Présentation
La normalisation de base de données est une méthode de conception de bases de données relationnelles qui permet d'organiser correctement les tables de données. Le processus vise à créer un système qui représente fidèlement les informations et les relations sans perte ni redondance de données.
Cet article explique la normalisation de la base de données et comment normaliser une base de données grâce à un exemple pratique.

Qu'est-ce que la normalisation de base de données ?
Normalisation de la base de données est une technique pour créer des tables de base de données avec des colonnes et des clés appropriées en décomposant une grande table en unités logiques plus petites. Le processus tient également compte des exigences de l'environnement dans lequel réside la base de données.
La normalisation est un processus itératif. Généralement, la normalisation d'une base de données se fait par une série de tests. Chaque étape suivante décompose les tables en informations plus gérables, ce qui rend la base de données globale logique et plus facile à utiliser.
Pourquoi la normalisation de la base de données est-elle importante ?
La normalisation aide un concepteur de base de données à distribuer de manière optimale les attributs dans les tables. La technique élimine les éléments suivants :
- Attributs avec multiples valeurs.
- Doublé ou répété attributs.
- Non descriptif attributs.
- Attributs avec redondant informations.
- Attributs créés à partir d'autres fonctionnalités .
Bien qu'une normalisation totale de la base de données ne soit pas nécessaire, elle fournit un environnement d'informations qui fonctionne bien. La méthode assure systématiquement :
- Une structure de base de données adapté aux requêtes générales.
- Redondance des données minimisée , ce qui augmente l'efficacité de la mémoire sur un serveur de base de données.
- Intégrité des données optimisée grâce à la réduction des anomalies d'insertion, de mise à jour et de suppression.
La normalisation de la base de données transforme la cohérence globale de la base de données, fournissant un environnement efficace.
Redondances et anomalies de la base de données
Lors de la modification d'une entité dans une table avec des redondances , vous devez modifier toutes les instances répétées d'informations et toute autre information liée aux données modifiées. Sinon, la base de données devient incohérente et anomalies se produire lors de modifications.
Par exemple, dans le tableau non normalisé suivant :

Le tableau contient des données de redondance , qui à son tour provoque trois anomalies lors de modifications de données :
1. Insérer une anomalie . Lorsque vous essayez d'insérer un nouvel employé dans le secteur des finances, vous devez également connaître le nom du gestionnaire. Sinon, vous ne pouvez pas insérer de données dans le tableau.
2. Mettre à jour l'anomalie. Si un employé change de secteur, le nom du responsable finit par être incorrect. Par exemple, si Jacob passe à la finance, Adam reste son manager.
3. Supprimer l'anomalie . Si Joshua décide de quitter l'entreprise, la suppression de la ligne supprime également l'information indiquant qu'un secteur financier existe.
La solution à ces anomalies réside dans la normalisation de la base de données concepts et étapes.
Concepts de normalisation de base de données
Les concepts élémentaires utilisés dans la normalisation de bases de données sont :
- Clés . Attributs de colonne qui identifient un enregistrement de base de données de manière unique.
- Dépendances fonctionnelles . Contraintes entre deux attributs dans une relation.
- Formes normales . Étapes pour atteindre une certaine qualité d'une base de données.
Formulaires normaux de la base de données
La normalisation d'une base de données est réalisée grâce à un ensemble de règles appelées formes normales . Le concept central est d'aider un concepteur de base de données à atteindre la qualité souhaitée d'une base de données relationnelle.
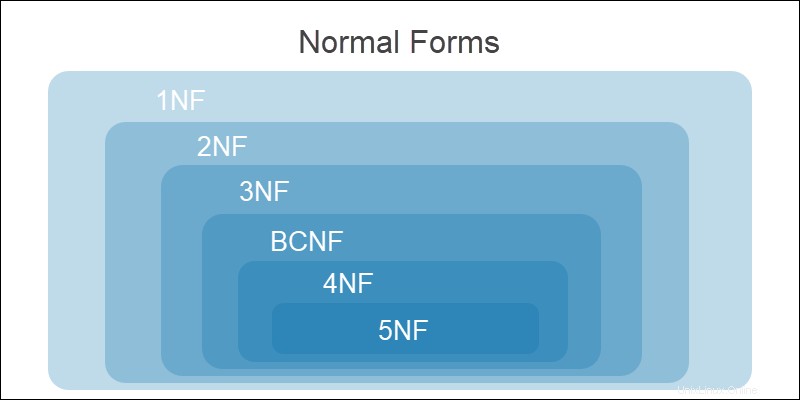
Tous les niveaux de normalisation sont cumulatifs. Les exigences de la forme normale précédente doivent être satisfaites avant de passer au formulaire suivant.
