Présentation
La nécessité de capturer et de traiter le Big Data est le principal moteur de la popularité des bases de données NoSQL. Les données stockées doivent être accessibles à tout moment, depuis n'importe quel endroit et sur n'importe quel appareil. Une façon de répondre à la demande croissante consiste à évoluer et à acheter un serveur plus grand. Cependant, il est plus efficace d'évoluer et d'utiliser un cluster de serveurs à la demande.
Le modèle de base de données relationnelle n'est pas bien adapté à un système distribué couvrant plusieurs machines. Les bases de données NoSQL fournissent une solution viable en se concentrant sur les performances et la disponibilité tout en sacrifiant une partie de la cohérence généralement identifiée avec les bases de données relationnelles.
En plus de répondre à la question "Qu'est-ce que NoSQL ", ce didacticiel utilise des exemples simples pour mettre en évidence les concepts, les fonctionnalités et les types NoSQL de base .

Qu'est-ce que NoSQL ? (Définition NoSQL)
NoSQL (Not SQL ou Not Only SQL) est un terme générique utilisé pour les bases de données qui ne dépendent pas d'un modèle relationnel. Les données n'ont pas besoin d'avoir un schéma strict ni la structure de table SQL habituelle. Le plus souvent, les données sont agrégées sous forme de paires clé-valeur, documents JSON, graphiques, ou des tableaux à colonnes larges.
En utilisant des bases de données NoSQL, vous pouvez stocker d'immenses volumes de données non structurées au fur et à mesure qu'elles arrivent et les structurer ultérieurement. Comme prévu, cela améliore considérablement le débit, les vitesses de lecture/écriture et vous permet de faire évoluer les serveurs horizontalement.
Les bases de données non relationnelles, lorsqu'elles sont appliquées dans le bon environnement de cas d'utilisation, apportent des avantages significatifs en termes de performances et de flexibilité. Cependant, ne pas appliquer de schéma au point d'entrée des données signifie également qu'il est plus difficile d'interroger les bases de données NoSQL, de maintenir la cohérence des données et d'établir des relations entre les ensembles de données.
Fonctionnement de NoSQL
L'idée de base derrière NoSQL est d'optimiser les performances de la base de données pour une mise à l'échelle horizontale, de grands volumes de données et une faible latence en renonçant à certaines restrictions de cohérence des données présentes dans les SGBDR. Au lieu de modèles de données rigides tels que des tables, des colonnes ou des lignes, les bases de données NoSQL offrent des modèles flexibles. Dans les cas d'utilisation qui ne nécessitent pas de cohérence relationnelle, ces modèles aident les NoSQL à être plus performants que les bases de données relationnelles.
Fonctionnalités des bases de données NoSQL
Les bases de données NoSQL sont structurellement diverses et offrent divers modèles de stockage de données. Il existe cependant plusieurs attributs communs qui distinguent NoSQL des bases de données relationnelles.
Schéma en lecture
Une base de données NoSQL vous permet de stocker des données avant d'appliquer une structure ou schéma .
Le schéma est appliqué par le code de l'application uniquement lorsqu'il accède aux données. Ce processus est souvent appelé schéma en lecture . En ne structurant pas les données à l'avance, les bases de données NoSQL peuvent écrire et lire d'immenses volumes de données beaucoup plus rapidement qu'une base de données relationnelle.
NoSQL vs bases de données relationnelles
En revanche, un modèle relationnel SQL structure les données entrantes avant qu'elles ne soient écrites dans une base de données. La conception de schéma prédéfinie est utilisée pour classer à l'avance tous les types de données possibles. Le schéma est appliqué à tous les niveaux car les données sont structurées et stockées dans des tables, des colonnes et des lignes.
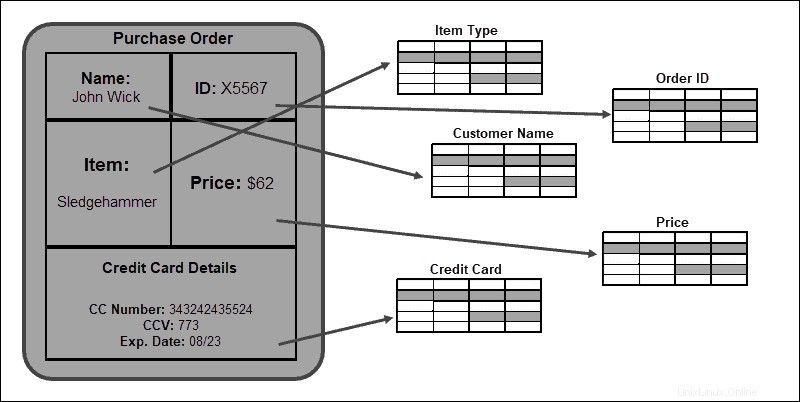
La structure tabulaire stricte est un avantage lors de l'établissement de relations entre les tables et les éléments de la base de données. La cohérence et l'intégrité des données sont garanties par le respect de ce schéma.
