Présentation
Apache Hadoop est un cadre exceptionnellement réussi qui parvient à résoudre les nombreux défis posés par le Big Data. Cette solution efficace répartit la puissance de stockage et de traitement sur des milliers de nœuds au sein d'un cluster. Une plate-forme Hadoop entièrement développée comprend une collection d'outils qui améliorent le framework Hadoop principal et lui permettent de surmonter n'importe quel obstacle.
L'architecture sous-jacente et le rôle des nombreux outils disponibles dans un écosystème Hadoop peuvent s'avérer compliqués pour les nouveaux arrivants.
Cet article utilise de nombreux diagrammes et des descriptions simples pour vous aider à explorer l'écosystème passionnant d'Apache Hadoop.

Présentation de l'architecture Hadoop
Les données volumineuses, avec leur volume immense et leurs structures de données variables, ont dépassé les cadres et outils de mise en réseau traditionnels. L'utilisation de matériel performant et de serveurs spécialisés peut aider, mais ils manquent de flexibilité et ont un prix considérable.
Hadoop parvient à traiter et à stocker de grandes quantités de données en utilisant du matériel de base abordable et interconnecté. Des centaines, voire des milliers de serveurs dédiés à faible coût travaillant ensemble pour stocker et traiter les données au sein d'un écosystème unique.
Le système de fichiers distribué Hadoop (HDFS), YARN , et MapReduce sont au cœur de cet écosystème. HDFS est un ensemble de protocoles utilisés pour stocker de grands ensembles de données, tandis que MapReduce traite efficacement les données entrantes.
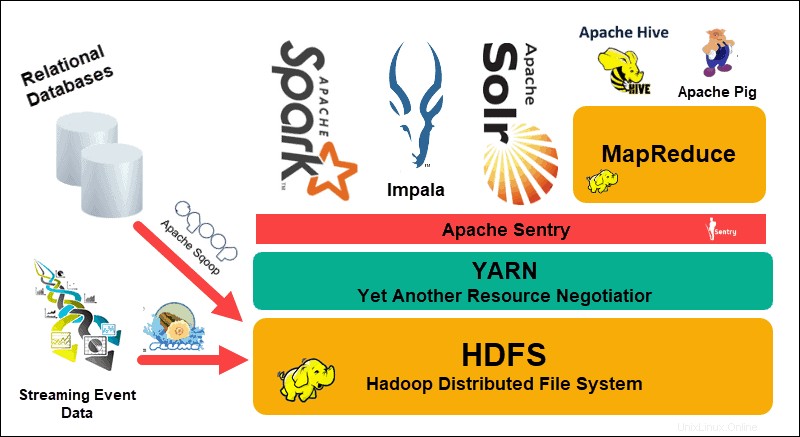
Un cluster Hadoop se compose d'un ou plusieurs nœuds maîtres et de nombreux autres nœuds dits esclaves. HDFS et MapReduce forment une base flexible qui peut évoluer de manière linéaire en ajoutant des nœuds supplémentaires. Cependant, la complexité du Big Data signifie qu'il y a toujours place à l'amélioration.
Encore un autre négociateur de ressources (YARN) a été créé pour améliorer la gestion des ressources et les processus de planification dans un cluster Hadoop. L'introduction de YARN, avec son interface générique, a ouvert la porte à l'intégration d'autres outils de traitement de données dans l'écosystème Hadoop.
Une communauté de développeurs dynamique a depuis créé de nombreux projets Apache open source pour compléter Hadoop. Beaucoup de ces solutions ont des noms accrocheurs et créatifs tels que Apache Hive, Impala, Pig, Sqoop, Spark et Flume. Ces outils compilent et traitent divers types de données. Ils fournissent également des interfaces conviviales, des services de messagerie et améliorent les vitesses de traitement des clusters.
Une pile logicielle étendue, avec HDFS, YARN et MapReduce en son cœur, fait de Hadoop la solution incontournable pour le traitement du Big Data.
Comprendre les couches de l'architecture Hadoop
La séparation des éléments des systèmes distribués en couches fonctionnelles permet de rationaliser la gestion et le développement des données. Les développeurs peuvent travailler sur des frameworks sans impact négatif sur les autres processus de l'écosystème au sens large.
Hadoop peut être divisé en quatre (4) couches distinctes.
