Ruche est un entrepôt de données modèle dans Hadoop Eco-Système. Il peut fonctionner comme un outil ETL au-dessus de Hadoop . L'activation de la haute disponibilité (HA) sur Hive n'est pas similaire à ce que nous faisons dans les services principaux tels que Namenode et Resource Manager.
Le basculement automatique ne se produira pas dans Hive (Hiveserver2 ). Le cas échéant Hiveserver2 (HS2 ) échoue, l'exécution des tâches sur ce HS2 défaillant va échouer. Nous devons soumettre à nouveau la tâche afin qu'elle puisse s'exécuter sur un autre HiveServer2 . Donc, activer HA sur HS2 n'est rien d'autre qu'augmenter le nombre de HS2 composants dans Cluster .
Dans cet article, nous verrons les étapes pour installer et activer la haute disponibilité de Hive .
Exigences
- Bonnes pratiques pour le déploiement d'un serveur Hadoop sur CentOS/RHEL 7 – Partie 1
- Configuration des prérequis Hadoop et renforcement de la sécurité – Partie 2
- Comment installer et configurer Cloudera Manager sur CentOS/RHEL 7 – Partie 3
- Comment installer CDH et configurer les emplacements de service sur CentOS/RHEL 7 – Partie 4
- Comment configurer la haute disponibilité pour Namenode – Partie 5
- Comment configurer la haute disponibilité pour Resource Manager – Partie 6
Commençons…
Installation et configuration de la ruche
1. Connectez-vous à Cloudera Manager à l'URL ci-dessous et accédez à Cloudera Manager –> Ajouter un service .
http://13.233.129.39:7180/cmf/home
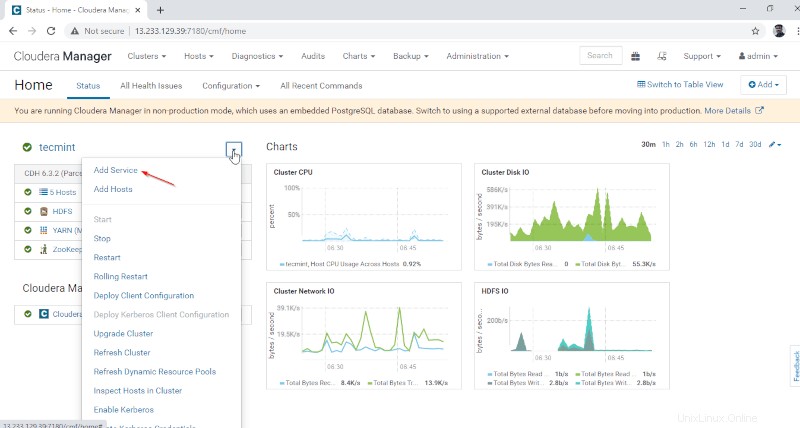
2. Sélectionnez le service ‘Hive ‘.
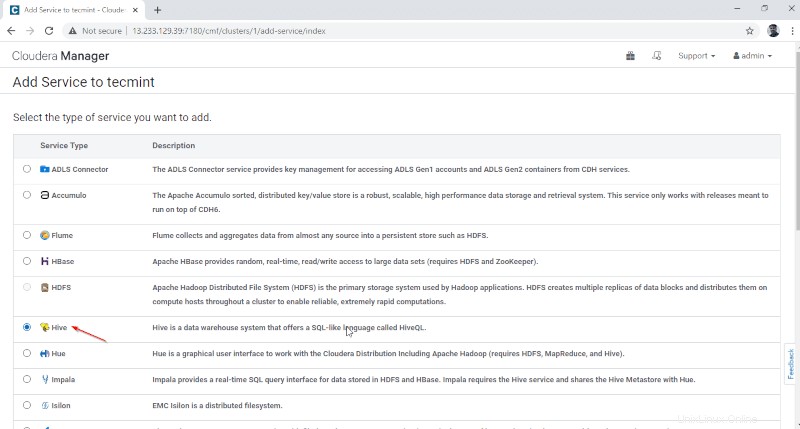
3. Attribuez les services aux nœuds.
- Passerelle – C'est le service client où l'utilisateur peut accéder au Hive. Habituellement, ce service sera placé dans Edge nœuds dédiés aux utilisateurs.