Modèle de données non relationnel
Les bases de données NoSQL n'établissent pas de relations entre les enregistrements individuels. Un enregistrement est généralement stocké en tant que document JSON individuel et répliqué sur plusieurs nœuds d'un cluster.
Nous allons utiliser un exemple simple impliquant des données sur des groupes de musique. Dans un modèle non relationnel, le BandID , Nom du groupe , Pays , Genre , Libellé , ID d'album , Nom de l'album, et Date de sortie les attributs sont stockés dans un seul Radiohead document. Si vous avez besoin de trouver la date de sortie de l'album de Radiohead, OK Computer , la réponse est rapide comme l'éclair. La requête fournit des résultats beaucoup plus rapidement car elle n'a pas besoin de récupérer des informations à partir de plusieurs tables (comme dans les bases de données relationnelles), mais plutôt à partir d'une seule entrée.
Les données agrégées d'un enregistrement ne peuvent pas être liées aux données agrégées d'un autre enregistrement. Chaque enregistrement pertinent dans la base de données doit être mis à jour si vous souhaitez ajouter un attribut tel qu'un service de diffusion en continu. Les bases de données NoSQL sont donc mieux adaptées aux gros volumes de données qui n'ont pas besoin d'être structurées ou liées ultérieurement.
BASE vs ACIDE
Une base de données doit-elle annuler une opération et assurer la cohérence des données en cas de panne du réseau ? Ou les bases de données doivent-elles risquer des incohérences de données pour garantir une haute disponibilité ?
L'objectif principal de NoSQL est de maintenir la disponibilité en offrant une cohérence éventuelle. Cohérence éventuelle fait partie de la sémantique BASE. BASE indique qu'une fois les données écrites, elles apparaîtront éventuellement pour la lecture. Sans garanties solides, vous n'avez qu'une probabilité limitée de connaître l'état actuel, car il n'a peut-être pas encore convergé. Si le système fonctionne et que vous attendez suffisamment longtemps après un ensemble donné d'entrées, vous connaîtrez éventuellement le véritable état de la base de données.
L'inconvénient est que les données peuvent ne pas persister une fois les conflits réconciliés. Une lecture peut ne pas obtenir la dernière écriture pendant une période inconnue. Une publication Facebook qui n'apparaît pas pendant quelques minutes est acceptable, mais ne pas être en mesure de voir immédiatement une transaction financière est un problème important.
ACIDE
- Un tomicité. Seules les données spécifiées sont affectées par une opération.
- C constance. Chaque opération déplace la base de données d'un état cohérent à un autre état cohérent.
- Je solution. Une opération n'affecte pas les autres opérations simultanées.
- D urabilité. Les données ne sont pas perdues après une transaction réussie.
BASE
- B asiquementA disponible. Les opérations d'écriture et de lecture sont disponibles autant que possible mais sans aucune garantie stricte.
- S État d'origine. Sans garanties, nous ne savons pas, mais nous nous attendons à ce que les données finissent par devenir cohérentes.
- E cohérence éventuelle. Si le système est entièrement fonctionnel et qu'une période suffisamment longue s'est écoulée, nous connaîtrons éventuellement le véritable état de la base de données.
Les bases de données relationnelles se concentrent sur la cohérence comme la caractéristique la plus importante à maintenir. La cohérence La propriété d'une base de données garantit que si vous écrivez un enregistrement dans une base de données et que vous demandez immédiatement cet enregistrement, vous êtes assuré de le voir. L'ensemble de propriétés ACID, appliqué par les bases de données relationnelles, signifie qu'une fois les données écrites, vous bénéficiez d'une cohérence totale dans les lectures.
En savoir plus sur les deux modèles de transaction de base de données les plus populaires et leurs différences dans l'article ACID vs BASE.
Mise à l'échelle horizontale
Les entreprises ont trouvé des moyens efficaces de tirer profit des données. La croissance rapide du volume, de la vitesse et de la variété de ces données a entraîné l'essor des bases de données NoSQL.
