Présentation
Les frameworks de traitement de données, tels qu'Apache Hadoop et Spark, ont alimenté le développement du Big Data. Leur capacité à collecter de grandes quantités de données à partir de différents flux de données est incroyable, cependant, ils ont besoin d'un entrepôt de données pour analyser, gérer et interroger toutes les données.
Souhaitez-vous en savoir plus sur ce que sont les entrepôts de données et en quoi ils consistent ?
Cet article explique l'architecture de l'entrepôt de données et le rôle de chaque composant dans le système.
Qu'est-ce qu'un entrepôt de données ?
Un entrepôt de données (DW ou DWH) est un système complexe qui stocke des données historiques et cumulatives utilisées pour les prévisions, les rapports et l'analyse des données. Cela implique de collecter, de nettoyer et de transformer des données à partir de différents flux de données et de les charger dans des tables de faits/dimensionnelles.
Un entrepôt de données représente une structure de données orientée sujet, intégrée, variable dans le temps et non volatile.
En se concentrant sur le sujet plutôt que sur les opérations, le DWH intègre des données provenant de plusieurs sources, offrant à l'utilisateur une source unique d'informations dans un format cohérent. Comme il est non volatile, il enregistre toutes les modifications de données en tant que nouvelles entrées sans effacer son état précédent. Cette fonctionnalité est étroitement liée à la variation dans le temps, car elle conserve un enregistrement des données historiques, ce qui vous permet d'examiner les changements au fil du temps.
Toutes ces propriétés aident les entreprises à créer des rapports analytiques nécessaires pour étudier les changements et les tendances.
Architecture d'entrepôt de données
Il existe trois façons de construire un système d'entrepôt de données. Ces approches sont classées en fonction du nombre de niveaux dans l'architecture. Par conséquent, vous pouvez avoir :
- Architecture à un seul niveau
- Architecture à deux niveaux
- Architecture à trois niveaux
Architecture d'entrepôt de données à un niveau
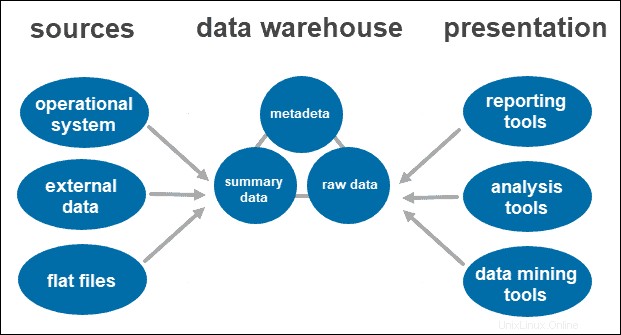
L'architecture à un niveau n'est pas une approche fréquemment pratiquée. L'objectif principal d'une telle architecture est de supprimer la redondance en minimisant la quantité de données stockées.
Son principal inconvénient est qu'il n'a pas de composant qui sépare le traitement analytique et transactionnel.
Architecture d'entrepôt de données à deux niveaux
Une architecture à deux niveaux comprend une zone de transit pour toutes les sources de données, avant la couche d'entrepôt de données. En ajoutant une zone intermédiaire entre les sources et le référentiel de stockage, vous vous assurez que toutes les données chargées dans l'entrepôt sont nettoyées et dans le format approprié.
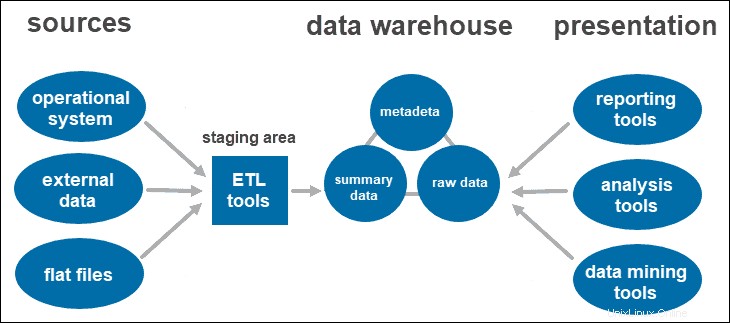
Cette approche a certaines limitations de réseau. De plus, vous ne pouvez pas l'étendre pour prendre en charge un plus grand nombre d'utilisateurs.
