AWK est un puissant langage de programmation piloté par les données dont l'origine remonte aux premiers jours d'Unix. Il a été initialement développé pour écrire des programmes "one-liner", mais a depuis évolué pour devenir un langage de programmation à part entière. AWK tire son nom des initiales de ses auteurs - Aho, Weinberger et Kernighan. La commande awk sous Linux et d'autres systèmes Unix appelle l'interpréteur qui exécute les scripts AWK. Plusieurs implémentations d'awk existent dans les systèmes récents tels que gawk (GNU awk), mawk (Minimal awk) et nawk (New awk), entre autres. Consultez les exemples ci-dessous si vous souhaitez maîtriser awk.
Comprendre les programmes AWK
Les programmes écrits en awk consistent en des règles, qui sont simplement une paire de modèles et d'actions. Les modèles sont regroupés dans une accolade {}, et la partie action est déclenchée chaque fois que awk trouve des textes qui correspondent au modèle. Bien qu'awk ait été développé pour écrire des lignes simples, les utilisateurs expérimentés peuvent facilement écrire des scripts complexes avec.
Les programmes AWK sont très utiles pour le traitement de fichiers à grande échelle. Il identifie les champs de texte à l'aide de caractères spéciaux et de séparateurs. Il offre également des constructions de programmation de haut niveau comme des tableaux et des boucles. Il est donc tout à fait possible d'écrire des programmes robustes à l'aide de plain awk.
Exemples pratiques de la commande awk sous Linux
Les administrateurs utilisent normalement awk pour l'extraction de données et la création de rapports parallèlement à d'autres types de manipulations de fichiers. Ci-dessous, nous avons discuté de awk plus en détail. Suivez attentivement les commandes et essayez-les dans votre terminal pour une compréhension complète.
1. Imprimer des champs spécifiques à partir de la sortie texte
Les commandes Linux les plus utilisées affichent leur sortie en utilisant divers champs. Normalement, nous utilisons la commande Linux cut pour extraire un champ spécifique de ces données. Cependant, la commande ci-dessous vous montre comment procéder à l'aide de la commande awk.
$ who | awk '{print $1}' Cette commande affichera uniquement le premier champ de la sortie de la commande who. Ainsi, vous obtiendrez simplement les noms d'utilisateur de tous les utilisateurs actuellement connectés. Ici, 1 $ représente le premier champ. Vous devez utiliser $N si vous souhaitez extraire le N-ème champ.
2. Imprimer plusieurs champs à partir de la sortie texte
- -L'interpréteur awk nous permet d'imprimer n'importe quel nombre de champs que nous voulons. Les exemples ci-dessous nous montrent comment extraire les deux premiers champs de la sortie de la commande who.
$ who | awk '{print $1, $2}' Vous pouvez également contrôler l'ordre des champs de sortie. L'exemple suivant affiche d'abord la deuxième colonne produite par la commande who, puis la première colonne du deuxième champ.
$ who | awk '{print $2, $1}' Omettez simplement les paramètres de champ ($N ) pour afficher toutes les données.
3. Utiliser les instructions BEGIN
L'instruction BEGIN permet aux utilisateurs d'imprimer certaines informations connues dans la sortie. Il est généralement utilisé pour formater les données de sortie générées par awk. La syntaxe de cette instruction est indiquée ci-dessous.
BEGIN { Actions}
{ACTION} Les actions qui forment la section BEGIN sont toujours déclenchées. Ensuite, awk lit les lignes restantes une par une et voit si quelque chose doit être fait.
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2}' La commande ci-dessus étiquettera les deux champs de sortie extraits de la sortie de la commande who.
4. Utiliser les instructions END
Vous pouvez également utiliser l'instruction END pour vous assurer que certaines actions sont toujours exécutées à la fin de votre opération. Placez simplement la section END après l'ensemble principal d'actions.
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2} END {print "--COMPLETED--"}' La commande ci-dessus ajoutera la chaîne donnée à la fin de la sortie.
