. YARN est l'option la plus courante pour la gestion des ressources. Oozie est disponible pour la planification des workflows. | Dispose d'outils intégrés pour l'allocation, la planification et la surveillance des ressources. |
Performances
Lorsque nous examinons Hadoop par rapport à Spark en termes de comment ils traitent les données , il peut ne pas sembler naturel de comparer les performances des deux frameworks. Néanmoins, nous pouvons tracer une ligne et obtenir une image claire de l'outil le plus rapide.
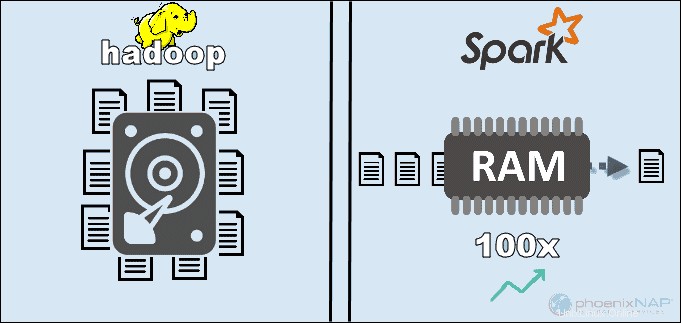
En accédant aux données stockées localement sur HDFS, Hadoop améliore les performances globales. Cependant, cela ne correspond pas au traitement en mémoire de Spark. Selon les affirmations d'Apache, Spark semble être 100 fois plus rapide lors de l'utilisation de la RAM pour le calcul que Hadoop avec MapReduce.
La domination est restée avec le tri des données sur des disques. Spark était 3 fois plus rapide et nécessitait 10 fois moins de nœuds pour traiter 100 To de données sur HDFS. Cette référence a été suffisante pour établir le record du monde en 2014.
La principale raison de cette suprématie de Spark est qu'il ne lit pas et n'écrit pas de données intermédiaires sur les disques mais utilise de la RAM. Hadoop stocke les données sur de nombreuses sources différentes, puis traite les données par lots à l'aide de MapReduce.
Tout ce qui précède peut positionner Spark comme le gagnant absolu. Cependant, si la taille des données est supérieure à la RAM disponible, Hadoop est le choix le plus logique. Un autre point à prendre en compte est le coût de fonctionnement de ces systèmes.
Coût
En comparant Hadoop à Spark en gardant à l'esprit le coût, nous devons creuser plus loin que le prix du logiciel. Les deux plates-formes sont open-source et totalement gratuit. Néanmoins, les coûts d'infrastructure, de maintenance et de développement doivent être pris en compte pour obtenir un coût total de possession (TCO) approximatif.
Le facteur le plus important dans la catégorie des coûts est le matériel sous-jacent dont vous avez besoin pour exécuter ces outils. Étant donné que Hadoop s'appuie sur n'importe quel type de stockage sur disque pour le traitement des données, le coût de fonctionnement est relativement faible.
D'autre part, Spark dépend des calculs en mémoire pour le traitement des données en temps réel. Ainsi, faire tourner des nœuds avec beaucoup de RAM augmente considérablement le coût de possession.
Une autre préoccupation est le développement d'applications. Hadoop existe depuis plus longtemps que Spark et il est moins difficile de trouver des développeurs de logiciels.
Les points ci-dessus suggèrent que l'infrastructure Hadoop est plus rentable . Bien que cette affirmation soit correcte, nous devons nous rappeler que Spark traite les données beaucoup plus rapidement. Par conséquent, il faut un plus petit nombre de machines pour effectuer la même tâche.
Traitement des données
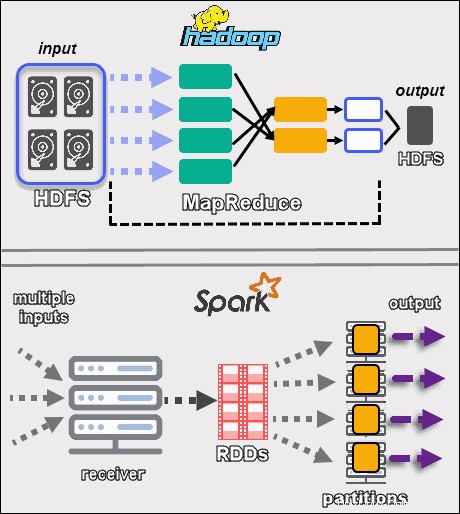
Les deux frameworks gèrent les données de manière assez différente . Bien que Hadoop avec MapReduce et Spark avec RDD traitent les données dans un environnement distribué, Hadoop est plus adapté au traitement par lots. En revanche, Spark brille par son traitement en temps réel.
