Présentation
L'une des plus grandes menaces pour les bases de données modernes est la perte de données due à une panne matérielle ou à un rançongiciel. Les bases de données distribuées offrent une solution en répliquant les données dans différents emplacements physiques.
La réplication de base de données permet de distribuer des parties d'une base de données sur plusieurs nœuds.
Dans ce didacticiel, nous verrons comment fonctionne la réplication de données, quand l'utiliser, différents types et schémas de réplication, et les outils qui aident à répliquer une base de données.

Qu'est-ce que la réplication de base de données ?
Réplication de base de données est le processus de copie des données et de leur stockage à différents endroits. La réplication des données garantit qu'il existe une copie cohérente de la base de données sur tous les nœuds d'un système distribué. Cela permet de rendre les données largement disponibles et de les protéger contre la perte de données.
Les données répliquées peuvent être un complet ou partielle instantané et il peut être stocké sur site, hors site ou dans un environnement cloud. En cas d'indisponibilité, les organisations récupèrent les données et maintiennent la continuité des activités en restaurant à partir d'un emplacement de sauvegarde.
Remarque : 90 % des entreprises sans plan de reprise après sinistre ferment après une interruption majeure. Éliminez ce risque grâce aux solutions de reprise après sinistre en tant que service (DRaaS) leaders du secteur.
Les données sont répliquées soit de manière synchrone ou asynchrone :
- Réplication synchrone . Les données sont écrites simultanément dans la base de données principale et toutes ses répliques.
- Réplication asynchrone . Les données sont d'abord écrites dans la base de données principale, puis copiées ultérieurement dans les répliques.
Types de réplication de base de données
Il existe plusieurs méthodes différentes pour répliquer une base de données. Les organisations doivent choisir une technique en fonction de l'objectif des données répliquées et de la manière dont elles ont l'intention d'y accéder.
Réplication d'instantané
Réplication d'instantané copie un "instantané" de la base de données - précisément tel qu'il apparaît au moment où le processus de réplication démarre. Il ne surveille pas les modifications ou les mises à jour des données.
La réplication d'instantané est utile lorsque les données ne changent pas fréquemment, mais aussi s'il y a des changements importants sur une courte période. Toute modification apportée à la base de données rend un instantané obsolète jusqu'à ce qu'un nouveau soit répliqué.
Réplication transactionnelle
Réplication transactionnelle crée une copie complète de la base de données, avec de nouvelles données entrant au fur et à mesure que la base de données change. Les données sont copiées en temps réel dans l'ordre des modifications apportées, ce qui garantit la cohérence.
Il est préférable d'utiliser la réplication transactionnelle pour garantir des modifications incrémentielles et en temps réel des données. Cela améliore les performances et réduit la latence tout en fournissant un volume élevé d'activités de lecture, d'écriture et de suppression.
Fusionner la réplication
Fusionner la réplication combine des données provenant de plusieurs sources dans une seule base de données. L'utilisation de la réplication de fusion permet à plusieurs utilisateurs de modifier les données et d'appliquer toutes les modifications au nouveau réplica.
La réplication de fusion permet de découvrir et de traiter rapidement les modifications conflictuelles. Il permet également aux utilisateurs d'apporter des modifications hors ligne avant de synchroniser avec le serveur.
Réplication hétérogène
Réplication hétérogène est utilisé pour répliquer des données entre des serveurs fournis par différents fournisseurs. Par exemple, il vous permet de copier des données d'un serveur SQL vers un serveur non-SQL.
Réplication transactionnelle pair à pair
Réplication pair à pair est basé sur la réplication transactionnelle. Il permet à tous les utilisateurs et serveurs participants de s'envoyer des données afin que les mises à jour se produisent en temps quasi réel.
La réplication peer-to-peer est particulièrement utile pour les applications Web. Sa flexibilité permet d'adapter le nombre d'utilisateurs sans affecter les performances. Cela rend également le système plus robuste, permettant aux serveurs de s'arrêter pour maintenance.
Schémas de réplication de base de données
Les schémas de réplication suivants sont utilisés pour la réplication de base de données :
Réplication complète
Exécution d'une réplication complète signifie copier la base de données complète sur chaque nœud du système distribué. Cette approche maximise la redondance des données, augmente les performances globales et la disponibilité des données. Les données sont disponibles tant qu'un nœud est fonctionnel.