5. Rechercher à l'aide de modèles
Une grande partie du fonctionnement d'awk implique la correspondance de modèles et les regex. Comme nous en avons déjà discuté, awk recherche des modèles dans chaque ligne d'entrée et n'exécute l'action que lorsqu'une correspondance est déclenchée. Nos règles précédentes se composaient uniquement d'actions. Ci-dessous, nous avons illustré les bases de la correspondance de modèles à l'aide de la commande awk sous Linux.
$ who | awk '/mary/ {print}' Cette commande verra si l'utilisateur mary est actuellement connecté ou non. Il affichera la ligne entière si une correspondance est trouvée.
6. Extraire des informations à partir de fichiers
La commande awk fonctionne très bien avec les fichiers et peut être utilisée pour des tâches de traitement de fichiers complexes. La commande suivante illustre comment awk gère les fichiers.
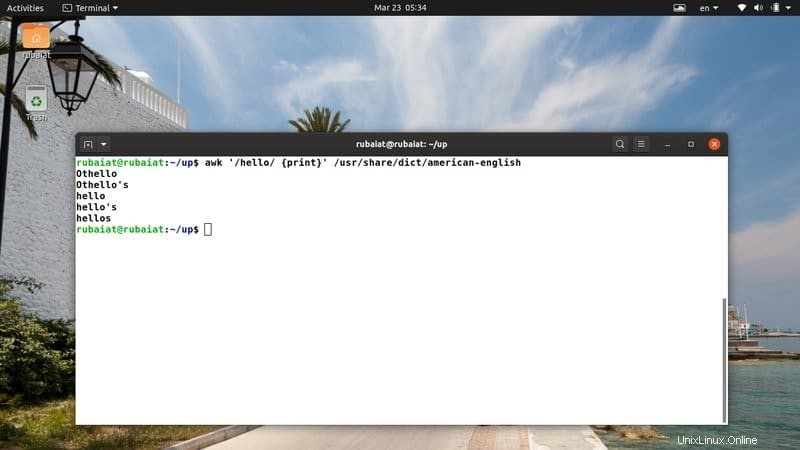
$ awk '/hello/ {print}' /usr/share/dict/american-english Cette commande recherche le modèle « bonjour » dans le fichier du dictionnaire américain-anglais. Il est disponible sur la plupart des distributions basées sur Linux. Ainsi, vous pouvez facilement essayer des programmes awk sur ce fichier.
7. Lire le script AWK à partir du fichier source
Bien qu'il soit utile d'écrire des programmes d'une seule ligne, vous pouvez également écrire de gros programmes en utilisant entièrement awk. Vous voudrez les enregistrer et exécuter votre programme en utilisant le fichier source.
$ awk -f script-file $ awk --file script-file
Le -f ou –fichier L'option nous permet de spécifier le fichier programme. Cependant, vous n'avez pas besoin d'utiliser des guillemets (' ') à l'intérieur du fichier de script car le shell Linux n'interprétera pas le code du programme de cette façon.
8. Définir le séparateur de champ d'entrée
Un séparateur de champ est un délimiteur qui divise l'enregistrement d'entrée. Nous pouvons facilement spécifier des séparateurs de champs à awk en utilisant le -F ou – séparateur de champs option. Consultez les commandes ci-dessous pour voir comment cela fonctionne.
$ echo "This-is-a-simple-example" | awk -F - ' {print $1} '
$ echo "This-is-a-simple-example" | awk --field-separator - ' {print $1} ' Cela fonctionne de la même manière lorsque vous utilisez des fichiers de script plutôt que la commande awk à une ligne sous Linux.
9. Imprimer les informations en fonction de l'état
Nous avons discuté de la commande Linux cut dans un guide précédent. Nous allons maintenant vous montrer comment extraire des informations en utilisant awk uniquement lorsque certains critères correspondent. Nous utiliserons le même fichier de test que nous avons utilisé dans ce guide. Alors allez-y et faites une copie du test.txt fichier.
