Ici, nous verrons comment installer Apache Spark sur Ubuntu 20.04 ou 18.04, les commandes seront applicables pour Linux Mint, Debian et d'autres systèmes Linux similaires.
Apache Spark est un outil de traitement de données à usage général appelé moteur de traitement de données. Utilisé par les ingénieurs de données et les scientifiques des données pour effectuer des requêtes de données extrêmement rapides sur de grandes quantités de données de l'ordre du téraoctet. Il s'agit d'un framework pour les calculs basés sur les clusters qui rivalise avec le classique Hadoop Map/Reduce en utilisant la RAM disponible dans le cluster pour une exécution plus rapide des tâches.
De plus, Spark offre également la possibilité de contrôler les données via SQL, de les traiter en streaming en (quasi) temps réel, et fournit sa propre base de données de graphes et une bibliothèque d'apprentissage automatique. Le framework offre des technologies en mémoire à cet effet, c'est-à-dire qu'il peut stocker des requêtes et des données directement dans la mémoire principale des nœuds du cluster.
Apache Spark est idéal pour traiter rapidement de grandes quantités de données. Le modèle de programmation de Spark est basé sur Resilient Distributed Datasets (RDD), une classe de collecte qui fonctionne distribuée dans un cluster. Cette plate-forme open source prend en charge une variété de langages de programmation tels que Java, Scala, Python et R.
Étapes d'installation d'Apache Spark sur Ubuntu 20.04
Les étapes indiquées ici peuvent être utilisées pour d'autres versions d'Ubuntu telles que 21.04/18.04, y compris sur Linux Mint, Debian et Linux similaire.
1. Installer Java avec d'autres dépendances
Ici, nous installons la dernière version disponible de Jave qui est requise par Apache Spark ainsi que d'autres choses - Git et Scala pour étendre ses capacités.
sudo apt install default-jdk scala git
2. Télécharger Apache Spark sur Ubuntu 20.04
Maintenant, visitez le site officiel de Spark et téléchargez la dernière version disponible de celui-ci. Cependant, lors de la rédaction de ce didacticiel, la dernière version était la 3.1.2. Par conséquent, ici, nous téléchargeons le même, au cas où il serait différent lorsque vous effectuez l'installation de Spark sur votre système Ubuntu, allez-y. Copiez simplement le lien de téléchargement de cet outil et utilisez-le avec wget ou téléchargez directement sur votre système.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Extraire Spark vers /opt
Pour nous assurer que nous ne supprimons pas accidentellement le dossier extrait, plaçons-le dans un endroit sûr, c'est-à-dire /opt répertoire.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Modifiez également l'autorisation du dossier afin que Spark puisse écrire à l'intérieur.
sudo chmod -R 777 /opt/spark
4. Ajouter le dossier Spark au chemin système
Maintenant que nous avons déplacé le fichier vers /opt répertoire, pour exécuter la commande Spark dans le terminal, nous devons mentionner son chemin complet à chaque fois, ce qui est ennuyeux. Pour résoudre ce problème, nous configurons des variables d'environnement pour Spark en ajoutant ses chemins d'accès personnels au fichier profile/bashrc du système. Cela nous permet d'exécuter ses commandes depuis n'importe où dans le terminal, quel que soit le répertoire dans lequel nous nous trouvons.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Recharger le shell :
source ~/.bashrc
5. Démarrer le serveur maître Apache Spark sur Ubuntu
Comme nous avons déjà configuré l'environnement de variables pour Spark, démarrons maintenant son serveur maître autonome en exécutant son script :
start-master.sh
Modifier l'interface utilisateur Web Spark Master et le port d'écoute (facultatif, à utiliser uniquement si nécessaire)
Si vous souhaitez utiliser un port personnalisé, il est possible d'utiliser les options ou les arguments indiqués ci-dessous.