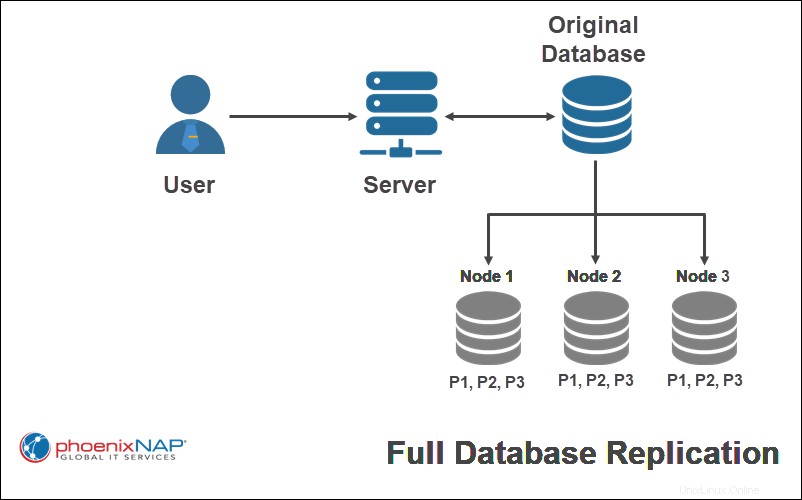
Dans l'exemple ci-dessus, toutes les parties de la base de données d'origine (P1, P2, P3) sont entièrement répliquées sur tous les sites.
La réplication complète prend plus de temps car la mise à jour doit être répliquée sur tous les sites. De plus, les coûts de stockage des instantanés de données complets à plusieurs endroits peuvent s'additionner.
Réplication partielle
Copier seulement certaines parties d'une base de données est une réplication partielle . Cela dépend généralement de l'importance d'avoir les données disponibles à chaque emplacement.
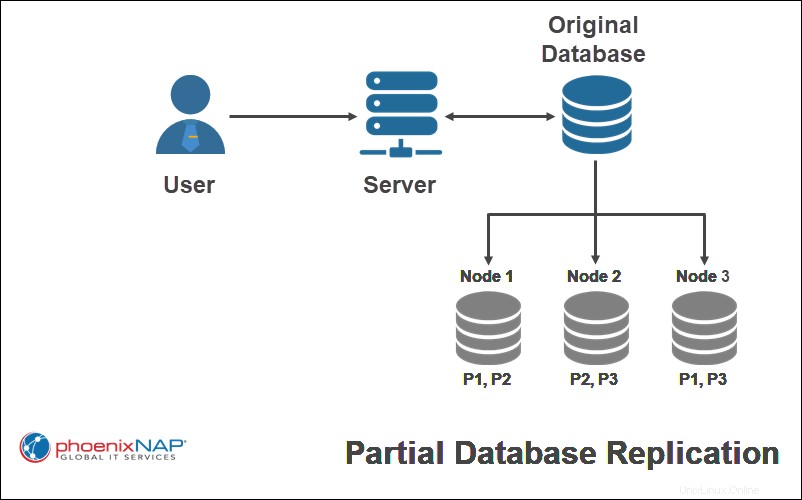
Dans l'exemple ci-dessus, seules certaines parties de la base de données d'origine (P1, P2, P3) sont répliquées sur un seul nœud.
Lors de l'utilisation d'un schéma de réplication partielle, le nombre de copies pour chaque partie de la base de données peut aller de un au nombre total de nœuds dans le système distribué.
Pas de réplication
Avec aucune réplication , chaque nœud d'un système distribué ne reçoit qu'une copie d'une partie de la base de données. Ce schéma de réplication est le plus rapide à exécuter, mais il a tendance à réduire la disponibilité des données et laisse la base de données vulnérable à la perte de données. Cependant, la simultanéité est facile à réaliser.