$ awk '$4 > 50' test.txt
Cette commande imprimera toutes les nations du fichier test.txt, qui compte plus de 50 millions d'habitants.
10. Imprimer des informations en comparant des expressions régulières
La commande awk suivante vérifie si le troisième champ de n'importe quelle ligne contient le modèle "Lira" et imprime la ligne entière si une correspondance est trouvée. Nous utilisons à nouveau le fichier test.txt utilisé pour illustrer la commande Linux cut. Assurez-vous donc d'avoir ce fichier avant de continuer.
$ awk '$3 ~ /Lira/' test.txt
Vous pouvez choisir de n'imprimer qu'une partie spécifique d'une correspondance si vous le souhaitez.
11. Comptez le nombre total de lignes en entrée
La commande awk a de nombreuses variables à usage spécial qui nous permettent de faire facilement de nombreuses choses avancées. L'une de ces variables est NR, qui contient le numéro de ligne actuel.
$ awk 'END {print NR} ' test.txt Cette commande affichera le nombre de lignes présentes dans notre fichier test.txt. Il parcourt d'abord chaque ligne, et une fois qu'il a atteint END, il imprime la valeur de NR - qui contient le nombre total de lignes dans ce cas.
12. Définir le séparateur de champ de sortie
Plus tôt, nous avons montré comment sélectionner des séparateurs de champs de saisie à l'aide de -F ou –field-separator option. La commande awk nous permet également de spécifier le séparateur de champ de sortie. L'exemple ci-dessous le montre à l'aide d'un exemple pratique.
$ date | awk 'OFS="-" {print$2,$3,$6}' Cette commande imprime la date actuelle en utilisant le format jj-mm-aa. Exécutez le programme de date sans awk pour voir à quoi ressemble la sortie par défaut.
13. Utilisation de la construction If
Comme d'autres langages de programmation populaires, awk fournit également aux utilisateurs les constructions if-else. L'instruction if dans awk a la syntaxe ci-dessous.
if (expression)
{
first_action
second_action
} Les actions correspondantes ne sont exécutées que si l'expression conditionnelle est vraie. L'exemple ci-dessous le démontre en utilisant notre fichier de référence test.txt .
$ awk '{ if ($4>100) print }' test.txt Vous n'avez pas besoin de maintenir strictement l'indentation.
14. Utilisation de constructions If-Else
Vous pouvez construire des échelles if-else utiles en utilisant la syntaxe ci-dessous. Ils sont utiles lors de la conception de scripts awk complexes qui traitent des données dynamiques.
if (expression) first_action else second_action
$ awk '{ if ($4>100) print; else print }' test.txt La commande ci-dessus imprimera l'intégralité du fichier de référence puisque le quatrième champ n'est pas supérieur à 100 pour chaque ligne.
15. Définir la largeur du champ
Parfois, les données d'entrée sont assez désordonnées et les utilisateurs peuvent avoir du mal à les visualiser dans leurs rapports. Heureusement, awk fournit une puissante variable intégrée appelée FIELDWIDTHS qui nous permet de définir une liste de largeurs séparées par des espaces.
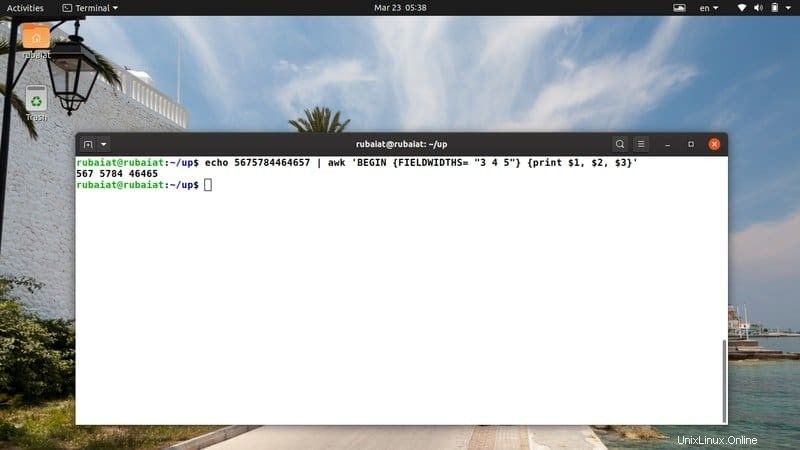
$ echo 5675784464657 | awk 'BEGIN {FIELDWIDTHS= "3 4 5"} {print $1, $2, $3}' C'est très utile lors de l'analyse de données dispersées car nous pouvons contrôler la largeur du champ de sortie exactement comme nous le voulons.
