Présentation
HDFS (Hadoop Distributed File System) est un composant essentiel du projet Apache Hadoop. Hadoop est un écosystème de logiciels qui fonctionnent ensemble pour vous aider à gérer le Big Data. Les deux éléments principaux de Hadoop sont :
- MapReduce – responsable de l'exécution des tâches
- HDFS – responsable de la maintenance des données
Dans cet article, nous parlerons du deuxième des deux modules. Vous allez apprendre qu'est-ce que HDFS, comment il fonctionne et la terminologie HDFS de base .

Qu'est-ce que HDFS ?
Hadoop Distributed File System est un système de fichiers de stockage de données tolérant aux pannes qui s'exécute sur du matériel standard. Il a été conçu pour surmonter les défis que les bases de données traditionnelles ne pouvaient pas. Par conséquent, son plein potentiel n'est utilisé que lors de la gestion de données volumineuses.
Les principaux problèmes que le système de fichiers Hadoop a dû résoudre étaient la vitesse , coût , et fiabilité .
Quels sont les avantages de HDFS ?
Les avantages de HDFS sont, en fait, les solutions que le système de fichiers fournit pour les défis mentionnés précédemment :
- C'est rapide. Il peut fournir plus de 2 Go de données par seconde grâce à son architecture en cluster.
- C'est gratuit. HDFS est un logiciel open source sans frais de licence ni d'assistance.
- Il est fiable. Le système de fichiers stocke plusieurs copies de données dans des systèmes distincts pour garantir qu'elles sont toujours accessibles.
Ces avantages sont particulièrement importants lorsqu'il s'agit de données volumineuses et ont été rendus possibles grâce à la manière particulière dont HDFS gère les données.
Comment HDFS stocke-t-il les données ?
HDFS divise les fichiers en blocs et stocke chaque bloc sur un DataNode. Plusieurs DataNodes sont liés au nœud maître du cluster, le NameNode. Le nœud maître distribue des répliques de ces blocs de données dans le cluster. Il indique également à l'utilisateur où trouver les informations recherchées.
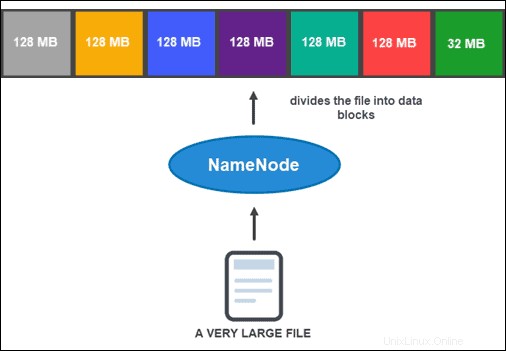
Cependant, avant que le NameNode puisse vous aider à stocker et à gérer les données, il doit d'abord partitionner le fichier en blocs de données plus petits et gérables. Ce processus est appelé fractionnement de blocs de données .
Fractionnement des blocs de données
Par défaut, un bloc ne peut pas dépasser 128 Mo. Le nombre de blocs dépend de la taille initiale du fichier. Tous sauf le dernier bloc ont la même taille (128 Mo), tandis que le dernier est ce qui reste du fichier.
Par exemple, un fichier de 800 Mo est divisé en sept blocs de données. Six des sept blocs font 128 Mo, tandis que le septième bloc de données correspond aux 32 Mo restants.
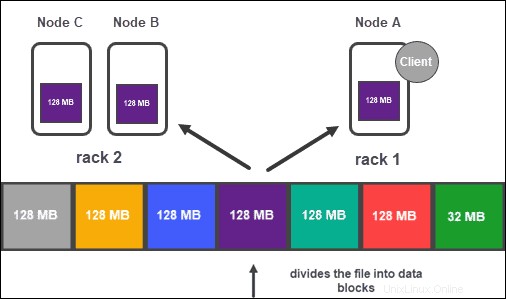
Ensuite, chaque bloc est répliqué en plusieurs exemplaires.
Réplication des données
En fonction de la configuration du cluster, le NameNode crée un certain nombre de copies de chaque bloc de données à l'aide de la méthode de réplication .
Il est recommandé d'avoir au moins trois répliques, ce qui est également le paramètre par défaut. Le nœud maître les stocke sur des DataNodes distincts du cluster. L'état des nœuds est surveillé de près pour s'assurer que les données sont toujours disponibles.
Pour garantir une accessibilité, une fiabilité et une tolérance aux pannes élevées, les développeurs conseillent de configurer les trois répliques en utilisant la topologie suivante :
- Stocker la première réplique sur le nœud où se trouve le client.
- Ensuite, stockez la deuxième réplique sur un autre rack.
- Enfin, stockez la troisième réplique sur le même rack que le deuxième réplica, mais sur un nœud différent.