Les étapes de normalisation sont :
| Étape | Anomalies de redondance traitées |
|---|---|
| Forme non normalisée (UNF) | L'état avant toute normalisation. Des valeurs redondantes et complexes sont présentes. |
| Première forme normale (1NF) | Les valeurs répétitives et complexes se séparent, rendant toutes les instances atomiques. |
| Seconde forme normale (2NF) | Les dépendances partielles se décomposent en nouvelles tables. Toutes les lignes dépendent fonctionnellement de la clé primaire. |
| Troisième forme normale (3NF) | Les dépendances transitives se décomposent en de nouvelles tables. Les attributs non clés dépendent de la clé primaire. |
| Forme normale de Boyce-Codd (BCNF) | Les dépendances fonctionnelles transitives et partielles pour toutes les clés candidates se décomposent en de nouvelles tables. |
| Quatrième forme normale (4NF) | Suppression des dépendances à valeurs multiples. |
| Cinquième forme normale (5NF) | Suppression des dépendances JOIN. |
Une base de données est normalisée lorsqu'elle remplit la troisième forme normale . D'autres étapes de normalisation compliquent la conception de la base de données et pourraient compromettre la fonctionnalité du système.
Qu'est-ce qu'une CLÉ ?
Une clé de base de données est un attribut ou un groupe de fonctionnalités qui décrit de manière unique une entité dans une table. Les types de clés utilisées dans la normalisation sont :
- Super clé . Un ensemble de fonctionnalités qui définissent de manière unique chaque enregistrement dans une table.
- Clé du candidat . Clés sélectionnées dans l'ensemble de super clés où le nombre de champs est minimal.
- Clé primaire . Le choix le plus approprié parmi l'ensemble de clés candidates sert de clé primaire de la table.
- Clé étrangère . La clé primaire d'une autre table.
- Clé composite . Deux ou plusieurs attributs forment ensemble une clé unique mais ne sont pas des clés individuellement.
Au fur et à mesure que les tables se décomposent en plusieurs tables plus simples, les clés définissent un point de référence pour une entité de base de données.
Par exemple, dans la structure de base de données suivante :

Quelques exemples de super clés dans le tableau sont :
- identifiant d'employé
- (ID employé, nom)
- courriel
Toutes les super clés peuvent servir d'identifiant unique pour chaque ligne. D'autre part, le nom ou l'âge de l'employé ne sont pas des identifiants uniques car deux personnes peuvent avoir le même nom ou le même âge.
Les clés candidates proviennent de l'ensemble des super clés où le nombre de champs est minimal. Le choix se résume à deux options :
- identifiant d'employé
- courriel
Les deux options contiennent un nombre minimal de champs, ce qui en fait des clés candidates optimales. Le choix le plus logique pour la clé primaire est l'identifiant de l'employé car l'adresse e-mail d'un employé peut changer. La clé primaire dans le tableau est facile à référencer en tant que clé étrangère dans une autre table.
Dépendances fonctionnelles de la base de données
Une dépendance de base de données fonctionnelle représente une relation entre deux attributs dans une table de base de données. Certains types de dépendances fonctionnelles sont :
- Dépendance fonctionnelle triviale . Une dépendance entre un attribut et un groupe d'entités où l'élément d'origine se trouve dans le groupe.
- Dépendance fonctionnelle non triviale . Une dépendance entre un attribut et un groupe où la caractéristique n'est pas dans le groupe.
- Dépendance transitive. Une dépendance fonctionnelle entre trois attributs où le second dépend du premier et le troisième dépend du second. En raison de la transitivité, le troisième attribut dépend du premier.
- Dépendance multivaluée. Une dépendance où plusieurs valeurs dépendent d'un attribut.
Les dépendances fonctionnelles sont une étape essentielle dans la normalisation des bases de données. À long terme, les dépendances aident à déterminer la qualité globale d'une base de données.
Exemple de normalisation de base de données - Comment normaliser une base de données ?