L'objectif de Hadoop est de stocker des données sur des disques, puis de les analyser en parallèle par lots dans un environnement distribué. MapReduce ne nécessite pas une grande quantité de RAM pour gérer de gros volumes de données. Hadoop s'appuie sur du matériel de tous les jours pour le stockage et convient mieux au traitement linéaire des données.
Apache Spark fonctionne avecdes ensembles de données distribués résilients (RDD ). Un RDD est un ensemble distribué d'éléments stockés dans des partitions sur des nœuds du cluster. La taille d'un RDD est généralement trop grande pour être gérée par un nœud. Par conséquent, Spark partitionne les RDD sur les nœuds les plus proches et effectue les opérations en parallèle. Le système suit toutes les actions effectuées sur un RDD à l'aide d'un Graphique Acyclique Dirigé (DAG ).
Grâce aux calculs en mémoire et aux API de haut niveau, Spark gère efficacement les flux en direct de données non structurées. De plus, les données sont stockées dans un nombre prédéfini de partitions. Un nœud peut avoir autant de partitions que nécessaire, mais une partition ne peut pas s'étendre à un autre nœud.
Tolérance aux pannes
En parlant de Hadoop contre Spark dans la catégorie de tolérance aux pannes, nous pouvons dire que les deux fournissent un niveau respectable de gestion des échecs . De plus, nous pouvons dire que leur approche de la tolérance aux pannes est différente.
Hadoop a la tolérance aux pannes comme base de son fonctionnement. Il réplique les données plusieurs fois sur les nœuds. En cas de problème, le système reprend le travail en créant les blocs manquants à partir d'autres emplacements. Les nœuds maîtres suivent l'état de tous les nœuds esclaves. Enfin, si un nœud esclave ne répond pas aux pings d'un maître, le maître affecte les travaux en attente à un autre nœud esclave.
Spark utilise des blocs RDD pour atteindre la tolérance aux pannes. Le système suit la façon dont l'ensemble de données immuable est créé. Ensuite, il peut redémarrer le processus en cas de problème. Spark peut reconstruire les données dans un cluster en utilisant le suivi DAG des workflows. Cette structure de données permet à Spark de gérer les défaillances dans un écosystème de traitement de données distribué.
Évolutivité
La frontière entre Hadoop et Spark devient floue dans cette section. Hadoop utilise HDFS pour gérer le Big Data. Lorsque le volume de données augmente rapidement, Hadoop peut rapidement évoluer pour répondre à la demande. Étant donné que Spark n'a pas de système de fichiers, il doit s'appuyer sur HDFS lorsque les données sont trop volumineuses pour être gérées.
Les clusters peuvent facilement s'étendre et augmenter la puissance de calcul en ajoutant plus de serveurs au réseau. En conséquence, le nombre de nœuds dans les deux frameworks peut atteindre des milliers. Il n'y a pas de limite ferme au nombre de serveurs que vous pouvez ajouter à chaque cluster et à la quantité de données que vous pouvez traiter.
Certains des chiffres confirmés incluent 8 000 machines dans un environnement Spark avec des pétaoctets de données. En parlant de clusters Hadoop, ils sont bien connus pour héberger des dizaines de milliers de machines et près d'un exaoctet de données.
Facilité d'utilisation et prise en charge des langages de programmation
Spark est peut-être le cadre le plus récent avec moins d'experts disponibles que Hadoop, mais il est connu pour être plus convivial. En revanche, Spark prend en charge plusieurs langues à côté du langage natif (Scala) :Java, Python, R et Spark SQL. Cela permet aux développeurs d'utiliser le langage de programmation qu'ils préfèrent.
Le framework Hadoop est basé sur Java . Les deux langages principaux pour écrire du code MapReduce sont Java ou Python. Hadoop n'a pas de mode interactif pour aider les utilisateurs. Cependant, il s'intègre aux outils Pig et Hive pour faciliter l'écriture de programmes MapReduce complexes.