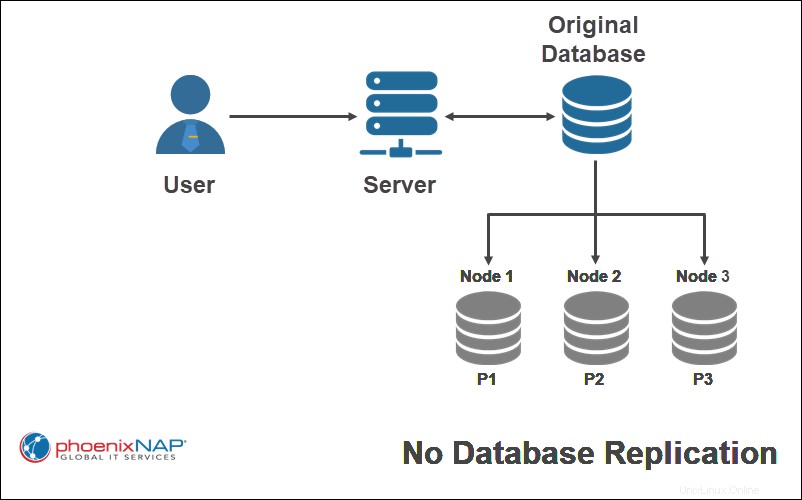
Dans l'exemple ci-dessus, un seul fragment de la base de données d'origine est répliqué sur un nœud spécifique.
Logiciels et outils de réplication de base de données
De nombreux outils de gestion de base de données offrent des moyens d'effectuer la réplication de base de données. Il existe également des outils de réplication tiers qui offrent les mêmes fonctionnalités.
Les outils tiers peuvent même être plus flexibles puisque la plupart vous permettent de répliquer sur plusieurs types de bases de données. Voici quelques-uns des exemples les plus populaires :
- Sauvegarde et restauration des données phoenixNAP. phoenixNAP propose plusieurs options et solutions de sauvegarde, notamment l'intégration de Veeam, la sauvegarde de base de données dans le cloud, la sauvegarde gérée pour Office 365 et DRaaS (Disaster Recovery as a Service).
- Sauvegarde et réplication Veeam . Veeam fonctionne avec différents types de bases de données, y compris les bases de données cloud, virtuelles, Kubernetes et les distributions physiques. Il offre une protection continue des données, une réplication et un basculement avancés pour la reprise après sinistre, ainsi qu'une restauration instantanée pour les gestionnaires de bases de données populaires, tels que NAS, Microsoft SQL et Oracle.
- Acronis Cyber Backup . Acronis prend en charge plus de 20 plates-formes de bases de données et offre des fonctionnalités de sécurité avancées, telles que la prévention des ransomwares basée sur l'IA.
- Sauvegarde et réplication NAKIVO . NAKIVO offre des fonctionnalités telles que la prise en charge des applications en direct, la récupération au niveau des fichiers et des objets, la déduplication globale et les rapports automatiques. Il peut répliquer les données localement, sur un serveur distant ou dans le cloud.
- Sauvegarde sécurisée Carbonite. Carbonite s'adresse aux petites entreprises. Il offre une sauvegarde automatique du cloud et du disque dur, une sauvegarde d'image et une restauration à chaud, ainsi qu'une réplication de base de données à des niveaux supérieurs.
Avantages de la réplication de données
L'utilisation de la réplication de base de données aide :
- Assurez la continuité des activités grâce à un plan de reprise après sinistre. En cas de panne matérielle ou d'attaque par rançongiciel, la réplication des données dans le cadre de votre plan de reprise après sinistre garantit qu'il existe une copie hors site du système. Cela permet aux organisations de restaurer les données et de maintenir la continuité des activités.
- Améliorez les performances. Disposer des mêmes données à plusieurs endroits signifie qu'un utilisateur peut récupérer des données à partir du serveur le plus proche, ce qui réduit la latence du réseau et améliore les performances.
- Améliorer la prise en charge multi-utilisateurs. La réplication des données facilite l'exécution des requêtes, en particulier lorsque plusieurs utilisateurs accèdent à la base de données.
- Améliorez les analyses. Disposer d'une copie complète et distincte d'une base de données permet à une équipe d'effectuer des analyses sans affecter les performances.
- Améliorez la disponibilité. Plusieurs utilisateurs peuvent accéder aux données d'une base de données distribuée et les gérer sans se gêner mutuellement.
Inconvénients de la réplication de données
La réplication des données pose plusieurs défis :
- Cela peut nécessiter beaucoup d'espace de stockage, en particulier pour les réplications complètes. Cela peut entraîner des coûts élevés ou réduire les performances si de nombreuses répliques doivent être mises à jour simultanément.
- Il est difficile de maintenir la cohérence des données lors de l'utilisation de méthodes telles que la fusion ou la réplication entre homologues.