Architecture d'entrepôt de données à trois niveaux
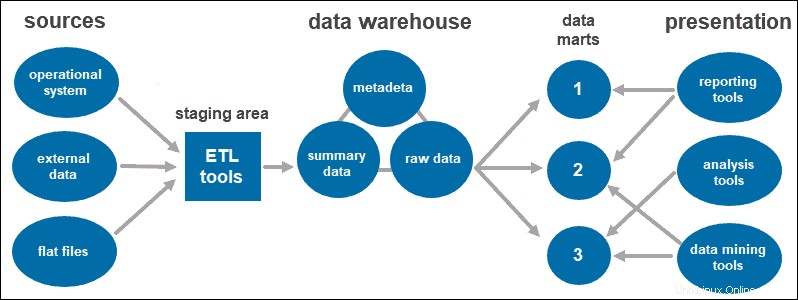
L'approche à trois niveaux est l'architecture la plus largement utilisée pour les systèmes d'entrepôt de données.
Il se compose essentiellement de trois niveaux :
- Le niveau inférieur est la base de données de l'entrepôt, où les données nettoyées et transformées sont chargées.
- Le niveau intermédiaire est la couche application donnant une vue abstraite de la base de données. Il organise les données pour les rendre plus adaptées à l'analyse. Cela se fait avec un serveur OLAP, implémenté à l'aide du modèle ROLAP ou MOLAP.
- Le niveau supérieur est l'endroit où l'utilisateur accède et interagit avec les données. Il représente la couche client frontal. Vous pouvez utiliser des outils de création de rapports, des requêtes, des analyses ou des outils d'exploration de données.
Composants d'entrepôt de données
À partir des architectures décrites ci-dessus, vous remarquez que certains composants se chevauchent, tandis que d'autres sont uniques au nombre de niveaux.
Vous trouverez ci-dessous certains des composants les plus importants de l'entrepôt de données et leurs rôles dans le système.
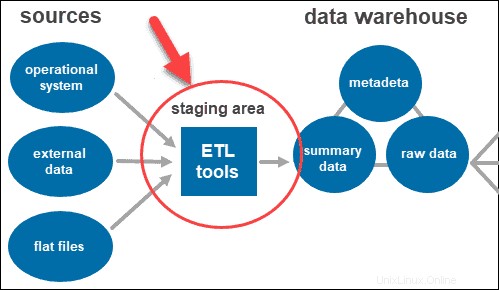
Outils ETL
ETL signifie Extraire , Transformer , et Charger . La couche intermédiaire utilise des outils ETL pour extraire les données nécessaires de différents formats et vérifier la qualité avant de les charger dans l'entrepôt de données.
Les données provenant de la couche source de données peuvent se présenter sous divers formats. Avant de fusionner toutes les données collectées à partir de plusieurs sources dans une seule base de données, le système doit nettoyer et organiser les informations.
La base de données
Le composant le plus crucial et le cœur de chaque architecture est la base de données. L'entrepôt est l'endroit où les données sont stockées et accessibles.
Lors de la création du système d'entrepôt de données, vous devez d'abord décider du type de base de données que vous souhaitez utiliser.
Vous pouvez choisir parmi quatre types de bases de données :
- Bases de données relationnelles (bases de données centrées sur les lignes).
- Bases de données analytiques (développé pour soutenir et gérer les analyses).
- Applications d'entrepôt de données (logiciel de gestion des données et matériel de stockage des données proposé par des revendeurs tiers).
- Bases de données basées sur le cloud (hébergées sur le cloud).
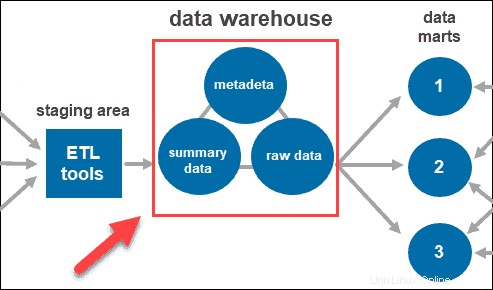
Données
Une fois que le système a nettoyé et organisé les données, il les stocke dans l'entrepôt de données. L'entrepôt de données représente le référentiel central qui stocke les métadonnées, les données récapitulatives et les données brutes provenant de chaque source.