16. Définir le séparateur d'enregistrements
Le RS ou Record Separator est une autre variable intégrée qui nous permet de spécifier comment les enregistrements sont séparés. Créons d'abord un fichier qui démontrera le fonctionnement de cette variable awk.
$ cat new.txt Melinda James 23 New Hampshire (222) 466-1234 Daniel James 99 Phonenix Road (322) 677-3412
$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' new.txt Cette commande analysera le document et recrachera le nom et l'adresse des deux personnes.
17. Variables d'environnement d'impression
La commande awk sous Linux nous permet d'imprimer facilement des variables d'environnement à l'aide de la variable ENVIRON. La commande ci-dessous montre comment l'utiliser pour imprimer le contenu de la variable PATH.
$ awk 'BEGIN{ print ENVIRON["PATH"] }' Vous pouvez imprimer le contenu de n'importe quelle variable d'environnement en remplaçant l'argument de la variable ENVIRON. La commande ci-dessous imprime la valeur de la variable d'environnement HOME.
$ awk 'BEGIN{ print ENVIRON["HOME"] }' 18. Omettre certains champs de la sortie
La commande awk nous permet d'omettre des lignes spécifiques de notre sortie. La commande suivante le démontrera en utilisant notre fichier de référence test.txt .
$ awk -F":" '{$2=""; print}' test.txt Cette commande omettra la deuxième colonne de notre fichier, qui contient le nom de la capitale pour chaque pays. Vous pouvez également omettre plusieurs champs, comme indiqué dans la commande suivante.
$ awk -F":" '{$2="";$3="";print}' test.txt 19. Supprimer les lignes vides
Parfois, les données peuvent contenir trop de lignes vides. Vous pouvez utiliser la commande awk pour supprimer assez facilement les lignes vides. Consultez la commande suivante pour voir comment cela fonctionne dans la pratique.
$ awk '/^[ \t]*$/{next}{print}' new.txt Nous avons supprimé toutes les lignes vides du fichier new.txt à l'aide d'une simple expression régulière et d'un awk intégré appelé next.
20. Supprimer les espaces blancs de fin
La sortie de nombreuses commandes Linux contient des espaces blancs à la fin. Nous pouvons utiliser la commande awk sous Linux pour supprimer ces espaces comme les espaces et les tabulations. Consultez la commande ci-dessous pour voir comment résoudre ces problèmes en utilisant awk.
$ awk '{sub(/[ \t]*$/, "");print}' new.txt test.txt Ajoutez des espaces blancs à la fin de nos fichiers de référence et vérifiez si awk les a supprimés avec succès ou non. Il l'a fait avec succès sur ma machine.
21. Vérifier le nombre de champs dans chaque ligne
Nous pouvons facilement vérifier combien de champs il y a dans une ligne en utilisant un simple awk one-liner. Il existe de nombreuses façons de procéder, mais nous utiliserons certaines des variables intégrées de awk pour cette tâche. La variable NR nous donne le numéro de ligne, et la variable NF nous donne le nombre de champs.
$ awk '{print NR,"-->",NF}' test.txt Nous pouvons maintenant confirmer le nombre de champs par ligne dans notre test.txt document. Étant donné que chaque ligne de ce fichier contient 5 champs, nous sommes assurés que la commande fonctionne comme prévu.