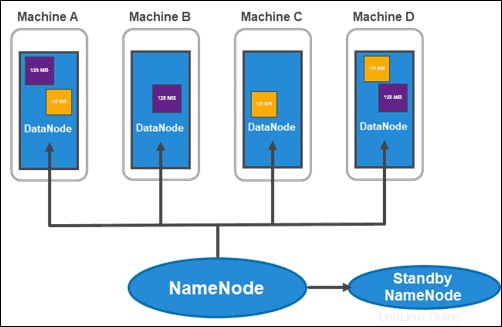
Architecture HDFS :NameNodes et DataNodes
HDFS a une architecture maître-esclave. Le nœud maître est le NameNode , qui gère plusieurs nœuds esclaves au sein du cluster, appelés DataNodes .
NameNodes
Hadoop 2.x a introduit la possibilité d'avoir plusieurs NameNodes par rack. Cette nouveauté était assez importante car avoir un seul nœud maître avec toutes les informations au sein du cluster posait une grande vulnérabilité.
Le cluster habituel se compose de deux NameNodes :
- un NameNode actif
- et un NameNode de secours
Alors que le premier traite de toutes les opérations client au sein du cluster, le second reste synchronisé avec tout son travail s'il y a un besoin de basculement.
Le NameNode actif garde une trace des métadonnées de chaque bloc de données et de ses répliques. Cela inclut le nom du fichier, l'autorisation, l'ID, l'emplacement et le nombre de répliques. Il conserve toutes les informations dans une fsimage , une image d'espace de noms stockée dans la mémoire locale du système de fichiers. De plus, il maintient des journaux de transactions appelés EditLogs , qui enregistrent toutes les modifications apportées au système.
L'objectif principal du Stanby NameNode est de résoudre le problème du point de défaillance unique. Il lit toutes les modifications apportées aux EditLogs et les applique à son NameSpace (les fichiers et les répertoires dans les données). Si le nœud maître échoue, le service Zookeeper effectue le basculement permettant au serveur de secours de maintenir une session active.
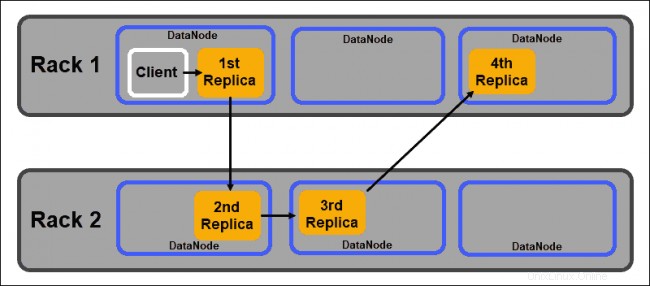
Noeuds de données
Les DataNodes sont des démons esclaves qui stockent les blocs de données attribués par le NameNode. Comme mentionné ci-dessus, les paramètres par défaut garantissent que chaque bloc de données a trois répliques. Vous pouvez modifier le nombre de répliques, cependant, il est déconseillé de descendre en dessous de trois.
Les répliques doivent être distribuées conformément à la Rack Awareness de Hadoop. politique qui note que :
- Le nombre de répliques doit être supérieur au nombre de racks.
- Un DataNode ne peut stocker qu'une seule réplique d'un bloc de données.
- Un rack ne peut pas stocker plus de deux répliques d'un bloc de données.
En suivant ces directives, vous pouvez :
- Optimiser la bande passante du réseau.
- Protégez-vous contre la perte de données.
- Améliorez les performances et la fiabilité.
Fonctionnalités clés de HDFS
Voici les principales caractéristiques du système de fichiers distribué Hadoop :
Utilisation réelle de HDFS
Les entreprises traitant de gros volumes de données ont depuis longtemps commencé à migrer vers Hadoop, l'une des principales solutions de traitement des mégadonnées en raison de ses capacités de stockage et d'analyse.
Services financiers. Le système de fichiers distribué Hadoop est conçu pour prendre en charge les données qui devraient croître de façon exponentielle. Le système est évolutif sans risque de ralentir le traitement complexe des données.
Vente au détail. Étant donné que la connaissance de vos clients est un élément essentiel du succès dans le secteur de la vente au détail, de nombreuses entreprises conservent de grandes quantités de données clients structurées et non structurées. Ils utilisent Hadoop pour suivre et analyser les données collectées afin d'aider à planifier l'inventaire futur, la tarification, les campagnes marketing et d'autres projets.
Télécommunications. L'industrie des télécommunications gère d'énormes quantités de données et doit traiter à l'échelle des pétaoctets. Il utilise l'analyse Hadoop pour gérer les enregistrements de données d'appel, l'analyse du trafic réseau et d'autres processus liés aux télécommunications.
Industrie de l'énergie. L'industrie de l'énergie est toujours à la recherche de moyens d'améliorer l'efficacité énergétique. Il s'appuie sur des systèmes tels que Hadoop et son système de fichiers pour analyser et comprendre les habitudes et les pratiques de consommation.
Assurance. Les compagnies d'assurance médicale dépendent de l'analyse des données. Ces résultats servent de base à la façon dont ils formulent et mettent en œuvre des politiques. Pour les compagnies d'assurance, la connaissance de l'historique des clients est inestimable. Avoir la capacité de maintenir une base de données facilement accessible tout en continuant à croître est la raison pour laquelle tant de personnes se sont tournées vers Apache Hadoop.