- Métadonnées est l'information qui définit les données. Son rôle principal est de simplifier le travail avec les instances de données. Il permet aux analystes de données de classer, localiser et diriger les requêtes vers les données requises.
- Données récapitulatives est généré par le gestionnaire d'entrepôt. Il se met à jour au fur et à mesure que de nouvelles données sont chargées dans l'entrepôt. Ce composant peut inclure des données légèrement ou fortement résumées. Son rôle principal est d'accélérer les performances des requêtes.
- Données brutes est le chargement réel des données dans le référentiel, qui n'a pas été traité. Le fait d'avoir les données sous leur forme brute les rend accessibles pour un traitement et une analyse ultérieurs.
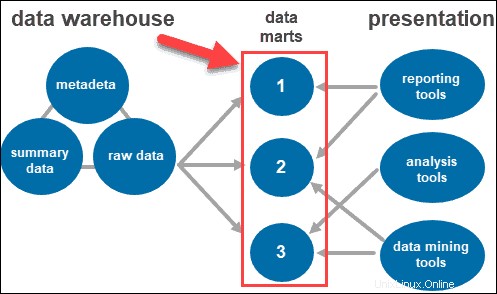
Accéder aux outils
Les utilisateurs interagissent avec les informations recueillies par le biais de différents outils et technologies. Ils peuvent analyser les données, recueillir des informations et créer des rapports.
Certains des outils utilisés incluent :
- Outils de création de rapports. Ils jouent un rôle crucial dans la compréhension de la situation de votre entreprise et de ce qui doit être fait ensuite. Les outils de création de rapports incluent des visualisations telles que des graphiques et des diagrammes montrant l'évolution des données au fil du temps.
- Outils OLAP. Outils de traitement analytique en ligne qui permettent aux utilisateurs d'analyser des données multidimensionnelles sous plusieurs angles. Ces outils permettent un traitement rapide et une analyse précieuse. Ils extraient des données de nombreux ensembles de données relationnelles et les réorganisent dans un format multidimensionnel.
- Outils d'exploration de données. Examinez les ensembles de données pour trouver des modèles dans l'entrepôt et la corrélation entre eux. L'exploration de données permet également d'établir des relations lors de l'analyse de données multidimensionnelles.
Mart de données
Les magasins de données vous permettent d'avoir plusieurs groupes au sein du système en segmentant les données de l'entrepôt en catégories. Il partitionne les données, les produisant pour un groupe d'utilisateurs particulier.
Par exemple, vous pouvez utiliser des magasins de données pour classer les informations par département au sein de l'entreprise.
Bonnes pratiques d'entrepôt de données
La conception d'un entrepôt de données repose sur la compréhension de la logique métier de votre cas d'utilisation individuel.
Les exigences varient, mais il existe des bonnes pratiques d'entrepôt de données que vous devez suivre :
- Créez un modèle de données. Commencez par identifier la logique métier de l'organisation. Comprendre quelles données sont vitales pour l'organisation et comment elles transiteront par l'entrepôt de données.
- Optez pour une norme d'architecture d'entrepôt de données bien connue. Un modèle de données fournit un cadre et un ensemble de meilleures pratiques à suivre lors de la conception de l'architecture ou du dépannage des problèmes. Les normes d'architecture les plus courantes incluent 3NF, la modélisation Data Vault et le schéma en étoile.
- Créez un diagramme de flux de données. Documentez la façon dont les données circulent dans le système. Sachez comment cela se rapporte à vos exigences et à votre logique métier.
- Avoir une seule source de vérité. Lorsqu'elle traite autant de données, une organisation doit avoir une seule source de vérité. Consolidez les données dans un référentiel unique.
- Utilisez l'automatisation. Les outils d'automatisation sont utiles lorsqu'il s'agit de traiter de grandes quantités de données.
- Autoriser le partage de métadonnées. Concevez une architecture qui facilite le partage de métadonnées entre les composants de l'entrepôt de données.
- Appliquez les normes de codage. Les normes de codage garantissent l'efficacité du système.