–port – Port d'écoute du service (par défaut :7077 pour le maître, aléatoire pour le travailleur)
–webui-port – Port pour l'interface utilisateur Web (par défaut :8080 pour le maître, 8081 pour le travailleur)
Exemple – Je souhaite exécuter l'interface utilisateur Web Spark sur 8082 et le faire écouter sur le port 7072, puis la commande pour le démarrer ressemblera à ceci :
start-master.sh --port 7072 --webui-port 8082
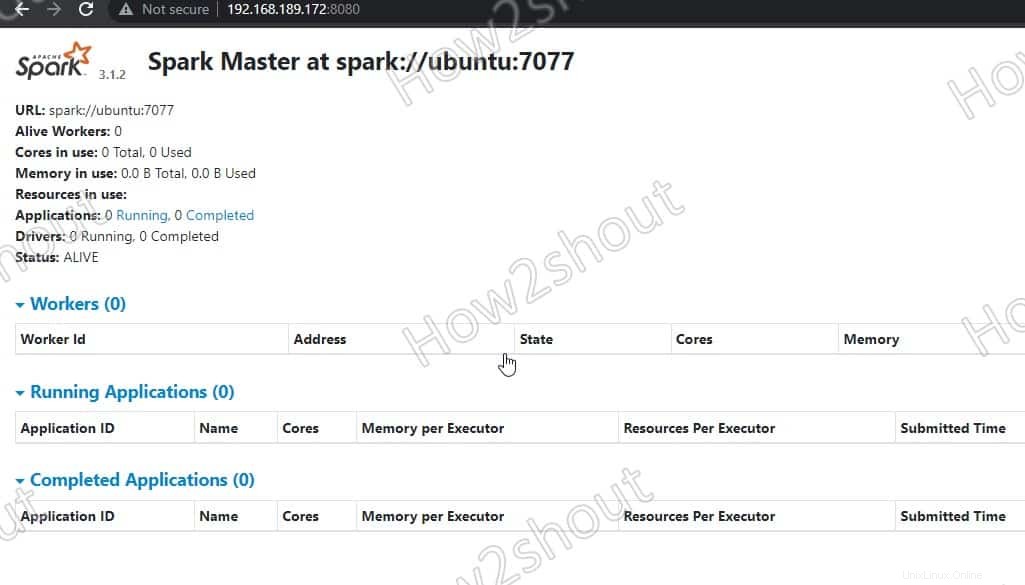
6. Accéder à Spark Master (spark://Ubuntu:7077) – Interface Web
Maintenant, accédons à l'interface Web du serveur maître Spark qui s'exécute au numéro de port 8080 . Donc, dans votre navigateur, ouvrez http://127.0.0.1:8080 .
Notre maître tourne sur spark://Ubuntu :7077, où Ubuntu est le nom d'hôte du système et pourrait être différent dans votre cas.
Si vous utilisez un serveur CLI et que vous souhaitez utiliser le navigateur de l'autre système qui peut accéder à l'adresse IP du serveur, pour ce premier ouvrez 8080 dans le pare-feu. Cela vous permettra d'accéder à distance à l'interface Web de Spark à - http://your-server-ip-addres:8080
sudo ufw allow 8080
7. Exécuter le script de travail esclave
Pour exécuter Spark slave worker, nous devons lancer son script disponible dans le répertoire que nous avons copié dans /opt . La syntaxe de la commande sera :
Syntaxe de la commande :
start-worker.sh spark://hostname:port
Dans la commande ci-dessus, modifiez le nom d'hôte et port . Si vous ne connaissez pas votre nom d'hôte, tapez simplement - hostname en terminale. Où le port par défaut de maître s'exécute sur est 7077, vous pouvez voir dans la capture d'écran ci-dessus .