- Métastore Hive - Il s'agit d'un référentiel central pour stocker les métadonnées Hive.
- Serveur WebHCat – Il s'agit d'une API Web pour HCatalog et d'autres services Hadoop.
- Hiveserver2 – C'est une interface de clients pour l'exécution de requêtes sur Hive.
Une fois les serveurs sélectionnés, cliquez sur 'Continuer ‘ pour continuer.
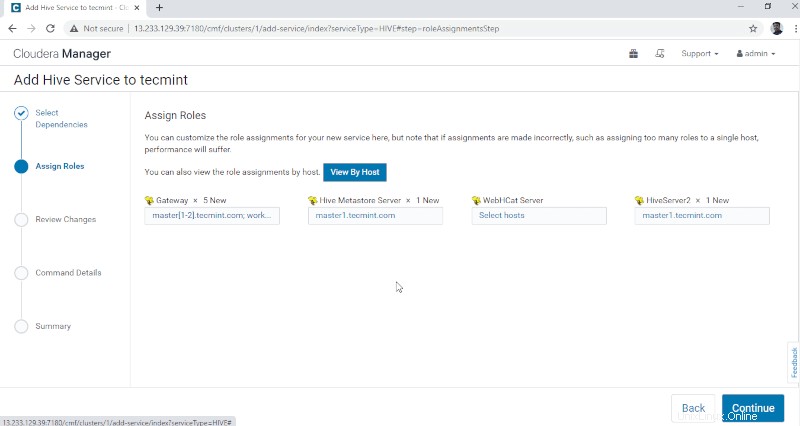
4. Hive Metastore a besoin d'une base de données sous-jacente pour stocker les métadonnées. Ici, nous utilisons le PostgreSQL par défaut base de données intégrée à CDH .
Les détails de la base de données mentionnés ci-dessous seront entrés automatiquement, 'Tester la connexion ' sera ignoré car la base de données mentionnée sera créée à la volée. En temps réel, nous devons créer la base de données dans la base de données externe et tester la connexion pour continuer. Une fois cela fait, veuillez cliquer sur "Continuer '.
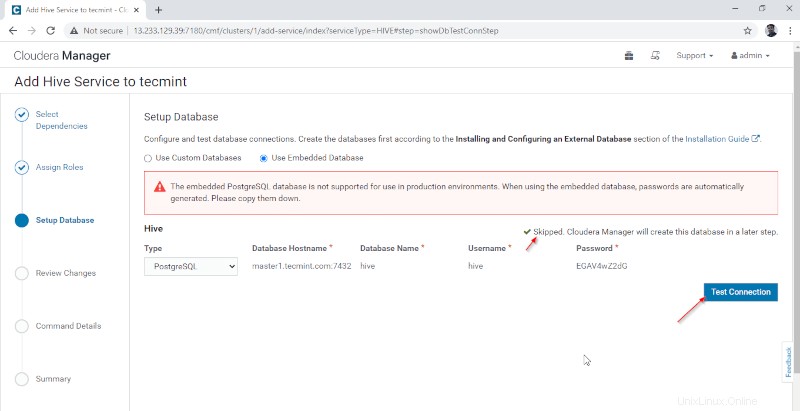
5. Configurer l'Entrepôt Hive répertoire, /user/hive/warehouse est le chemin de répertoire par défaut pour le stockage des tables Hive. Cliquez sur "Continuer '.
6. L'installation de Hive est lancée.
7. Une fois l'installation terminée, vous pouvez obtenir le message "Terminé ' statut. Cliquez sur 'Continuer ’ pour continuer.
8. L'installation et la configuration de Hive se sont terminées avec succès. Cliquez sur 'Terminer ‘ pour terminer la procédure d'installation.
