Présentation
Lorsqu'il s'agit de choisir une base de données, l'une des décisions les plus importantes est de choisir entre une solution de base de données SQL ou NoSQL.
Dans cet article, vous découvrirez les principales différences entre les bases de données SQL et NoSQL. À la fin de cet article, vous serez en mesure de décider quel type de structure de base de données correspond le mieux à vos besoins.

Différences entre NoSQL et SQL
SQL signifie Langage de requête structuré. SQL est un langage standard pour stocker, manipuler et récupérer des données dans des systèmes de bases de données relationnelles.
NoSQL ou "non-SQL" est une base de données non relationnelle qui ne nécessite pas de schéma fixe et est facile à mettre à l'échelle.
Bien que les deux soient des options viables, il existe 11 différences clés entre elles que vous devez garder à l'esprit lorsque vous décidez.
| Comparer | SQL | NoSQL |
|---|---|---|
| Langage de requête | Langage de requête structuré (SQL) | Pas de langage de requête déclaratif |
| Type de base de données | Table | Valeur-clé, document, colonne large et graphique |
| Schéma | Prédéfini | Dynamique |
| Modèle de données | Relationnel | Non relationnel |
| Gestion de base de données populaire systèmes | MySQL, PostgreSQL, Oracle et MS-SQL | MongoDB, Apache HBase, Amazon DynamoDB, Redis, Couchbase, Cassandra et Elasticsearch |
| Capacité à évoluer | Vertical | Horizontal |
| Matériel | Matériel de base de données spécialisé (Oracle Exadata, etc.) | Matériel de base |
| ACIDE contre BASE | ACIDE | BASE |
| Open-source | Un mélange d'open-source comme Postgres et MySQL, et commercial comme Oracle Database. | Open source |
| Avantages | Support multiplateforme, sécurisé et gratuit | Outil facile à utiliser, performant et flexible |
| Inconvénients | Complexes à maintenir et inefficaces pour le traitement de données volumineuses, les systèmes de bases de données relationnelles complexes sont difficiles à exporter vers d'autres systèmes, ne sont pas bons pour gérer divers types de données | Les données sont moins structurées, les bases de données NoSQL ne sont pas aussi fiables (pas de support ACID), les bases de données NoSQL sont plus récentes et peuvent offrir moins de fonctionnalités que leurs homologues SQL |
| Cas d'utilisation | Prise en charge d'ACID, requêtes complexes, aucun changement ni croissance | Données en temps réel, volumes de données sans structure, entreprise agile, cloud computing |
Types de bases de données
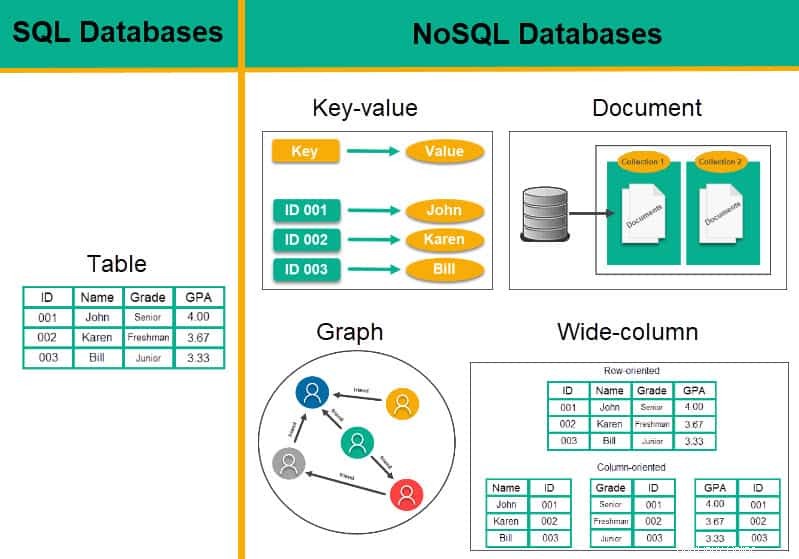
Les types de bases de données dépendent de la manière dont les données sont stockées.
- SQL dispose d'une base de données basée sur des tables . La base de données de table stocke les données dans des tables avec des lignes et des colonnes fixes.
NoSQL a 4 types de bases de données :
- Base de données de valeurs-clés – Stocke chaque élément de données sous la forme d'un nom d'attribut ou d'une clé avec sa valeur.
- Base de données de documents :stocke les données dans des documents JSON, BSON ou XML.
- Base de données à colonnes étendues – Stocke et regroupe les données dans des colonnes au lieu de lignes.
- Base de données de graphes :optimisée pour capturer et rechercher les connexions entre les éléments de données.