Les étapes générales de la normalisation de base de données fonctionnent pour chaque base de données. Les étapes spécifiques de division de la table ainsi que le dépassement de 3NF dépendent du cas d'utilisation.
Exemple de base de données non normalisée
Une table non normalisée a plusieurs valeurs dans un seul champ, ainsi que des informations redondantes dans le pire des cas.
Par exemple :
| ID du gestionnaire | nomdugestionnaire | zone | identifiant d'employé | EmployeeName | ID de secteur | nomSecteur |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Est | 1 2 | David D. Eugène E. | 4 3 | Finances L'informatique |
| 2 | Betty B. | Ouest | 3 4 5 | Georges G. Henri H. Ingrid I. | 2 1 4 | Sécurité Administration Finances |
| 3 | Carl C. | Nord | 6 7 | James J. Katy K. | 1 4 | Administration Finances |
L'insertion, la mise à jour et la suppression de données est une tâche complexe. Toute modification du tableau existant présente un risque élevé de perte d'informations.
Étape 1 :Première forme normale 1NF
Pour retravailler la table de base de données dans le 1NF, les valeurs d'un même champ doivent être atomiques. Toutes les entités complexes du tableau se divisent en nouvelles lignes ou colonnes.
Les informations dans les colonnes managerID , nomdugestionnaire , et zone répéter pour chaque employé pour s'assurer qu'il n'y a aucune perte d'information.
| ID du gestionnaire | nomdugestionnaire | zone | identifiant d'employé | EmployeeName | ID de secteur | nomSecteur |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Est | 1 | David D. | 4 | Finance |
| 1 | Adam A. | Est | 2 | Eugène E. | 3 | informatique |
| 2 | Betty B. | Ouest | 3 | Georges G. | 2 | Sécurité |
| 2 | Betty B. | Ouest | 4 | Henry H. | 1 | Administration |
| 2 | Betty B. | Ouest | 5 | Ingrid I. | 4 | Finance |
| 3 | Carl C. | Nord | 6 | James J. | 1 | Administration |
| 3 | Carl C. | Nord | 7 | Katy K. | 4 | Finance |
Le tableau retravaillé satisfait la première forme normale.
Étape 2 :Deuxième forme normale 2NF
La deuxième forme normale dans la normalisation de la base de données stipule que chaque ligne de la table de la base de données doit dépendre de la clé primaire.
Le tableau se divise en deux tableaux pour satisfaire la forme normale :
- Gestionnaire (ID du gestionnaire, nom du gestionnaire, zone)
| ID du gestionnaire | nomdugestionnaire | zone |
|---|---|---|
| 1 | Adam A. | Est |
| 2 | Betty B. | Ouest |
| 3 | Carl C. | Nord |
- Employé (identifiant de l'employé, nom de l'employé, identifiant du responsable, identifiant du secteur, nom du secteur)
| identifiant d'employé | EmployeeName | ID du gestionnaire | ID de secteur | nomSecteur |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finance |
| 2 | Eugène E. | 1 | 3 | informatique |
| 3 | Georges G. | 2 | 2 | Sécurité |
| 4 | Henry H. | 2 | 1 | Administration |
| 5 | Ingrid I. | 2 | 4 | Finance |
| 6 | James J. | 3 | 1 | Administration |
| 7 | Katy K. | 3 | 4 | Finance |
La base de données résultante dans la deuxième forme normale est actuellement constituée de deux tables sans dépendances partielles.
Étape 3 :Troisième forme normale 3NF
La troisième forme normale décompose toutes les dépendances fonctionnelles transitives. Actuellement, la table Employé a une dépendance transitive qui se décompose en deux nouvelles tables :
- Employé (employeeID, employeeName, managerID, sectorID)
| identifiant d'employé | EmployeeName | ID du gestionnaire | ID de secteur |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugène E. | 1 | 3 |
| 3 | Georges G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Secteur (IDsecteur, nomSecteur)
| ID de secteur | nomSecteur |
|---|---|
| 1 | Administration |
| 2 | Sécurité |
| 3 | informatique |
| 4 | Finance |
La base de données est actuellement en troisième forme normale avec trois relations au total. La structure finale est :

À ce stade, la base de données est normalisée . Toute autre étape de normalisation dépend du cas d'utilisation des données.