9. Vous pouvez voir la ruche service ajouté dans Cluster via le tableau de bord Cloudera Manager .
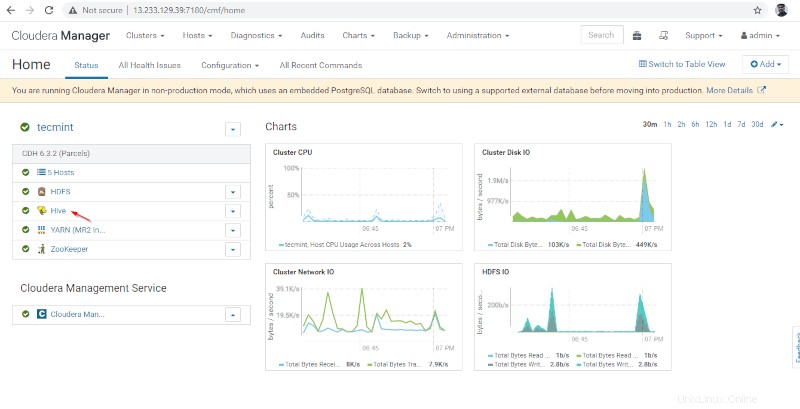
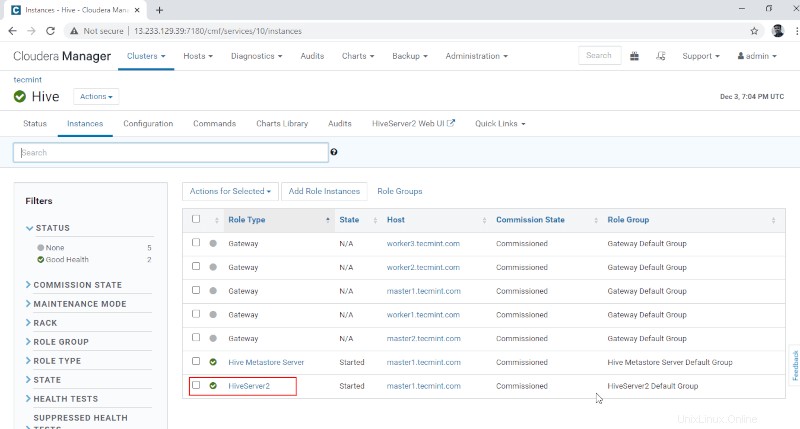
10. Vous pouvez afficher le Hiveserver2 dans Instances de Hive . Nous avons ajouté Hiveserver2 en master1 .
Gestionnaire Cloudera –> Ruche –> Instances –> Hiveserver2 .
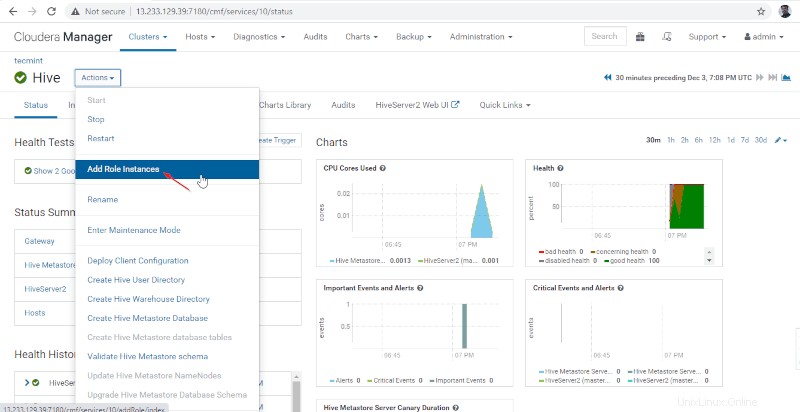
Activer la haute disponibilité sur Hive
11. Ajoutez ensuite le rôle Hive en accédant à Cloudera Manager –> Ruche –> Actions –> Ajouter un rôle instances.
12. Sélectionnez les serveurs sur lesquels vous souhaitez placer un Hiveserver2 supplémentaire . Vous pouvez en ajouter plus de deux, il n'y a pas de limite. Ici, nous en ajoutons un supplémentaire Hiveserver2 en master2 .