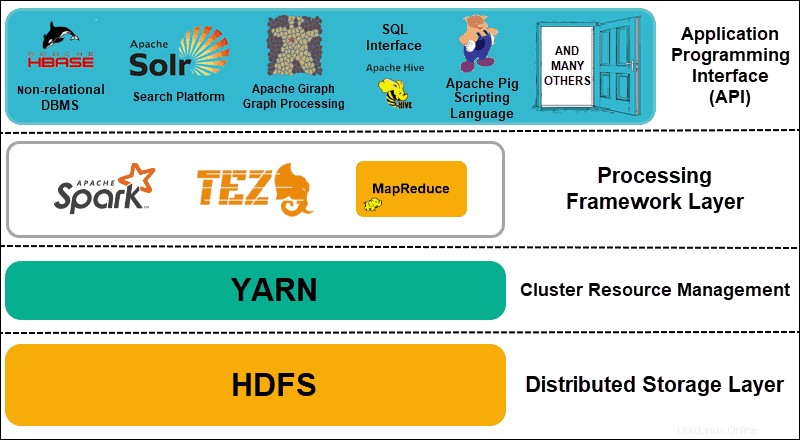
1. Couche de stockage distribué
Chaque nœud d'un cluster Hadoop dispose de son propre espace disque, mémoire, bande passante et traitement. Les données entrantes sont divisées en blocs de données individuels, qui sont ensuite stockés dans la couche de stockage distribué HDFS. HDFS suppose que chaque lecteur de disque et nœud esclave du cluster n'est pas fiable. Par mesure de précaution, HDFS stocke trois copies de chaque ensemble de données dans le cluster. Le nœud maître HDFS (NameNode ) conserve les métadonnées du bloc de données individuel et de toutes ses répliques.
2. Gestion des ressources du cluster
Hadoop doit parfaitement coordonner les nœuds afin que d'innombrables applications et utilisateurs partagent efficacement leurs ressources. Initialement, MapReduce gérait à la fois la gestion des ressources et le traitement des données. YARN sépare ces deux fonctions. En tant qu'outil de gestion des ressources de facto pour Hadoop, YARN est désormais capable d'allouer des ressources à différents frameworks écrits pour Hadoop. Ceux-ci incluent des projets tels que Apache Pig, Hive, Giraph, Zookeeper, ainsi que MapReduce lui-même.
3. Couche d'infrastructure de traitement
La couche de traitement se compose de cadres qui analysent et traitent les ensembles de données entrant dans le cluster. Les ensembles de données structurés et non structurés sont mappés, mélangés, triés, fusionnés et réduits en blocs de données gérables plus petits. Ces opérations sont réparties sur plusieurs nœuds aussi proches que possible des serveurs où se trouvent les données. Les cadres de calcul tels que Spark, Storm, Tez permettent désormais le traitement en temps réel, le traitement interactif des requêtes et d'autres options de programmation qui aident le moteur MapReduce et utilisent HDFS beaucoup plus efficacement.
4. Interface de programmation d'applications
L'introduction de YARN dans Hadoop 2 a conduit à la création de nouveaux frameworks de traitement et API. Le Big Data continue de se développer et la variété des outils doit suivre cette croissance. Les projets axés sur les plates-formes de recherche, le streaming de données, les interfaces conviviales, les langages de programmation, la messagerie, les basculements et la sécurité font tous partie intégrante d'un écosystème Hadoop complet.
HDFS expliqué
Le système de fichiers distribués Hadoop (HDFS) est tolérant aux pannes de par sa conception. Les données sont stockées dans des blocs de données individuels en trois copies distinctes sur plusieurs nœuds et racks de serveurs. Si un nœud ou même un rack entier tombe en panne, l'impact sur l'ensemble du système est négligeable.
DataNodes traiter et stocker des blocs de données, tandis que NameNodes gérer les nombreux DataNodes, maintenir les métadonnées des blocs de données et contrôler l'accès client.