22. Vérifier le nom de fichier actuel
La variable awk FILENAME est utilisée pour vérifier le nom de fichier d'entrée actuel. Nous démontrons comment cela fonctionne à l'aide d'un exemple simple. Cependant, cela peut être utile dans les situations où le nom de fichier n'est pas connu explicitement ou s'il existe plusieurs fichiers d'entrée.
$ awk '{print FILENAME}' test.txt
$ awk '{print FILENAME}' test.txt new.txt Les commandes ci-dessus affichent le nom de fichier sur lequel awk travaille chaque fois qu'il traite une nouvelle ligne des fichiers d'entrée.
23. Vérifier le nombre d'enregistrements traités
L'exemple suivant montrera comment nous pouvons vérifier le nombre d'enregistrements traités par la commande awk. Étant donné qu'un grand nombre d'administrateurs système Linux utilisent awk pour générer des rapports, cela leur est très utile.
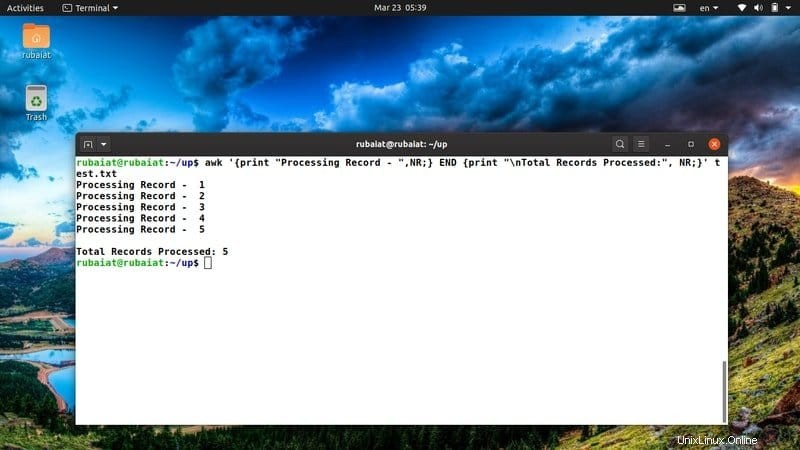
$ awk '{print "Processing Record - ",NR;} END {print "\nTotal Records Processed:", NR;}' test.txt J'utilise souvent cet extrait awk pour avoir un aperçu clair de mes actions. Vous pouvez facilement le modifier pour l'adapter à de nouvelles idées ou actions.
24. Imprimer le nombre total de caractères dans un enregistrement
Le langage awk fournit une fonction pratique appelée length() qui nous indique combien de caractères sont présents dans un enregistrement. Il est très utile dans un certain nombre de scénarios. Jetez un coup d'œil à l'exemple suivant pour voir comment cela fonctionne.
$ echo "A random text string..." | awk '{ print length($0); }' $ awk '{ print length($0); }' /etc/passwd La commande ci-dessus imprimera le nombre total de caractères présents dans chaque ligne de la chaîne ou du fichier d'entrée.
25. Imprimer toutes les lignes plus longues qu'une longueur spécifiée
Nous pouvons ajouter certaines conditions à la commande ci-dessus et lui faire imprimer uniquement les lignes supérieures à une longueur prédéfinie. C'est utile lorsque vous avez déjà une idée de la longueur d'un enregistrement spécifique.
$ echo "A random text string..." | awk 'length($0) > 10'
$ awk '{ length($0) > 5; }' /etc/passwd Vous pouvez ajouter plus d'options et/ou d'arguments pour ajuster la commande en fonction de vos besoins.
26. Imprimer le nombre de lignes, de caractères et de mots
La commande awk suivante sous Linux imprime le nombre de lignes, de caractères et de mots dans une entrée donnée. Il utilise la variable NR ainsi que quelques arithmétiques de base pour effectuer cette opération.
$ echo "This is a input line..." | awk '{ w += NF; c += length + 1 } END { print NR, w, c }' Cela montre qu'il y a 1 ligne, 5 mots et exactement 24 caractères présents dans la chaîne d'entrée.