Ainsi, comme notre nom d'hôte est ubuntu, la commande ressemblera à ceci :
start-worker.sh spark://ubuntu:7077
Actualiser l'interface Web et vous verrez l'ID de travailleur et la quantité de mémoire qui lui est alloué :
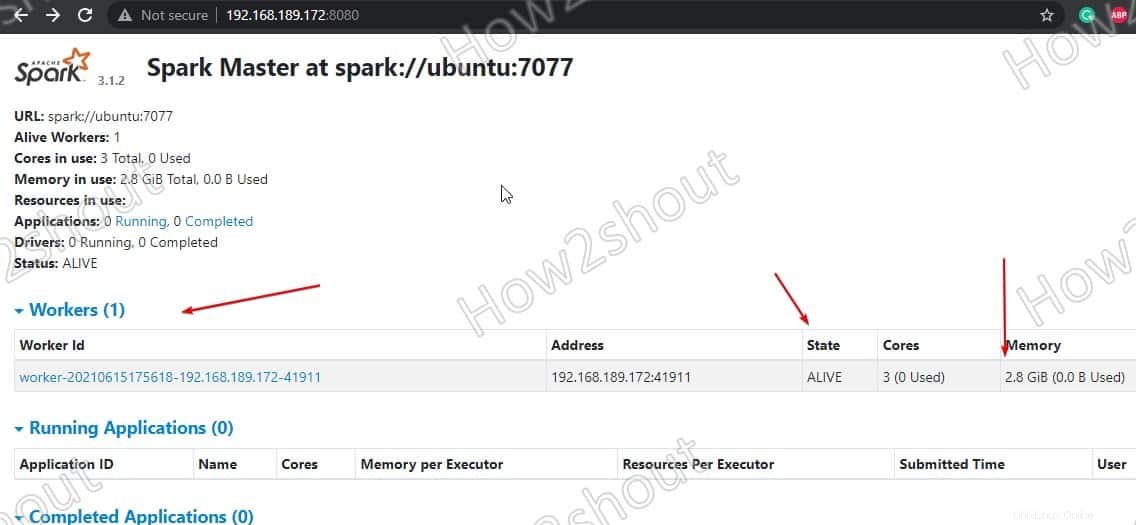
Si vous le souhaitez, vous pouvez modifier la mémoire/ram allouée au travailleur. Pour cela, vous devez redémarrer le worker avec la quantité de RAM que vous souhaitez lui fournir.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Utiliser Spark Shell
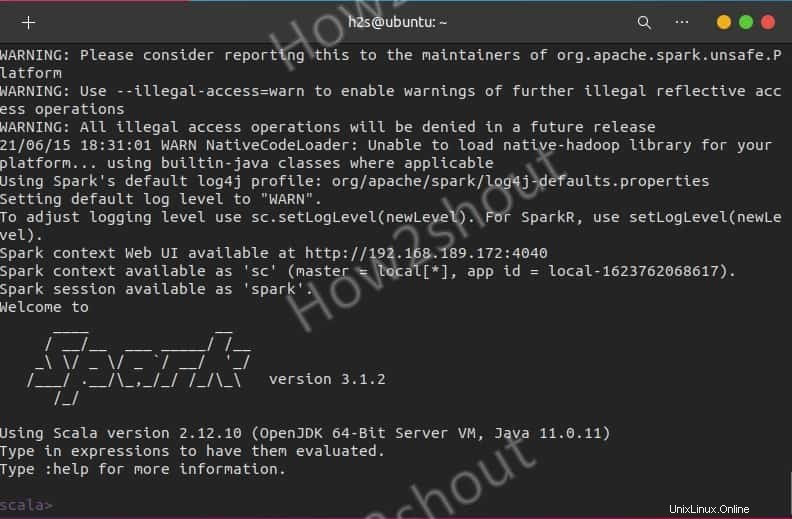
Ceux qui veulent utiliser le shell Spark pour commencer à programmer peuvent y accéder en tapant directement :
spark-shell
Pour voir les options prises en charge, tapez- :help et pour quitter le shell, utilisez - :quite
Pour commencer avec le shell Python au lieu de Scala, utilisez :
pyspark
Commandes de démarrage et d'arrêt du serveur
Si vous voulez démarrer ou arrêter maître/travailleurs instances, puis utilisez les scripts correspondants :
stop-master.sh stop-worker.sh
Pour tout arrêter d'un coup
stop-all.sh
Ou commencez tout d'un coup :
start-all.sh
Fin des pensées :
De cette façon, nous pouvons installer et commencer à utiliser Apache Spark sur Ubuntu Linux. Pour en savoir plus, vous pouvez vous référer à la documentation officielle . Cependant, comparé à Hadoop, Spark est encore relativement jeune, vous devez donc compter avec quelques aspérités. Cependant, il a déjà fait ses preuves à plusieurs reprises dans la pratique et permet de nouveaux cas d'utilisation dans le domaine des données volumineuses ou rapides grâce à l'exécution rapide des tâches et à la mise en cache des données. Et enfin, il offre une API uniforme pour les outils qui devraient autrement être exploités et exploités séparément dans l'environnement Hadoop.