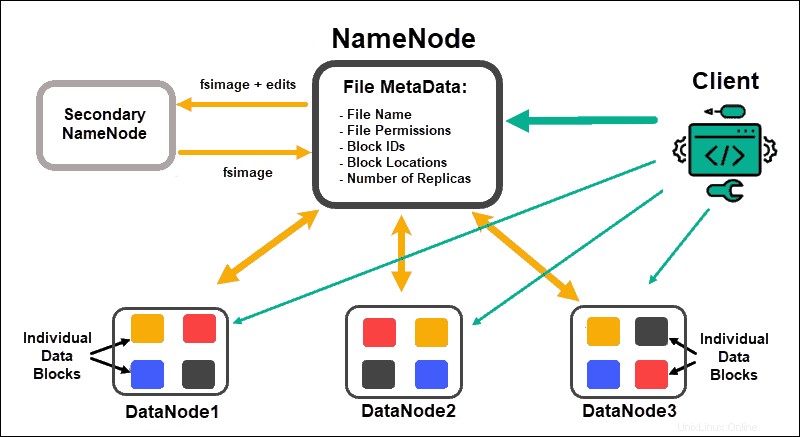
NomNoeud
Initialement, les données sont divisées en blocs de données abstraits. Les métadonnées de fichier pour ces blocs, qui incluent le nom de fichier, les autorisations de fichier, les ID, les emplacements et le nombre de répliques, sont stockées dans une fsimage, sur la mémoire locale du NameNode.
En cas de défaillance d'un NameNode, HDFS ne serait pas en mesure de localiser l'un des ensembles de données distribués dans les DataNodes. Cela fait du NameNode le point de défaillance unique pour l'ensemble du cluster. Cette vulnérabilité est résolue en implémentant un Second NameNode ou un Standby NameNode.
Noeud de nom secondaire
Le NameNode secondaire servait de solution de sauvegarde principale dans les premières versions de Hadoop. Le NameNode secondaire, de temps en temps, télécharge l'instance actuelle de fsimage et édite les journaux du NameNode et les fusionne. La fsimage modifiée peut ensuite être récupérée et restaurée dans le NameNode principal.
Le basculement n'est pas un processus automatisé car un administrateur aurait besoin de récupérer manuellement les données du nœud de nom secondaire.
Noeud de nom de secours
La haute disponibilité La fonctionnalité a été introduite dans Hadoop 2.0 et les versions ultérieures pour éviter tout temps d'arrêt en cas de défaillance du NameNode. Cette fonctionnalité vous permet de maintenir deux NameNodes exécutés sur des nœuds maîtres dédiés distincts.
Le Standby NameNode est un basculement automatique en cas d'indisponibilité d'un Active NameNode. Le Standby NameNode exécute en outre le processus de pointage de contrôle. En raison de cette propriété, les NameNode secondaire et de secours ne sont pas compatibles. Un cluster Hadoop peut maintenir l'un ou l'autre.
Gardien de zoo
Zookeeper est un outil léger qui prend en charge la haute disponibilité et la redondance. Un NameNode Standby maintient une session active avec le démon Zookeeper.
Si un NameNode actif échoue, le démon Zookeeper détecte l'échec et exécute le processus de basculement vers un nouveau NameNode. Utilisez Zookeeper pour automatiser les basculements et minimiser l'impact qu'une défaillance de NameNode peut avoir sur le cluster.
Noeud de données
Chaque DataNode d'un cluster utilise un processus d'arrière-plan pour stocker les blocs de données individuels sur des serveurs esclaves.
Par défaut, HDFS stocke trois copies de chaque bloc de données sur des DataNodes distincts. Le NameNode utilise une stratégie de placement adaptée au rack. Cela signifie que les DataNodes qui contiennent les répliques de blocs de données ne peuvent pas tous être situés sur le même rack de serveurs.
Un DataNode communique et accepte les instructions du NameNode environ vingt fois par minute. En outre, il signale l'état et la santé des blocs de données situés sur ce nœud une fois par heure. Sur la base des informations fournies, le NameNode peut demander au DataNode de créer des répliques supplémentaires, de les supprimer ou de réduire le nombre de blocs de données présents sur le nœud.
Politique de placement compatible avec le rack
L'un des principaux objectifs d'un système de stockage distribué tel que HDFS est de maintenir une haute disponibilité et une réplication. Par conséquent, les blocs de données doivent être distribués non seulement sur différents DataNodes, mais sur des nœuds situés sur différents racks de serveurs.
Cela garantit que la défaillance d'un rack entier ne met pas fin à toutes les répliques de données. Le NameNode HDFS maintient une politique de placement de réplica compatible avec le rack par défaut :
- Le premier réplica de bloc de données est placé sur le même nœud que le client.
- Le deuxième réplica est automatiquement placé sur un DataNode aléatoire sur un rack différent.