27. Calculer la fréquence des mots
Nous pouvons combiner des tableaux associatifs et la boucle for dans awk pour calculer la fréquence des mots d'un document. La commande suivante peut sembler un peu complexe, mais elle est assez simple une fois que vous comprenez clairement les constructions de base.
$ awk 'BEGIN {FS="[^a-zA-Z]+" } { for (i=1; i<=NF; i++) words[tolower($i)]++ } END { for (i in words) print i, words[i] }' test.txt Si vous rencontrez des problèmes avec l'extrait d'une ligne, copiez le code suivant dans un nouveau fichier et exécutez-le à l'aide de la source.
$ cat > frequency.awk
BEGIN {
FS="[^a-zA-Z]+"
}
{
for (i=1; i<=NF; i++)
words[tolower($i)]++
}
END {
for (i in words)
print i, words[i]
} Ensuite, exécutez-le en utilisant le -f option.
$ awk -f frequency.awk test.txt
28. Renommer les fichiers en utilisant AWK
La commande awk peut être utilisée pour renommer tous les fichiers correspondant à certains critères. La commande suivante illustre comment utiliser awk pour renommer tous les fichiers .MP3 d'un répertoire en fichiers .mp3.
$ touch {a,b,c,d,e}.MP3
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }'
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }' | sh Tout d'abord, nous avons créé des fichiers de démonstration avec l'extension .MP3. La deuxième commande montre à l'utilisateur ce qui se passe lorsque le changement de nom est réussi. Enfin, la dernière commande effectue l'opération de renommage à l'aide de la commande mv sous Linux.
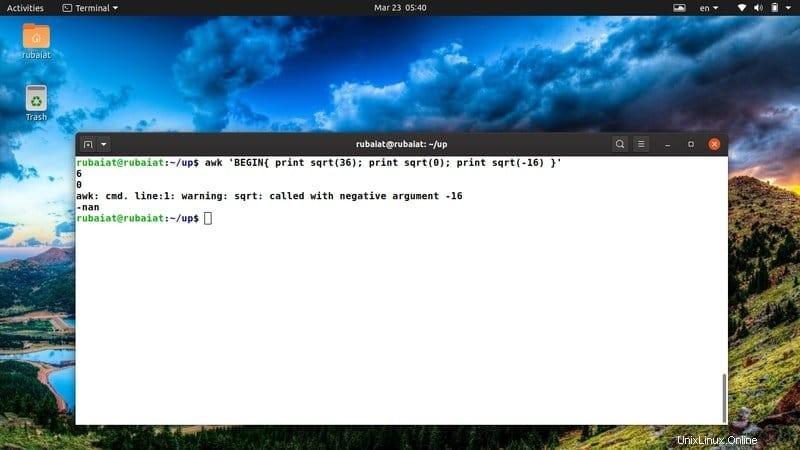
29. Imprimer la racine carrée d'un nombre
AWK offre plusieurs fonctions intégrées pour manipuler les chiffres. L'une d'elles est la fonction sqrt(). C'est une fonction de type C qui renvoie la racine carrée d'un nombre donné. Jetez un coup d'œil à l'exemple suivant pour voir comment cela fonctionne en général.
$ awk 'BEGIN{ print sqrt(36); print sqrt(0); print sqrt(-16) }' Comme vous ne pouvez pas déterminer la racine carrée d'un nombre négatif, la sortie affichera un mot-clé spécial appelé "nan" à la place de sqrt(-12).
30. Imprimer le logarithme d'un nombre
La fonction awk log() fournit le logarithme naturel d'un nombre. Cependant, cela ne fonctionnera qu'avec des nombres positifs, alors soyez conscient de la validation des entrées des utilisateurs. Sinon, quelqu'un pourrait casser vos programmes awk et obtenir un accès non privilégié aux ressources système.
