Présentation
Un Spark DataFrame est une structure de données intégrée avec une API facile à utiliser pour simplifier le traitement distribué du Big Data. DataFrame est disponible pour les langages de programmation à usage général tels que Java, Python et Scala.
Il s'agit d'une extension de l'API Spark RDD optimisée pour écrire du code plus efficacement tout en restant puissant.
Cet article explique ce qu'est Spark DataFrame, les fonctionnalités et comment utiliser Spark DataFrame lors de la collecte de données.

Prérequis
- Spark installé et configuré (Suivez notre guide :Comment installer Spark sur Ubuntu, Comment installer Spark sur Windows 10).
- Un environnement configuré pour utiliser Spark en Java, Python ou Scala (ce guide utilise Python).
Qu'est-ce qu'un DataFrame ?
Un DataFrame est une abstraction de programmation dans le module Spark SQL. Les DataFrames ressemblent à des tables de bases de données relationnelles ou à des feuilles de calcul Excel avec des en-têtes :les données résident dans des lignes et des colonnes de différents types de données.
Le traitement est réalisé à l'aide de fonctions complexes définies par l'utilisateur et de fonctions de manipulation de données familières, telles que le tri, la jointure, le groupe, etc.
Les informations pour les données distribuées sont structurées en schémas . Chaque colonne d'un DataFrame contient la colonne name , type de données, et nullable Propriétés. Lorsque nullable est défini sur true , une colonne accepte null propriétés également.

Comment fonctionne un DataFrame ?
L'API DataFrame fait partie du module Spark SQL. L'API offre un moyen simple de travailler avec des données dans le cadre Spark SQL tout en s'intégrant à des langages à usage général tels que Java, Python et Scala.
Bien qu'il existe des similitudes avec Python Pandas et les trames de données R, Spark fait quelque chose de différent. Cette API est conçue sur mesure pour s'intégrer à des données à grande échelle pour la science des données et l'apprentissage automatique et apporte de nombreuses optimisations.
Les Spark DataFrames sont distribuables sur plusieurs clusters et optimisés avec Catalyst. L'optimiseur Catalyst prend les requêtes (y compris les commandes SQL appliquées aux DataFrames) et crée un plan de calcul parallèle optimal.
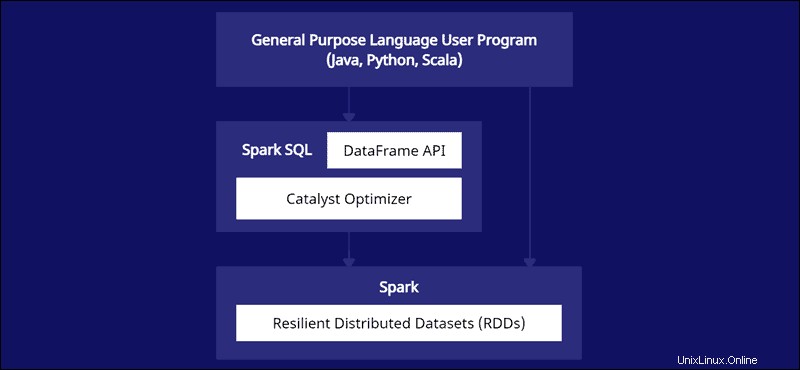
Si vous avez de l'expérience avec les dataframes Python et R, le code Spark DataFrame vous semble familier. D'un autre côté, si vous utilisez Spark RDD (Resilient Distributed Dataset), avoir des informations sur la structure des données offre des opportunités d'optimisation.
Les créateurs de Spark ont conçu les DataFrames pour relever les défis du Big Data de la manière la plus efficace. Les développeurs peuvent exploiter la puissance de l'informatique distribuée avec des API familières mais plus optimisées.
Caractéristiques des cadres de données Spark
Spark DataFrame est livré avec de nombreuses fonctionnalités utiles :
- Prise en charge de divers formats de données, tels que Hive, CSV, XML, JSON, RDD, Cassandra, Parquet, etc.