- Le troisième réplica est placé dans un DataNode séparé sur le même rack que le deuxième réplica.
- Toutes les répliques supplémentaires sont stockées sur des DataNodes aléatoires dans tout le cluster.
Cette politique de placement de rack ne maintient qu'une seule réplique par nœud et définit une limite de deux répliques par rack de serveur.
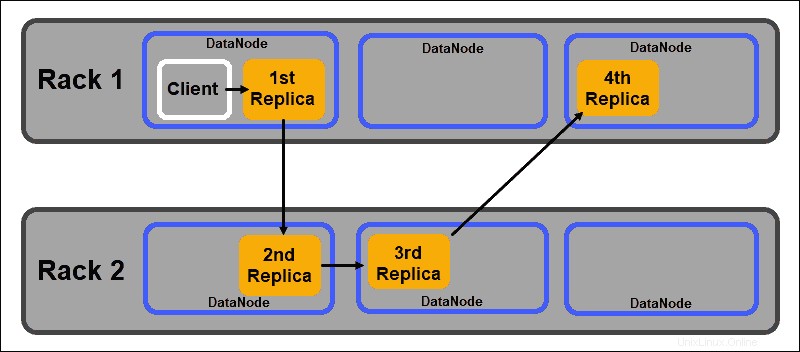
Les pannes de rack sont beaucoup moins fréquentes que les pannes de nœud. HDFS garantit une grande fiabilité en stockant toujours au moins une réplique de bloc de données dans un DataNode sur un rack différent.
LE FIL expliqué
YARN (Yet Another Resource Negotiator) est la ressource de gestion de cluster par défaut pour Hadoop 2 et Hadoop 3. Dans les versions précédentes de Hadoop, MapReduce effectuait à la fois le traitement des données et l'allocation des ressources. Au fil du temps, la nécessité de séparer le traitement et la gestion des ressources a conduit au développement de YARN.
Le rôle d'allocation des ressources de YARN le place entre la couche de stockage, représentée par HDFS, et le moteur de traitement MapReduce. YARN fournit également une interface générique qui vous permet d'implémenter de nouveaux moteurs de traitement pour différents types de données.
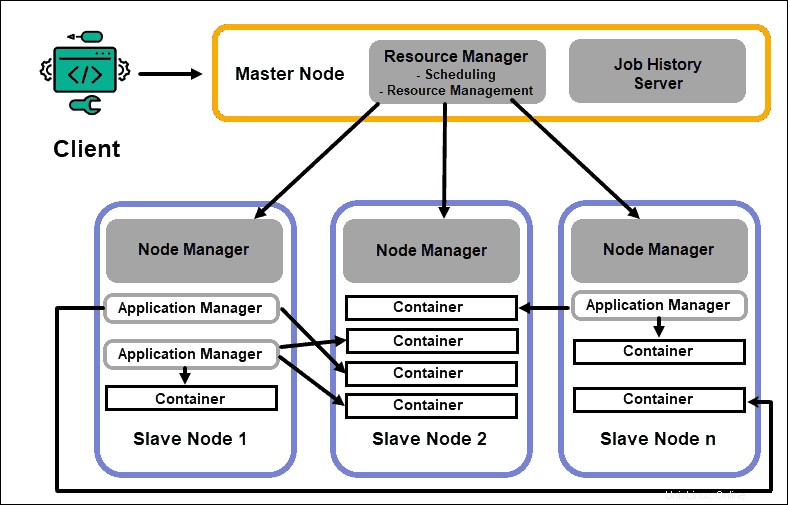
Gestionnaire de ressources
Le démon ResourceManager (RM) contrôle toutes les ressources de traitement dans un cluster Hadoop. Son objectif principal est de désigner des ressources pour des applications individuelles situées sur les nœuds esclaves. Il maintient une vue d'ensemble globale des processus en cours et planifiés, gère les demandes de ressources, et planifie et affecte les ressources en conséquence. Le ResourceManager est vital pour le framework Hadoop et doit s'exécuter sur un nœud maître dédié.
Le seul objectif de RM est de planifier les charges de travail. Contrairement à MapReduce, il n'a aucun intérêt pour les basculements ou les tâches de traitement individuelles. Cette séparation des tâches dans YARN est ce qui rend Hadoop intrinsèquement évolutif et en fait une plate-forme informatique entièrement développée.