En plus de la prise en charge des API dans plusieurs langues, Spark gagne dans la section facilité d'utilisation avec son mode interactif. Vous pouvez utiliser le shell Spark pour analyser les données de manière interactive avec Scala ou Python. Le shell fournit un retour instantané aux requêtes, ce qui rend Spark plus facile à utiliser que Hadoop MapReduce.
Une autre chose qui donne à Spark le dessus est que les programmeurs peuvent réutiliser le code existant le cas échéant. Ce faisant, les développeurs peuvent réduire le temps de développement des applications. Les données historiques et de flux peuvent être combinées pour rendre ce processus encore plus efficace.
Sécurité
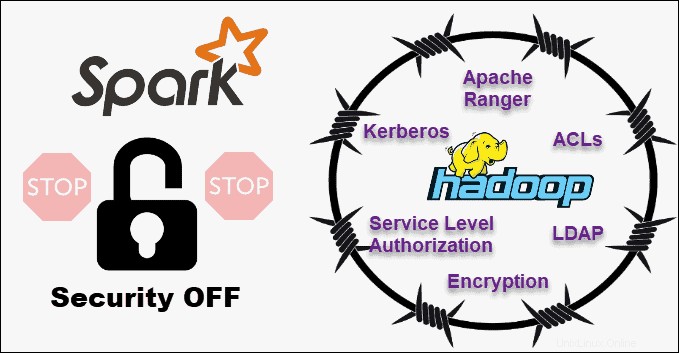
En comparant Hadoop à la sécurité Spark, nous allons tout de suite sortir le chat du sac - Hadoop est clairement le gagnant . Surtout, la sécurité de Spark est désactivée par défaut. Cela signifie que votre configuration est exposée si vous ne résolvez pas ce problème.
Vous pouvez améliorer la sécurité de Spark en introduisant une authentification via un secret partagé ou une journalisation des événements. Cependant, cela ne suffit pas pour les charges de travail de production.
En revanche, Hadoop fonctionne avec plusieurs méthodes d'authentification et de contrôle d'accès. La plus difficile à mettre en œuvre est l'authentification Kerberos. Si Kerberos est trop lourd à gérer, Hadoop prend également en charge Ranger , LDAP , ACL , chiffrement inter-nœuds , autorisations de fichiers standard sur HDFS et autorisation de niveau de service .
Cependant, Spark peut atteindre un niveau de sécurité adéquat en s'intégrant à Hadoop . De cette façon, Spark peut utiliser toutes les méthodes disponibles pour Hadoop et HDFS. De plus, lorsque Spark s'exécute sur YARN, vous pouvez adopter les avantages des autres méthodes d'authentification que nous avons mentionnées ci-dessus.
Apprentissage automatique
L'apprentissage automatique est un processus itératif qui fonctionne mieux en utilisant l'informatique en mémoire. Pour cette raison, Spark s'est avéré être une solution plus rapide dans ce domaine.
La raison en est que Hadoop MapReduce divise les travaux en tâches parallèles qui peuvent être trop volumineuses pour les algorithmes d'apprentissage automatique. Ce processus crée des problèmes de performances d'E/S dans ces applications Hadoop.
La bibliothèque Mahout est la principale plate-forme d'apprentissage automatique des clusters Hadoop. Mahout s'appuie sur MapReduce pour effectuer le regroupement, la classification et la recommandation. Samsara a commencé à remplacer ce projet.
Spark est livré avec une bibliothèque d'apprentissage automatique par défaut, MLlib. Cette bibliothèque effectue des calculs ML itératifs en mémoire. Il comprend des outils pour effectuer la régression, la classification, la persistance, la construction de pipeline, l'évaluation et bien d'autres.
Spark avec MLlib s'est avéré neuf fois plus rapide qu'Apache Mahout dans un environnement basé sur disque Hadoop. Lorsque vous avez besoin de résultats plus efficaces que ce qu'offre Hadoop, Spark est le meilleur choix pour l'apprentissage automatique.
Planification et gestion des ressources
Hadoop n'a pas de planificateur intégré. Il utilise des solutions externes pour la gestion des ressources et la planification. Avec ResourceManager et NodeManager , YARN est responsable de la gestion des ressources dans un cluster Hadoop. L'un des outils disponibles pour planifier les workflows est Oozie.