$ awk 'BEGIN{ print log(36); print log(0); print log(-16) }' Vous devriez voir le logarithme de 36 et vérifier que le logarithme de 0 est l'infini, et que le log d'une valeur négative est "Pas un nombre" ou nan.
31. Imprimer l'exponentielle d'un nombre
L'exponentielle os d'un nombre n fournit la valeur de e^n. Il est généralement utilisé dans les scripts awk qui traitent de grands chiffres ou d'une logique arithmétique complexe. Nous pouvons générer l'exponentielle d'un nombre en utilisant la fonction intégrée awk exp().
$ awk 'BEGIN{ print exp(30); print log(0); print exp(-16) }' Cependant, awk ne peut pas calculer l'exponentielle pour des nombres extrêmement grands. Vous devez effectuer ces calculs en utilisant des langages de programmation de bas niveau comme C et fournir la valeur à vos scripts awk.
32. Générer des nombres aléatoires à l'aide d'AWK
Nous pouvons utiliser la commande awk sous Linux pour générer des nombres aléatoires. Ces nombres seront compris entre 0 et 1, mais jamais 0 ou 1. Vous pouvez multiplier une valeur fixe par le nombre résultant pour obtenir une valeur aléatoire plus grande.
$ awk 'BEGIN{ print rand(); print rand()*99 }' La fonction rand() n'a pas besoin d'argument. De plus, les nombres générés par cette fonction ne sont pas précisément aléatoires mais plutôt pseudo-aléatoires. De plus, il est assez facile de prédire ces chiffres d'une exécution à l'autre. Vous ne devez donc pas vous fier à eux pour des calculs sensibles.
33. Avertissements du compilateur de couleurs en rouge
Les compilateurs Linux modernes lanceront des avertissements si votre code ne respecte pas les normes de langage ou comporte des erreurs qui n'arrêtent pas l'exécution du programme. La commande awk suivante imprimera les lignes d'avertissement générées par un compilateur en rouge.
$ gcc -Wall main.c |& awk '/: warning:/{print "\x1B[01;31m" $0 "\x1B[m";next;}{print}' Cette commande est utile si vous souhaitez identifier spécifiquement les avertissements du compilateur. Vous pouvez utiliser cette commande avec n'importe quel compilateur autre que gcc, assurez-vous simplement de changer le modèle /:avertissement:/ pour refléter ce compilateur particulier.
34. Imprimer les informations UUID du système de fichiers
L'UUID ou Universally Unique Identifier est un numéro qui peut être utilisé pour identifier des ressources comme le système de fichiers Linux. Nous pouvons simplement imprimer les informations UUID de notre système de fichiers en utilisant la commande Linux awk suivante.
$ awk '/UUID/ {print $0}' /etc/fstab Cette commande recherche le texte UUID dans /etc/fstab fichier en utilisant des modèles awk. Il renvoie un commentaire du fichier qui ne nous intéresse pas. La commande ci-dessous s'assurera que nous n'obtenons que les lignes commençant par UUID.
$ awk '/^UUID/ {print $1}' /etc/fstab Il limite la sortie au premier champ. Nous n'obtenons donc que les numéros UUID.
35. Imprimer la version de l'image du noyau Linux
Différentes images du noyau Linux sont utilisées par diverses distributions Linux. Nous pouvons facilement imprimer l'image exacte du noyau sur laquelle notre système est basé en utilisant awk. Consultez la commande suivante pour voir comment cela fonctionne en général.
$ uname -a | awk '{print $3}' Nous avons d'abord émis la commande uname avec le -a option, puis achemine ces données vers awk. Ensuite, nous avons extrait les informations de version de l'image du noyau à l'aide de awk.