Les principaux sites Web et plates-formes en ligne devaient surmonter certaines des limites des bases de données relationnelles, telles que les vitesses de lecture/écriture et la nécessité de normaliser les données à l'avance. Une limitation importante est la rigidité du modèle relationnel lorsqu'il s'agit de mise à l'échelle. Dans un modèle relationnel, les données ne sont généralement pas partitionnées ou séparées. Au lieu de cela, il est concentré sur un seul nœud, et les bases de données ne peuvent évoluer qu'en augmentant la puissance du matériel existant.
Les bases de données NoSQL sont conçues pour fonctionner efficacement sur des systèmes distribués qui évoluent rapidement horizontalement. Un système distribué a l'avantage supplémentaire de fournir une haute disponibilité constante. Plusieurs répliques d'un enregistrement sont conservées sur les serveurs et les racks, et une panne matérielle n'affecte pas la disponibilité des données. Vous pouvez utiliser en toute sécurité du matériel de base au lieu de serveurs haut de gamme coûteux pour gérer les charges de données croissantes.
Types de bases de données NoSQL
Les modèles de bases de données non relationnelles peuvent être classés en quatre catégories.
- Un magasin de valeur-clé vous permet de stocker tout type de données sous une clé unique.
- Une base de données de documents utilise une approche similaire en agrégeant différents types de données dans un seul document JSON ou XML.
- Basé sur les colonnes les bases stockent les données dans une colonne de votre choix.
- Les bases de données de graphes établissent des arêtes et des propriétés pour les nœuds qui représentent des éléments de données.
Bases de données de valeurs-clés
Les bases de données clé-valeur, parfois appelées magasins clé-valeur, utilisent le modèle de données le plus simple - l'association d'une clé et d'une valeur. Une application récupère la valeur à l'aide de la clé unique.
La valeur peut contenir n'importe quelle structure ou type de données. C'est à l'application qui tente d'accéder aux données d'en comprendre le contenu.
Des exemples de bases de données de valeurs-clés incluent Redis, Riak , Aerospike , et Oracle NoSQL .
Bases de données basées sur des colonnes
Les bases de données basées sur des colonnes se concentrent sur l'efficacité des opérations de lecture. Si vous avez besoin de lire rapidement plusieurs colonnes de plusieurs lignes, il est judicieux d'organiser les données en groupes de colonnes (c'est-à-dire des familles de colonnes).
La structure du modèle consiste en un identifiant de ligne qui définit les données agrégées et l'agrégat de lignes composé de valeurs de niveau secondaire plus détaillées (c'est-à-dire des colonnes ).
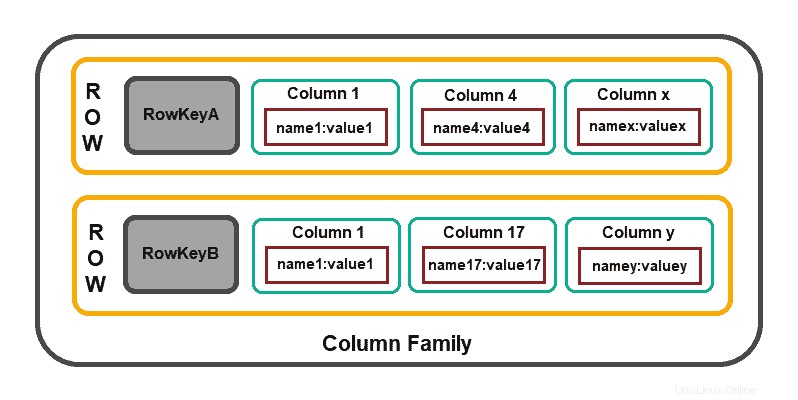
Cassandre , HBase , Amazon DynamoDB et Clickhouse , sont quelques-unes des solutions basées sur des colonnes largement utilisées.
Bases de données de documents
Les bases de données de documents stockent des données partiellement structurées dans des documents, en utilisant JSON, BSON, XML ou d'autres formats. Les données à l'intérieur du document sont semi-structurées pour offrir plus de flexibilité lors de l'interrogation. Contrairement aux magasins de clé-valeur de base, l'utilisateur n'a pas besoin de récupérer l'intégralité de l'enregistrement, uniquement la partie pertinente du document.