YARN ne s'occupe pas de la gestion de l'état des applications individuelles. Il alloue uniquement la puissance de traitement disponible.
Hadoop MapReduce fonctionne avec des plug-ins tels que CapacityScheduler et FairScheduler . Ces planificateurs garantissent que les applications obtiennent les ressources essentielles nécessaires tout en maintenant l'efficacité d'un cluster. Le FairScheduler donne les ressources nécessaires aux applications tout en veillant à ce qu'en fin de compte, toutes les applications obtiennent la même allocation de ressources.
Spark, d'autre part, a ces fonctions intégrées. Le planificateur DAG est chargé de diviser les opérateurs en étapes. Chaque étape comporte plusieurs tâches que DAG planifie et que Spark doit exécuter.
Spark Scheduler et Block Manager effectuent la planification, la surveillance et la distribution des ressources des travaux et des tâches dans un cluster.
Cas d'utilisation de Hadoop par rapport à Spark
En examinant Hadoop par rapport à Spark dans les sections répertoriées ci-dessus, nous pouvons extraire quelques cas d'utilisation pour chaque framework.
Les cas d'utilisation d'Hadoop incluent :
- Traitement d'ensembles de données volumineux dans des environnements où la taille des données dépasse la mémoire disponible
- Création d'une infrastructure d'analyse de données avec un budget limité
- Réaliser des travaux où des résultats immédiats ne sont pas requis et où le temps n'est pas un facteur limitant.
- Traitement par lots avec des tâches exploitant les opérations de lecture et d'écriture sur disque
- Analyse des données historiques et d'archives
Avec Spark, nous pouvons séparer les cas d'utilisation suivants où il surpasse Hadoop :
- L'analyse des données de flux en temps réel.
- Lorsque le temps presse, Spark fournit des résultats rapides avec des calculs en mémoire.
- Traitement des chaînes d'opérations parallèles à l'aide d'algorithmes itératifs
- Traitement graphique parallèle pour modéliser les données
- Toutes les applications de machine learning
Remarque :Si vous avez pris votre décision, vous pouvez suivre notre guide sur comment installer Hadoop sur Ubuntu ou comment installer Spark sur Ubuntu. Si vous travaillez sous Windows 10, consultez Comment installer Spark sur Windows 10.
Hadoop ou Spark ?
Hadoop et Spark sont des technologies de traitement du Big Data. En dehors de cela, ce sont des frameworks assez différents dans la façon dont ils gèrent et traitent les données.
Selon les sections précédentes de cet article, il semble que Spark soit le grand gagnant. Bien que cela puisse être vrai dans une certaine mesure, en réalité, ils ne sont pas créés pour se faire concurrence, mais plutôt pour se compléter.
Bien sûr, comme nous l'avons indiqué plus haut dans cet article, il existe des cas d'utilisation où l'un ou l'autre framework est un choix plus logique. Dans la plupart des autres applications, Hadoop et Spark fonctionnent mieux ensemble . En tant que successeur, Spark n'est pas là pour remplacer Hadoop mais pour utiliser ses fonctionnalités pour créer un nouvel écosystème amélioré.
En combinant les deux, Spark peut tirer parti des fonctionnalités qui lui manquent, comme un système de fichiers. Hadoop stocke une énorme quantité de données à l'aide de matériel abordable et effectue ensuite des analyses, tandis que Spark apporte un traitement en temps réel pour gérer les données entrantes. Sans Hadoop, les applications métier peuvent manquer des données historiques cruciales que Spark ne gère pas.
Dans cet environnement coopératif, Spark tire également parti des avantages de Hadoop en matière de sécurité et de gestion des ressources. Avec YARN, le clustering Spark et la gestion des données sont beaucoup plus faciles. Vous pouvez exécuter automatiquement des charges de travail Spark en utilisant toutes les ressources disponibles.
Cette collaboration fournit les meilleurs résultats en matière d'analyse rétroactive des données transactionnelles, d'analyse avancée et de traitement des données IoT. Tous ces cas d'utilisation sont possibles dans un environnement.
Les créateurs de Hadoop et Spark avaient l'intention de rendre les deux plates-formes compatibles et de produire des résultats optimaux adapté à toutes les exigences commerciales.