- Prise en charge de l'intégration avec divers outils Big Data
- La capacité de traiter des kilo-octets de données sur des machines plus petites et des pétaoctets sur des clusters.
- Optimiseur Catalyst pour un traitement efficace des données dans plusieurs langues
- Gestion structurée des données via une vue schématique des données
- Gestion personnalisée de la mémoire pour réduire la surcharge et améliorer les performances par rapport aux RDD.
- API pour Java, R, Python et Spark
Comment créer un Spark DataFrame ?
Il existe plusieurs méthodes pour créer un Spark DataFrame. Voici un exemple montrant comment en créer un en Python à l'aide de l'environnement de bloc-notes Jupyter :
1. Initialisez et créez une session API :
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Créez des données de jouets sous forme de liste de dictionnaires :
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Créez le DataFrame à l'aide de createDataFrame fonction et transmettez les data liste :
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Imprimez le schéma et la table pour afficher le DataFrame créé :
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()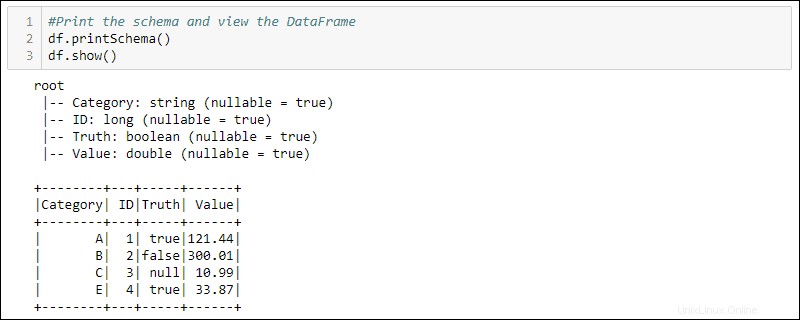
Comment utiliser les DataFrames
Les données structurées stockées dans un DataFrame offrent deux méthodes de manipulation
- Utiliser un langage spécifique au domaine
- Utiliser des requêtes SQL.
Les deux méthodes suivantes utilisent le DataFrame de l'exemple précédent pour sélectionner toutes les lignes où la colonne Truth est définie sur true et trier les données par la colonne Value.
Méthode 1 :Utilisation de requêtes spécifiques à un domaine
Python fournit des méthodes intégrées pour filtrer et trier les données. Sélectionnez la colonne spécifique à l'aide de df.<column name> :
df.filter(df.Truth == True).sort(df.Value).show()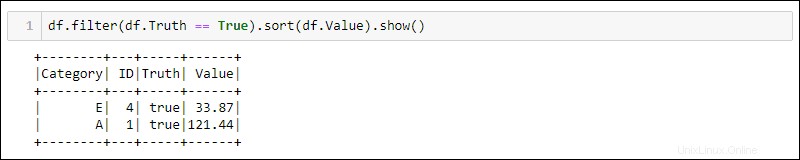
Méthode 2 :Utiliser des requêtes SQL
Pour utiliser des requêtes SQL avec le DataFrame, créez une vue avec le createOrReplaceTempView méthode intégrée et exécutez la requête SQL à l'aide de spark.sql méthode :
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')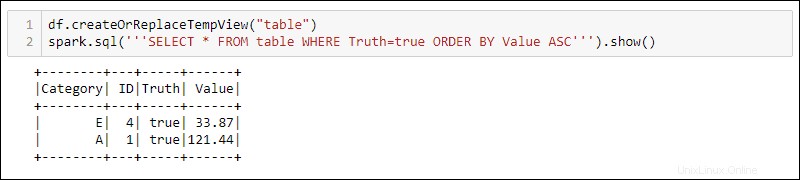
La sortie affiche les résultats de la requête SQL appliqués à la vue temporaire du DataFrame. Cela permet de créer plusieurs vues et requêtes sur les mêmes données pour un traitement de données complexe.