Les documents Web, les commentaires des utilisateurs et les applications de publication Web bénéficient tous de ce modèle de données. Les célèbres NoSQL basés sur des documents sont MongoDB , OrientDB , Apache CouchDB , et MarkLogic .
Bases de données de graphes
Les bases de données de graphes organisent les données en nœuds, les bords établissant des relations entre ces nœuds de données.
Ce modèle de stockage de données s'est avéré utile dans les applications qui mettent l'accent sur les relations, telles que les plateformes de médias sociaux, les logiciels de relation client et les systèmes de voyage et de réservation.
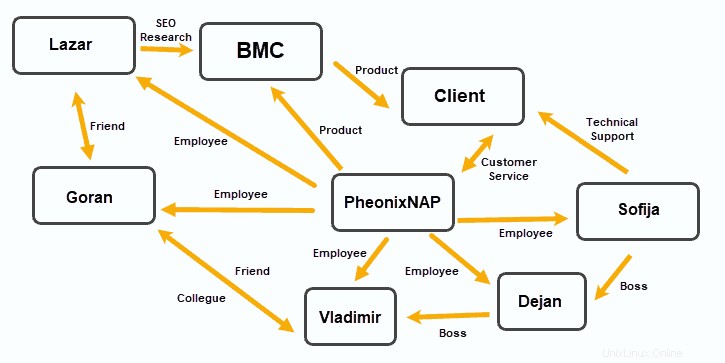
OrientDB et MarkLogic basés sur des documents peuvent fonctionner comme des bases de données de graphes. JanusGraph , RedisGraph , et Neo4j sont des solutions graphiques populaires.
Avantages NoSQL
- Performances – Les bases de données NoSQL offrent de meilleures performances dans les cas d'utilisation qui traitent de données peu relationnelles. Un NoSQL attend un schéma dénormalisé et optimise les lectures en conséquence.
- Flexibilité – Le schéma dynamique de NoSQL facilite le stockage de données non structurées de manière optimale pour un cas spécifique. Il permet la création de documents sans définir sa structure.
- Évolutivité – Bien qu'il soit possible de mettre à l'échelle verticalement le SGBDR en mettant à niveau la mémoire, le stockage ou la puissance de traitement de la machine, NoSQL présente l'avantage supplémentaire de la mise à l'échelle horizontale. Cela signifie qu'il est possible de gérer une augmentation du trafic en mettant à niveau la base de données avec des serveurs supplémentaires.
Quand utiliser NoSQL ?
Essayer d'appliquer une solution de base de données unique pour chaque scénario possible n'est pas une bonne idée. Les différents types de bases de données abordés dans cet article sont conçus pour traiter des problèmes de données spécifiques. Cela ne se limite pas aux bases de données NoSQL. Même les bases de données relationnelles ont du mal à normaliser divers types de données dans un schéma strict.
Le fonctionnement interne des bases de données relationnelles est bien documenté et prévisible. Le langage SQL et l'ensemble des outils créés à l'aide de la technologie relationnelle sont omniprésents, avec un personnel expérimenté facilement disponible. Le modèle de base de données relationnelle vous permet d'accéder aux données de nombreuses manières différentes et créatives et de ne pas être limité par la manière dont les données sont stockées.
Mégadonnées
Le Big Data et l'intérêt d'en capturer autant que possible sur le plan technique ne constituent pas une charge de travail adaptée au modèle relationnel. Une base de données NoSQL qui n'utilise pas de schéma strict est un excellent choix pour stocker de grandes quantités de données assorties et non structurées.
Développement de logiciels
Le développement d'applications a considérablement bénéficié des bases de données NoSQL. De nombreuses heures précieuses de développement ont été gaspillées à mapper des données entre des structures de données en mémoire et une base de données relationnelle. Une base de données NoSQL signifie que vous créez votre modèle, un modèle adapté pour répondre aux besoins de l'application qui y accède et réduire éventuellement la quantité de codage requise.
Si une base de données n'a pas de schéma, cela signifie que l'application qui accède aux données doit en avoir un. Cela peut rapidement devenir un problème si plusieurs applications, développées indépendamment les unes des autres, doivent accéder à la même base de données.
Les incohérences sur les lectures sont finalement résolues, mais le manque de cohérence sur les écritures est un problème sérieux. Ce problème est souvent résolu en limitant toutes les interactions de base de données au sein d'une seule application et en l'intégrant à d'autres applications utilisant des services Web. Cette solution correspond bien à la tendance générale à utiliser les services Web à des fins d'intégration.