Gestionnaire de nœuds
Chaque nœud esclave dispose d'un service de traitement NodeManager et d'un service de stockage DataNode. Ensemble, ils forment l'épine dorsale d'un système distribué Hadoop.
Le DataNode, comme mentionné précédemment, est un élément de HDFS et est contrôlé par le NameNode. Le NodeManager, de la même manière, agit comme un esclave du ResourceManager. La fonction principale du démon NodeManager est de suivre les données des ressources de traitement sur son nœud esclave et d'envoyer des rapports réguliers au ResourceManager.
Conteneurs
Les ressources de traitement d'un cluster Hadoop sont toujours déployées dans des conteneurs. Un conteneur contient de la mémoire, des fichiers système et un espace de traitement.
Un déploiement de conteneur est générique et peut exécuter n'importe quelle ressource personnalisée demandée sur n'importe quel système. Si une quantité demandée de ressources de cluster est dans les limites de ce qui est acceptable, le gestionnaire de ressources approuve et planifie le déploiement de ce conteneur.
Les processus de conteneur sur un nœud esclave sont initialement provisionnés, surveillés et suivis par le NodeManager sur ce nœud esclave spécifique.
Maître d'application
Chaque conteneur sur un nœud esclave a son maître d'application dédié. Les maîtres d'application sont également déployés dans un conteneur. Même MapReduce dispose d'un maître d'application qui exécute les tâches de mappage et de réduction.
Tant qu'il est actif, un maître d'application envoie des messages au gestionnaire de ressources concernant son état actuel et l'état de l'application qu'il surveille. Sur la base des informations fournies, le gestionnaire de ressources planifie des ressources supplémentaires ou les affecte ailleurs dans le cluster si elles ne sont plus nécessaires.
L'Application Master supervise le cycle de vie complet d'une application, depuis la demande des conteneurs nécessaires auprès du RM jusqu'à la soumission des demandes de location de conteneurs au NodeManager.
Serveur d'historique des travaux
Le JobHistory Server permet aux utilisateurs de récupérer des informations sur les applications qui ont terminé leur activité. L'API REST assure l'interopérabilité et peut informer dynamiquement les utilisateurs des travaux en cours et terminés servis par le serveur en question.
Comment fonctionne YARN ?
Un flux de travail de base pour le déploiement dans YARN démarre lorsqu'une application cliente soumet une demande au ResourceManager.
- Le gestionnaire de ressources ordonne à un NodeManager pour démarrer un Application Master pour cette requête, qui est ensuite lancée dans un conteneur.
- Le nouveau Application Master s'enregistre auprès du RM . L'Application Master contacte le HDFS NameNode et déterminer l'emplacement des blocs de données nécessaires et calculer la quantité de carte et réduire les tâches nécessaires pour traiter les données.
- Le maître d'application demande ensuite les ressources nécessaires au RM et continue de communiquer les besoins en ressources tout au long du cycle de vie du conteneur.
- Le MR planifie les ressources avec les demandes de tous les autres Application Masters et met leurs demandes en file d'attente. Au fur et à mesure que les ressources deviennent disponibles, le RM les met à la disposition du maître d'application sur un nœud esclave spécifique.
- Le gestionnaire d'applications contacte le NodeManager pour ce nœud esclave et lui demande de créer un conteneur en fournissant des variables, des jetons d'authentification et la chaîne de commande pour le processus. En fonction de cette requête, le NodeManager crée et démarre le conteneur .
- Le gestionnaire d'applications surveille ensuite le processus et réagit en cas d'échec en redémarrant le processus sur le prochain slot disponible. S'il échoue après quatre tentatives différentes, l'ensemble du travail échoue. Tout au long de ce processus, le gestionnaire d'application répond aux demandes d'état des clients.
Une fois toutes les tâches terminées, l'Application Master envoie le résultat à l'application cliente, informe le RM que l'application a terminé sa tâche, se désenregistre du Resource Manager et s'arrête.
Le RM peut également demander au NameNode de mettre fin à un conteneur spécifique pendant le processus en cas de changement de priorité de traitement.
MapReduce expliqué
MapReduce est un algorithme de programmation qui traite les données dispersées dans le cluster Hadoop. Comme pour tout processus dans Hadoop, une fois qu'une tâche MapReduce démarre, le ResourceManager demande à un maître d'application de gérer et de surveiller le cycle de vie de la tâche MapReduce.