Remarque : Pour en savoir plus sur les types de bases de données NoSQL, consultez notre article sur les types de bases de données NoSQL.
Schéma
Un schéma de base de données est une structure qui définit la façon dont une base de données est construite. Il définit comment les données sont organisées et comment les relations entre les données sont associées. Il existe deux types de schémas :
- Prédéfini
- Dynamique
SQL a besoin d'un schéma prédéfini pour les données non structurées. Vous devez prédéfinir la structure des données sous forme de tables avant de commencer à utiliser SQL pour manipuler les données.
Cependant, une base de données NoSQL ne nécessite pas de schéma prédéfini. NoSQL utilise un schéma dynamique pour les données non structurées. Un schéma dynamique permet de stocker des données avant d'appliquer le schéma. Le schéma dépend entièrement de la manière dont vous souhaitez stocker les données.
Remarque : Découvrez comment fonctionnent les bases de données NoSQL dans notre article Qu'est-ce que NoSQL.
Modèle de données
Le modèle de données montre la structure logique de la base de données. Il organise les éléments de données et normalise la manière dont ils sont liés les uns aux autres. Il existe deux types de modèles de données :
- Relationnel
- Non relationnel
Nous pouvons observer des différences entre ces modèles de données en examinant les multiples entités. Prenons l'exemple d'une commande d'un restaurant et de deux entités :Commande et Adresse de livraison.
SQL utilise un modèle de données relationnel. Le modèle relationnel SQL utilise une relation plusieurs à plusieurs. Dans une relation plusieurs-à-plusieurs, une seule ligne de commande peut être liée à plusieurs lignes d'adresse de livraison. De même, chaque ligne d'adresse de livraison peut concerner plusieurs lignes de commande.
NoSQL utilise un modèle de données non relationnel qui n'utilise pas de relations. Les bases de données NoSQL dénormalisent les données en dupliquant l'adresse de livraison dans chaque ligne de commande contenant cette adresse de livraison. Par conséquent, les données sont stockées plusieurs fois. Cela facilite le stockage et la récupération des données et augmente la vitesse de la requête. En savoir plus sur les techniques de modélisation de base de données NoSQL.
Capacité à évoluer
L'évolutivité de la base de données est la capacité à contenir des quantités croissantes de données sans sacrifier les performances. Il existe deux types d'évolutivité :
- Vertical
- Horizontale
Les bases de données SQL sont évolutives verticalement . Dans la mise à l'échelle verticale, les données résident sur un seul nœud, et la seule façon d'évoluer est d'ajouter plus de ressources matérielles, telles que le processeur et la RAM, à une machine existante. Cela rend la mise à l'échelle verticale plus coûteuse. Un inconvénient supplémentaire de la mise à l'échelle verticale est qu'elle s'exécute sur une seule machine, donc si le serveur tombe en panne, votre application tombera également en panne.
Les bases de données NoSQL sont évolutives horizontalement . Dans la mise à l'échelle horizontale, chaque nœud ne contient qu'une partie des données, ce qui vous permet d'ajouter plus de machines au groupe existant de systèmes distribués. Cela rend la mise à l'échelle horizontale moins chère et plus rapide.
ACIDE contre BASE
Les modèles de cohérence les plus courants sont ACID et Base .

Les bases de données SQL utilisent l'ACID modèle de cohérence. ACIDE signifie :
- Atomique – Toutes les opérations d'une transaction réussissent ou chaque opération est annulée. Le succès partiel n'est pas autorisé.
- Cohérent – Chaque transaction fait passer la base de données d'un état valide à un autre. La transaction ne peut pas laisser la base de données dans un état incohérent.
- Isolé – Les transactions ne peuvent pas interférer les unes avec les autres.
- Durable – Les résultats de l'application d'une transaction sont permanents, même en présence d'échecs.
La principale caractéristique du modèle ACID est la cohérence. Lorsque vous effectuez une transaction, ses données sont cohérentes et stables.
Les bases de données NoSQL utilisent la BASE modèle de cohérence. BASE signifie :
- Disponible en principe – Tous les utilisateurs peuvent effectuer une requête. La base de données répartit les données sur plusieurs systèmes, de sorte qu'en cas de défaillance d'un segment de données, la base de données ne subira pas de panne complète.
- État logiciel – L'état de la base de données peut changer avec le temps.
- Cohérence éventuelle – Si le système fonctionne et que nous attendons assez longtemps, la base de données finira par devenir cohérente.
L'avantage du modèle de cohérence BASE est que les transactions sont validées plus rapidement. Les bases de données qui utilisent le modèle BASE préfèrent la disponibilité à la cohérence des données répliquées.
