Présentation
Dénormalisation de la base de données est une technique utilisée pour améliorer les performances d'accès aux données. Lorsqu'une base de données est normalisée et que des méthodes telles que l'indexation ne suffisent pas, la dénormalisation constitue l'une des dernières options pour accélérer la récupération des données.
Cet article explique ce qu'est la dénormalisation de base de données et les différentes techniques utilisées pour accélérer une base de données.

Qu'est-ce que la dénormalisation de la base de données ?
Dénormalisation de la base de données est le processus consistant à combiner systématiquement des données pour obtenir rapidement des informations. Le processus réduit les relations à des formes normales inférieures, ce qui réduit l'intégrité globale des données.
En revanche, les performances de récupération des données augmentent. Au lieu d'effectuer plusieurs jointures coûteuses sur de nombreuses tables, la normalisation de la base de données permet de rassembler des informations qui sont communément ou logiquement combinées.
Les anomalies de la base de données apparaissent à cause des formes normales inférieures. Le problème des redondances trouve une solution en ajoutant des limitations au niveau logiciel lors de la saisie de données dans une base de données.
Normalisation de base de données vs dénormalisation
La normalisation et la dénormalisation de la base de données sont deux façons différentes de modifier la structure d'une base de données. Le tableau décrit les principales différences entre les deux méthodes :
| Normalisation | Dénormalisation | |
|---|---|---|
| Fonctionnalité | Supprime les informations redondantes et améliore la vitesse de modification des données. | Combine plusieurs informations en une seule unité et améliore la vitesse de récupération des données. |
| Concentration | Nettoyage de la base de données pour supprimer les redondances. | Redondances introduites pour une exécution plus rapide des requêtes. |
| Mémoire | Performances générales optimisées et améliorées. | Inefficacité de la mémoire due aux redondances. |
| Intégrité | La suppression des anomalies de la base de données améliore l'intégrité de la base de données. | Pas de maintien de l'intégrité des données. Des anomalies de la base de données sont présentes. |
| Cas d'utilisation | Bases de données où les changements d'insertion, de mise à jour et de suppression se produisent souvent et les jointures ne sont pas chères. | Bases de données souvent interrogées, telles que les entrepôts de données. |
| Type de traitement | Traitement des transactions en ligne - OLTP | Traitement analytique en ligne - OLAP |
La normalisation de la base de données prend une base de données non normalisée à travers des formes normales pour améliorer la structure des données. D'autre part, la dénormalisation commence par une base de données normalisée et combine les données pour une exécution plus rapide des requêtes couramment utilisées.
Pourquoi et quand dénormaliser une base de données ?
La dénormalisation de la base de données est une technique viable lorsque la vitesse de récupération des données est un facteur essentiel. Cependant, la méthode modifie la structure globale de la base de données. La dénormalisation est utile dans les scénarios suivants :
- Amélioration des performances des requêtes. Rassembler les informations ajoute des redondances. Cependant, le nombre de JOIN diminue, ce qui augmente les performances des requêtes.
- Facilité de gestion . Une base de données normalisée est difficile à gérer en raison de sa grande granularité. Au lieu de calculer des valeurs ou de les connecter selon les besoins, la dénormalisation permet de fournir des données facilement disponibles.
- Rapports accélérés . Les données analytiques nécessitent beaucoup de calculs rapidement. Une base de données dénormalisée pour générer des rapports est une solution parfaite pour fournir rapidement des informations analytiques.
Si une base de données a de faibles performances, la dénormalisation n'est pas toujours la bonne solution. Étant donné que le processus modifie la structure de la base de données, les fonctionnalités existantes risquent de tomber en panne.
Avoir un point de référence est un concept important lors de la modification de la structure de la base de données. En fin de compte, la normalisation de la base de données sert de dernier recours au lieu d'une solution rapide.
Techniques de dénormalisation
Il existe différentes techniques de dénormalisation de base de données utilisées en fonction du cas d'utilisation. Chaque méthode a un lieu d'utilisation approprié, des avantages et des inconvénients.
Tables de pré-union
Les tables pré-jointes stockent les informations fréquemment utilisées dans une seule table. Le processus est utile lorsque :
- Les requêtes s'exécutent fréquemment sur les tables ensemble.
- L'opération de jointure est coûteuse.
La méthode crée des redondances massives, il est donc essentiel d'utiliser un nombre minimal de colonnes et de mettre à jour les informations périodiquement.
Exemple de tables de pré-jointure
Un magasin conserve les informations sur les articles et les catégories auxquelles les articles appartiennent. La clé étrangère sert de référence au type d'élément. Pré-joindre les tables ajoute le nom de la catégorie à la table des éléments.