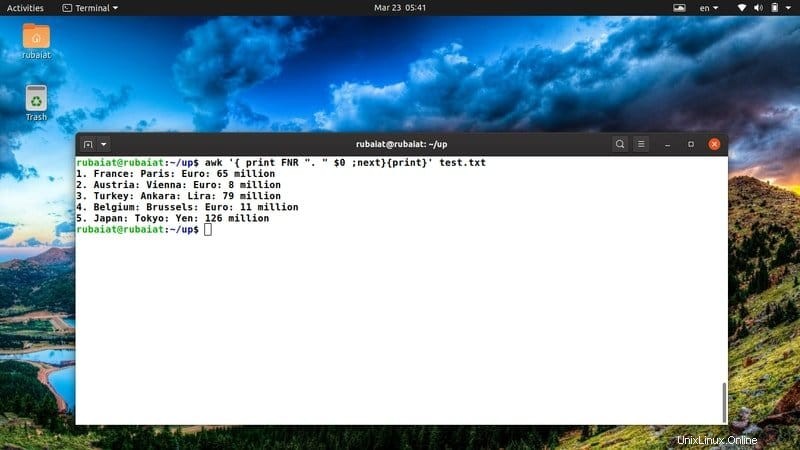
36. Ajouter des numéros de ligne avant les lignes
Les utilisateurs peuvent rencontrer assez souvent des fichiers texte qui ne contiennent pas de numéros de ligne. Heureusement, vous pouvez facilement ajouter des numéros de ligne à un fichier à l'aide de la commande awk sous Linux. Examinez attentivement l'exemple ci-dessous pour voir comment cela fonctionne dans la vie réelle.
$ awk '{ print FNR ". " $0 ;next}{print}' test.txt La commande ci-dessus ajoutera un numéro de ligne avant chacune des lignes de notre fichier de référence test.txt. Il utilise la variable awk intégrée FNR pour résoudre ce problème.
37. Imprimer un fichier après avoir trié le contenu
Nous pouvons également utiliser awk pour imprimer une liste triée de toutes les lignes. Les commandes suivantes impriment le nom de tous les pays dans notre test.txt dans un ordre trié.
$ awk -F ':' '{ print $1 }' test.txt | sort La commande suivante imprimera le nom de connexion de tous les utilisateurs à partir de /etc/passwd fichier.
$ awk -F ':' '{ print $1 }' /etc/passwd | sort Vous pouvez facilement changer l'ordre de tri en modifiant la commande de tri.
38. Imprimer la page du manuel
La page de manuel contient des informations détaillées sur la commande awk ainsi que toutes les options disponibles. C'est extrêmement important pour les personnes qui veulent bien maîtriser la commande awk.
$ man awk
Si vous souhaitez apprendre des fonctionnalités awk complexes, cela vous sera d'une grande aide. Consultez cette documentation chaque fois que vous rencontrez un problème.
39. Imprimer la page d'aide
La page d'aide contient des informations résumées sur tous les arguments de ligne de commande possibles. Vous pouvez invoquer le guide d'aide pour awk en utilisant l'une des commandes suivantes.
$ awk -h $ awk --help
Consultez cette page si vous voulez un aperçu rapide de toutes les options disponibles pour awk.
40. Imprimer les informations sur la version
Les informations de version nous fournissent des informations sur la construction d'un programme. La page de version d'awk contient des informations telles que ses droits d'auteur, ses outils de compilation, etc. Vous pouvez afficher ces informations à l'aide de l'une des commandes awk suivantes.
$ awk -V $ awk --version
Fin des pensées
La commande awk sous Linux nous permet de faire toutes sortes de choses, y compris le traitement des fichiers et la maintenance du système. Il fournit une gamme variée d'opérations pour gérer assez facilement les tâches informatiques quotidiennes. Nos éditeurs ont compilé ce guide avec 40 commandes awk utiles qui peuvent être utilisées pour la manipulation de texte ou l'administration. Comme AWK est un langage de programmation à part entière, il existe plusieurs façons de faire le même travail. Alors, ne vous demandez pas pourquoi nous faisons certaines choses d'une manière différente. Vous pouvez toujours organiser vos propres recettes en fonction de vos compétences et de votre expérience. Laissez-nous vos commentaires, faites-nous savoir si vous avez des questions.