Le maître d'application localise les blocs de données requis en fonction des informations stockées sur le NameNode. L'AM informe également le ResourceManager de démarrer une tâche MapReduce sur le même nœud sur lequel se trouvent les blocs de données. Dans la mesure du possible, les données sont traitées localement sur les nœuds esclaves pour réduire l'utilisation de la bande passante et améliorer l'efficacité du cluster.
Les données d'entrée sont mappées, mélangées, puis réduites à un résultat agrégé. La sortie de la tâche MapReduce est stockée et répliquée dans HDFS.
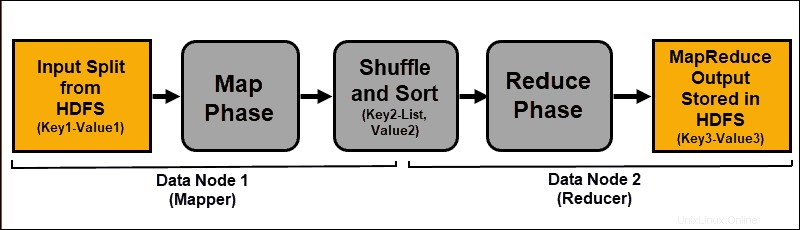
Les serveurs Hadoop qui effectuent les tâches de mappage et de réduction sont souvent appelés Mappeurs. et Réducteurs .
Le ResourceManager décide du nombre de mappeurs à utiliser. Cette décision dépend de la taille des données traitées et du bloc mémoire disponible sur chaque serveur mappeur.
Phase de carte
Le processus de mappage ingère des expressions logiques individuelles des données stockées dans les blocs de données HDFS. Ces expressions peuvent s'étendre sur plusieurs blocs de données et sont appelées divisions d'entrée . Les fractionnements d'entrée sont introduits dans le processus de mappage en tant que paires clé-valeur .
Une tâche de mappeur parcourt chaque paire clé-valeur et crée un nouvel ensemble de paires clé-valeur, distinct des données d'entrée d'origine. L'assortiment complet de toutes les paires clé-valeur représente la sortie de la tâche de mappage.
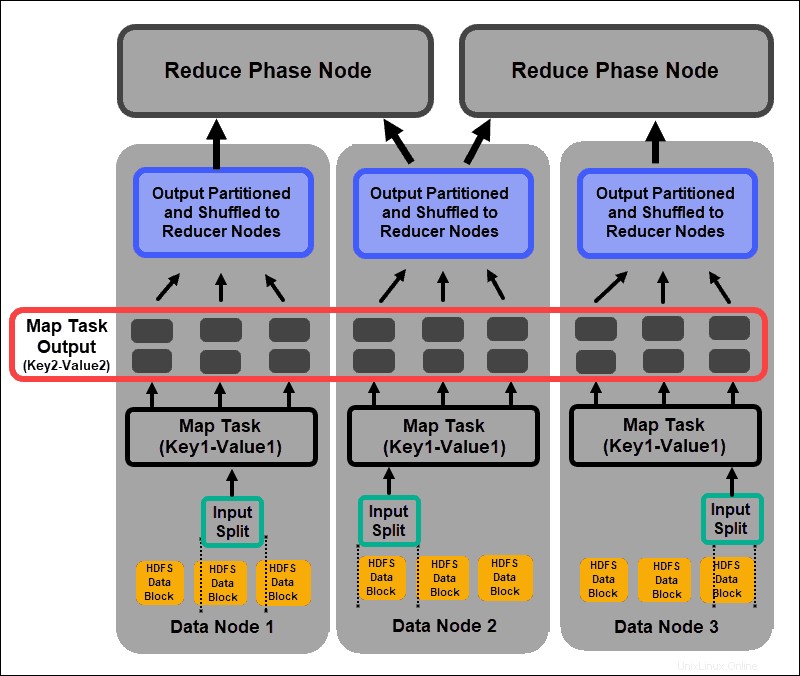
En fonction de la clé de chaque paire, les données sont regroupées, partitionnées et mélangées vers les nœuds réducteurs.
Phase de mélange et de tri
Mélange est un processus dans lequel les résultats de toutes les tâches de la carte sont copiés vers les nœuds réducteurs. La copie de la sortie de la tâche de carte est le seul échange de données entre les nœuds pendant toute la tâche MapReduce.