En savoir plus sur les deux modèles de transaction de base de données les plus populaires et leurs différences dans l'article ACID vs BASE.
Cas d'utilisation
Toutes les bases de données ne répondent pas à tous les besoins de l'entreprise. Examinons de plus près les cas d'utilisation des deux types de bases de données.
Raisons d'utiliser une base de données SQL :
- Lorsque vous avez besoin de l'assistance ACID – Avec la prise en charge d'ACID, vous bénéficiez de la cohérence et de l'intégrité des données à 100 %.
- Lorsque vous travaillez avec des requêtes et des rapports complexes – SQL est mieux adapté aux environnements de requêtes complexes que NoSQL.
- Lorsque vous ne prévoyez pas beaucoup de changements ou de croissance – Si votre entreprise ne connaît pas une croissance exponentielle, il n'y a aucune raison d'utiliser un système conçu pour prendre en charge une augmentation du volume de données.
Raisons d'utiliser une base de données NoSQL :
- Lorsque vous avez besoin de données en temps réel – NoSQL ne nécessite pas de schémas, ce qui accélère le processus d'information.
- Lorsque vous stockez des volumes de données sans structure – NoSQL prend en charge tous les types de données.
- Lorsque vous dirigez une entreprise agile – NoSQL ne nécessite pas de processus de préparation, ce qui réduit les temps d'arrêt.
- Lorsque vous souhaitez tirer le meilleur parti du cloud computing et du stockage – Pour qu'une solution cloud soit évolutive, les données doivent être faciles à partager sur plusieurs serveurs.
Systèmes de gestion de base de données populaires
Examinons de plus près les systèmes de gestion de base de données les plus populaires pour les types de bases de données relationnelles et NoSQL.
Top 5 des systèmes de gestion de bases de données SQL
- MySQL – La base de données est personnalisable et fonctionne sous Linux, Windows, OS X, FreeBSD et Solaris. Les principales caractéristiques sont un grand nombre de didacticiels et d'informations en ligne, sa capacité de partitionnement et de réplication, Xpath et une recherche en texte intégral.
- Oracle – C'est le meilleur système pour toute application commerciale critique. Les principales fonctionnalités sont la gestion automatique de la mémoire, du stockage et des annulations, Data Guard pour la base de données de secours, la base de données privée virtuelle et le Real Application Cluster (RAC). L'inconvénient est qu'Oracle n'est pas open source.
- PostgreSQL – Il fonctionne sous Linux, Windows et OS X. Les principales fonctionnalités sont la récupération ponctuelle, les clés étrangères, la prise en charge des espaces de table et la réplication asynchrone.
- SQLite – Ce SGBDR est écrit en langage C. SQLite n'est pas un moteur de base de données client-serveur. Il s'agit d'un moteur de base de données SQL autonome et sans serveur. Les principales caractéristiques sont un temps de réponse rapide, l'absence de dépendances externes et la prise en charge de bases de données de plusieurs To. SQLite ne nécessite aucune configuration, sans tâches de configuration ou d'administration, et l'intégralité de la base de données est stockée dans un seul fichier sur disque.
- Microsoft SQL Server – Il est limité à Windows, mais c'est un avantage si votre organisation utilise des produits Microsoft. Les principales fonctionnalités sont les hautes performances, la dépendance à la plate-forme et la réduction des problèmes de base de données temporaires.
Top 5 des systèmes de gestion de bases de données NoSQL
- MongoDB – Il s'agit d'un système open source évolutif et accessible. Il est écrit en C++. Il offre des performances élevées car il peut s'exécuter sur plusieurs serveurs et les données sont stockées au format JSON.
- Cassandre – Système de gestion de très grandes quantités de données structurées sur plusieurs serveurs de base. Il est écrit en Java. Les principales caractéristiques sont l'évolutivité linéaire, le temps de réponse rapide et la flexibilité. Cassandra prend en charge MapReduce avec Apache Hadoop et l'architecture peer-to-peer.
- Couchbase – Système utilisé pour les applications Web interactives. Les principales fonctionnalités de Couchbase sont la compression des données, le partitionnement d'index et la prise en charge de JSON.
- Amazon DynamoDB – Système qui permet tous les types de modèles de données. La mise à l'échelle est gérée par Amazon. Les fonctionnalités clés sont une évolutivité élevée, le stockage des données dans des partitions, l'utilisation de JSON comme protocole de transport et la réduction de la complexité.
- Redis – Redis est un magasin clé-valeur écrit en langage C. Les principales fonctionnalités sont le basculement automatique, les clés à durée de vie limitée et la prise en charge de divers types de données.
Remarque : En savoir plus sur les différences entre MongoDB et Cassandra dans notre article de comparaison.