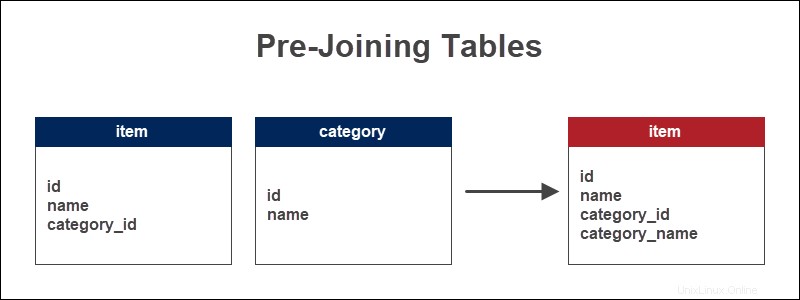
L'ajout du nom de la catégorie directement au tableau des éléments permet de visualiser rapidement les éléments par catégorie. Pour les requêtes plus longues, cette méthode permet de gagner du temps et de réduire le nombre de JOINs.
Tableaux en miroir
Une table en miroir est une copie d'une table existante. Le tableau est soit :
- Une copie partielle.
- Une copie complète.
L'objectif est de reproduire les données de l'original dans une nouvelle table. Faire des doublons est une bonne technique pour créer une sauvegarde afin de préserver l'état initial de la base de données.
Exemple de tableaux en miroir
La mise en miroir des tables est une méthode souvent utilisée pour préparer les données dans les systèmes d'aide à la décision. Étant donné que les requêtes s'agrègent généralement sur de nombreux points de données, la tâche réduirait considérablement les performances du système.
Les systèmes d'aide à la décision bénéficient grandement de l'utilisation de tables en miroir. L'application de transactions sur la table d'origine se déroule sans interruption tandis que des rapports exigeants sont générés sur la table en double.
Fractionnement de table
Le fractionnement de table implique de diviser des tables normalisées en deux relations ou plus. La division des tableaux se fait en deux dimensions :
- Horizontalement . Tableaux divisés en sous-ensembles de lignes à l'aide de l'
UNIONopérateur. - Verticalement . Tables divisées en sous-ensembles de colonnes à l'aide de
INNER JOINopérateur.
L'objectif de la méthode est de diviser les tables en unités plus petites pour une gestion des données plus rapide et plus pratique. Si la base de données contient également la table d'origine, cette méthode est considérée comme un cas particulier de tables en miroir.
Exemples de fractionnement de table
Les exemples d'utilisation dépendent des critères de découpage de table. Les raisons les plus courantes pour diviser les tables sont :
- Administratif . Une table pour chaque secteur au lieu d'une table pour toute une entreprise.
- Spatial . Une table pour chaque région au lieu d'une table pour tout le pays.
- Basé sur le temps . Une table pour chaque mois au lieu d'une table pour toute une année.
- Physique . Un tableau pour chaque emplacement au lieu d'un tableau pour tous les sites.
- Procédure . Un tableau pour chaque étape d'une tâche au lieu d'un tableau pour un travail entier.
Stocker des valeurs dérivables
Le stockage des calculs fréquemment exécutés est utile dans les situations où :
- L'utilisation de la valeur dérivée est fréquente.
- Les valeurs sources ne changent pas.
Le stockage direct des données dérivables garantit que les calculs sont déjà effectués lors de la génération d'un rapport et élimine le besoin de rechercher les valeurs sources pour chaque requête.
Exemple de stockage de valeurs dérivables
Si nous avons une table de base de données qui garde une trace des informations sur les personnes, l'âge d'une personne est une valeur calculée en fonction de sa date de naissance. Dérivez l'âge en trouvant la différence entre la date actuelle à l'aide de la fonction de date MySQL CURDATE() et la date de naissance.
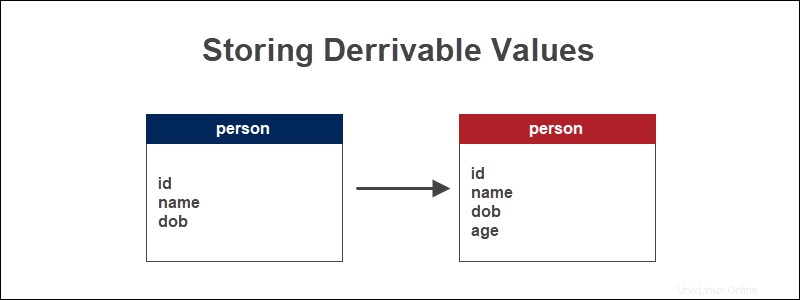
L'âge est une information essentielle lors de l'analyse de toute information démographique. La valeur source, qui est la date de naissance, ne change pas.
Tableaux hiérarchiques
Une table hiérarchique est une structure arborescente avec une relation un-à-plusieurs. Une table parent a de nombreux enfants. Cependant, les enfants n'ont qu'une seule table parent. Les tables hiérarchiques sont utilisées dans les cas où :
- La structure des données est hiérarchique.