La sortie d'une tâche de carte doit être organisée pour améliorer l'efficacité de la phase de réduction. Les paires clé-valeur mappées, étant mélangées à partir des nœuds du mappeur, sont rangées par clé avec les valeurs correspondantes. Une phase de réduction commence une fois que l'entrée est triée par clé dans un seul fichier d'entrée.
Les phases de mélange et de tri se déroulent en parallèle. Même lorsque les sorties de la carte sont récupérées à partir des nœuds du mappeur, elles sont regroupées et triées sur les nœuds du réducteur.
Réduire la phase
Les sorties de la carte sont mélangées et triées dans un seul fichier d'entrée de réduction situé sur le nœud du réducteur. Une fonction de réduction utilise le fichier d'entrée pour agréger les valeurs en fonction des clés mappées correspondantes. La sortie du processus de réduction est une nouvelle paire clé-valeur. Ce résultat représente la sortie de l'ensemble du travail MapReduce et est, par défaut, stocké dans HDFS.
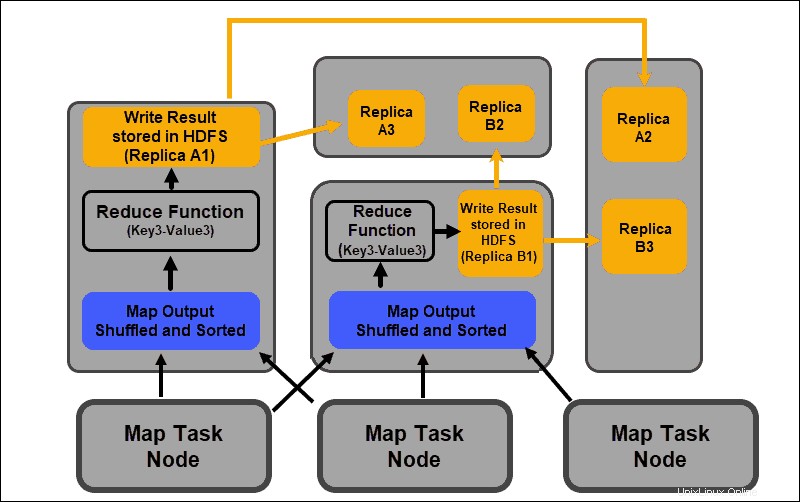
Toutes les tâches de réduction se déroulent simultanément et fonctionnent indépendamment les unes des autres. Une tâche de réduction est également facultative.
Il peut y avoir des cas où le résultat d'une tâche cartographique est le résultat souhaité et il n'est pas nécessaire de produire une seule valeur de sortie.
Meilleures pratiques pour le déploiement de Hadoop
La section suivante explique comment le matériel sous-jacent, les autorisations des utilisateurs et le maintien d'un cluster équilibré et fiable peuvent vous aider à tirer le meilleur parti de votre écosystème Hadoop.
Ajuster les autorisations des utilisateurs Hadoop
Le protocole réseau Kerberos est le principal système d'autorisation dans Hadoop. Il s'assure que seuls les nœuds et les utilisateurs vérifiés ont accès et fonctionnent au sein du cluster.
Une fois que vous avez installé et configuré un centre de distribution de clés Kerberos, vous devez apporter plusieurs modifications aux fichiers de configuration Hadoop. Hadoop core-site.xml Le fichier définit les paramètres pour l'ensemble du cluster Hadoop. Définissez le hadoop.security.authentication paramètre dans core-site.xml à kerberos . La même propriété doit être définie sur true pour activer l'autorisation de service.
Listes de contrôle d'accès dans hadoop-policy-xml Le fichier peut également être modifié pour accorder différents niveaux d'accès à des utilisateurs spécifiques. Trouver un équilibre entre les privilèges utilisateur nécessaires et donner trop de privilèges peut être difficile avec les outils de ligne de commande de base.
C'est une bonne idée d'utiliser des cadres de sécurité supplémentaires tels que Apache Ranger ou Apache Sentry . Ces outils vous aident à gérer toutes les tâches liées à la sécurité à partir d'un environnement central et convivial. Utilisez-les pour fournir une autorisation spécifique pour les tâches et les utilisateurs tout en gardant un contrôle total sur le processus.