- Les tables parentes sont statiques et immuables.
Valeurs codées en dur
Les valeurs codées en dur suppriment une référence à une entité couramment utilisée. Utilisez cette méthode dans les situations où :
- Les valeurs sont considérées comme statiques.
- Le nombre de valeurs est petit.
Au lieu d'utiliser une petite table de consultation, les valeurs sont directement codées en dur dans l'application. Le processus évite également d'avoir à effectuer des jointures sur la table de consultation.
Exemple de valeurs codées en dur
Une table contenant des informations sur les personnes pourrait utiliser une petite table de consultation pour stocker des informations sur le sexe des individus. Étant donné que les informations contenues dans la table de recherche ont un nombre limité de valeurs, envisagez de coder en dur les données directement dans la table des personnes.
Les valeurs codées en dur éliminent le besoin d'une table de consultation et de l'opération JOIN avec cette table. Toute modification apportée à la table de correspondance ou l'enregistrement de nouvelles valeurs nécessite l'ajout d'une contrainte de vérification.
Stocker les détails avec le maître
La table principale contient la table principale d'informations, tandis que d'autres tables contiennent des détails spécifiques. Stockez les détails avec la table principale lorsque :
- Une vue d'ensemble détaillée de la table principale est essentielle.
- Les rapports analytiques sur la table principale sont fréquents.
Conserver tous les détails avec la table principale est pratique lors de la sélection des données. La méthode fonctionne mieux lorsqu'il y a moins de détails. Sinon, le processus de récupération des données ralentit considérablement.
Exemple de stockage des détails avec Master
Une table principale contenant des informations sur les clients stocke généralement des détails spécifiques sur la personne dans une table distincte. Les informations sur l'emplacement particulier, par exemple, résident généralement dans une série de tables plus petites.
Tout rapport prenant en compte l'emplacement des clients bénéficie de l'ajout des détails de l'emplacement au tableau principal.
Répéter un seul détail avec maître
Les requêtes n'ont souvent besoin que d'un seul détail ajouté à la table principale au lieu de pré-joindre plusieurs valeurs. Utilisez cette méthode lorsque :
- Les JOIN sont coûteux pour un seul détail.
- La table principale requiert souvent les informations.
L'ajout d'un seul détail à une table principale est plus courant lorsque la base de données contient des données historiques. L'entité répétée est généralement l'information la plus récente.
Exemple de détail unique avec maître
Une base de données de magasin a normalement une table principale d'informations sur les articles qu'elle vend. Un autre tableau avec des détails sur les changements de prix historiques contient également des informations sur le prix actuel.
Étant donné que ce détail unique aide à analyser les prix actuels des articles, les dernières informations sur le prix sont pratiques à répéter dans le tableau principal.
Toute modification des coûts doit également être traitée et mise à jour dans le tableau principal pour des raisons de cohérence.
Clés de court-circuit
Dans une base de données avec trois tables ou plus d'informations liées, la méthode des clés de court-circuit ignore la ou les tables du milieu et "court-circuite" les tables des grands-parents et des petits-enfants.
Utilisez la technique du court-circuit dans les situations où :
- Une base de données comporte plus de trois niveaux maître-détail.
- Les valeurs des grands-parents et des petits-enfants sont souvent nécessaires et les informations sur les parents ne sont pas aussi utiles.
Si deux relations sont liées par une table intermédiaire, omettez le JOIN sur la relation intermédiaire et connectez directement la première et la dernière table.
Exemple de clés de court-circuit
Un système d'information pourrait conserver des informations sur les personnes dans une table, leur adresse dans un autre emplacement et la zone géographique de cette adresse dans une troisième table. Pour tout rapport démographique, l'adresse exacte n'est pas une information essentielle.
Cependant, la localisation d'une personne est essentielle pour l'analyse. Court-circuiter la table des personnes avec la zone omet le JOIN sur la table du milieu.
Avantages de la dénormalisation
Les avantages de dénormalisation de la base de données sont :
- Vitesse . Étant donné que les requêtes JOIN sont coûteuses sur une base de données normalisée, la récupération des données est plus rapide.
- Simplicité . La récupération des données est plus simple en raison du nombre réduit de tables.
- Moins d'erreurs . Travailler avec un plus petit nombre de tables signifie moins de bogues lors de la récupération d'informations à partir d'une base de données.
Inconvénients de la dénormalisation
Les inconvénients à prendre en compte lors de la dénormalisation d'une base de données :
- Complexité . La mise à jour et l'insertion dans une base de données sont plus complexes et coûteuses.
- Incohérence . Trouver la valeur correcte pour une information est plus difficile car les données sont difficiles à mettre à jour.
- Stockage . Un espace de stockage plus important est nécessaire en raison des redondances introduites.