Cluster Hadoop équilibré
Un système distribué comme Hadoop est un environnement dynamique. L'ajout de nouveaux nœuds ou la suppression d'anciens peut créer un déséquilibre temporaire au sein d'un cluster. Les blocs de données peuvent devenir sous-répliqués.
Votre objectif est de répartir les données de la manière la plus cohérente possible sur les nœuds esclaves d'un cluster. Utilisez l'utilitaire d'équilibrage de cluster Hadoop pour modifier les paramètres prédéfinis. Définissez votre politique d'équilibrage avec le hdfs balancer commande. Cette commande et ses options permettent de modifier les seuils de capacité disque des nœuds.
La taille de bloc par défaut à partir de Hadoop 2.x est de 128 Mo. Hadoop permet à un utilisateur de modifier ce paramètre. Envisagez de modifier la taille de bloc de données par défaut si vous traitez des quantités importantes de données ; sinon, le nombre de tâches démarrées pourrait submerger votre cluster.
Si vous augmentez la taille du bloc de données, l'entrée de la tâche de carte sera plus grande et il y aura moins de tâches de carte démarrées. Ceci, à son tour, signifie que la phase de brassage a un bien meilleur débit lors du transfert de données vers le nœud réducteur. Ce simple ajustement peut réduire le temps nécessaire à l'exécution d'une tâche MapReduce.
Mettre à l'échelle Hadoop (Matériel)
Le NameNode est un élément vital de votre cluster Hadoop. Engagez autant de cœurs de traitement que possible pour ce nœud. La quantité de RAM définit la quantité de données lues à partir de la mémoire du nœud. Si vous surchargez les ressources disponibles pour votre nœud maître, vous limitez la capacité de croissance de votre cluster.
Les alimentations redondantes doivent toujours être réservées au nœud maître. Essayez de ne pas utiliser d'alimentations redondantes et de précieuses ressources matérielles pour les nœuds de données. Ils sont une partie importante d'un écosystème Hadoop, cependant, ils sont consommables. Les serveurs dédiés abordables, avec des capacités de traitement intermédiaires, sont idéaux pour les nœuds de données car ils consomment moins d'énergie et produisent moins de chaleur.
Les capacités de mise à l'échelle de Hadoop sont le principal moteur de sa mise en œuvre généralisée. Il faut toujours avoir suffisamment d'espace pour que votre cluster puisse se développer. L'ajout rapide de nouveaux nœuds ou d'espace disque nécessite une alimentation, une mise en réseau et un refroidissement supplémentaires. Tout cela peut s'avérer très difficile sans une planification méticuleuse de la croissance future probable.
Mettre à l'échelle Hadoop (logiciel)
De nouveaux projets Hadoop sont développés régulièrement et les projets existants sont améliorés avec des fonctionnalités plus avancées.
Même les outils hérités sont mis à niveau pour leur permettre de bénéficier d'un écosystème Hadoop. Gardez toujours un œil sur les nouveaux développements sur ce front. La variété et le volume des ensembles de données entrants nécessitent l'introduction de cadres supplémentaires.
La mise en œuvre d'un nouvel outil convivial peut résoudre un dilemme technique plus rapidement que d'essayer de créer une solution personnalisée. Ne craignez pas les solutions rapides commerciales déjà développées. Le marché est saturé de fournisseurs proposant Hadoop en tant que service ou des outils autonomes sur mesure.
Fiabilité des données et tolérance aux pannes
Son battement de coeur est un signal de prise de contact TCP récurrent. Les DataNodes, situés sur chaque serveur esclave, envoient en permanence un heartbeat au NameNode situé sur le serveur maître. Le délai de pulsation par défaut est de trois secondes. Si le NameNode ne reçoit pas de signal pendant plus de dix minutes, il annule le DataNode et ses blocs de données sont automatiquement programmés sur différents nœuds.
Ne diminuez pas la fréquence des pulsations pour essayer d'alléger la charge sur le NameNode. Garder les NameNodes "informés" est crucial, même dans des clusters extrêmement volumineux. Sans un afflux régulier et fréquent de battements de cœur, le NameNode est gravement gêné et ne peut pas contrôler le cluster aussi efficacement.
Pour éviter de graves conséquences en cas de panne, conservez les paramètres de détection de rack par défaut et stockez des répliques de blocs de données sur les racks de serveurs. Si vous perdez un rack de serveurs, les autres répliques survivent et l'impact sur le traitement des données est minime.