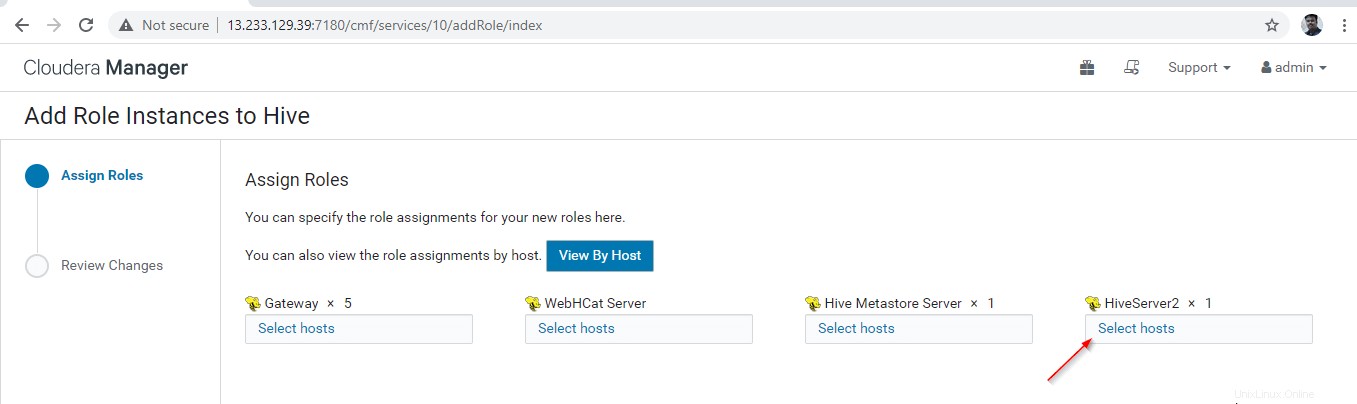
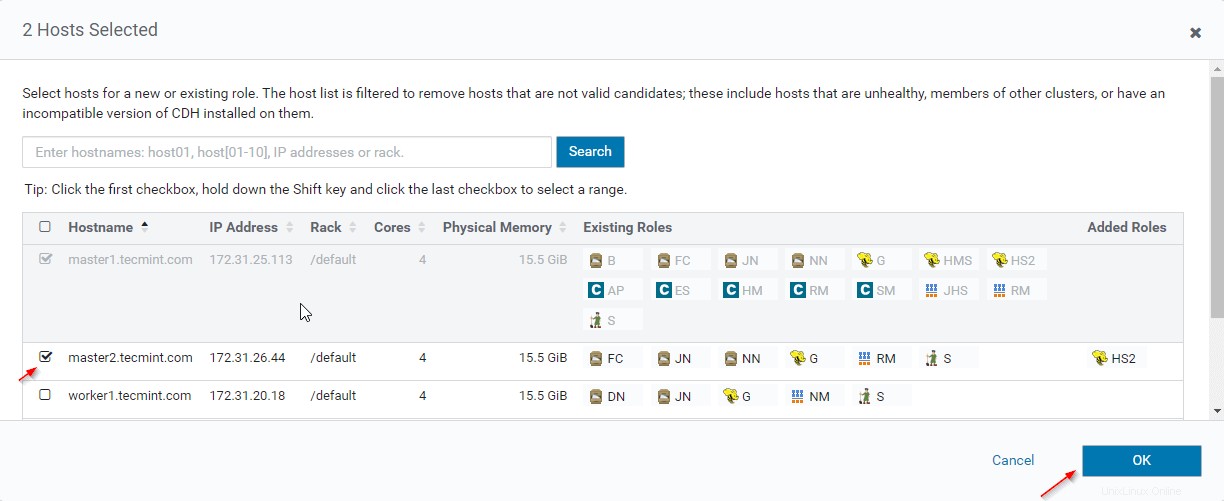
13. Une fois le serveur sélectionné, cliquez sur 'Continuer '.
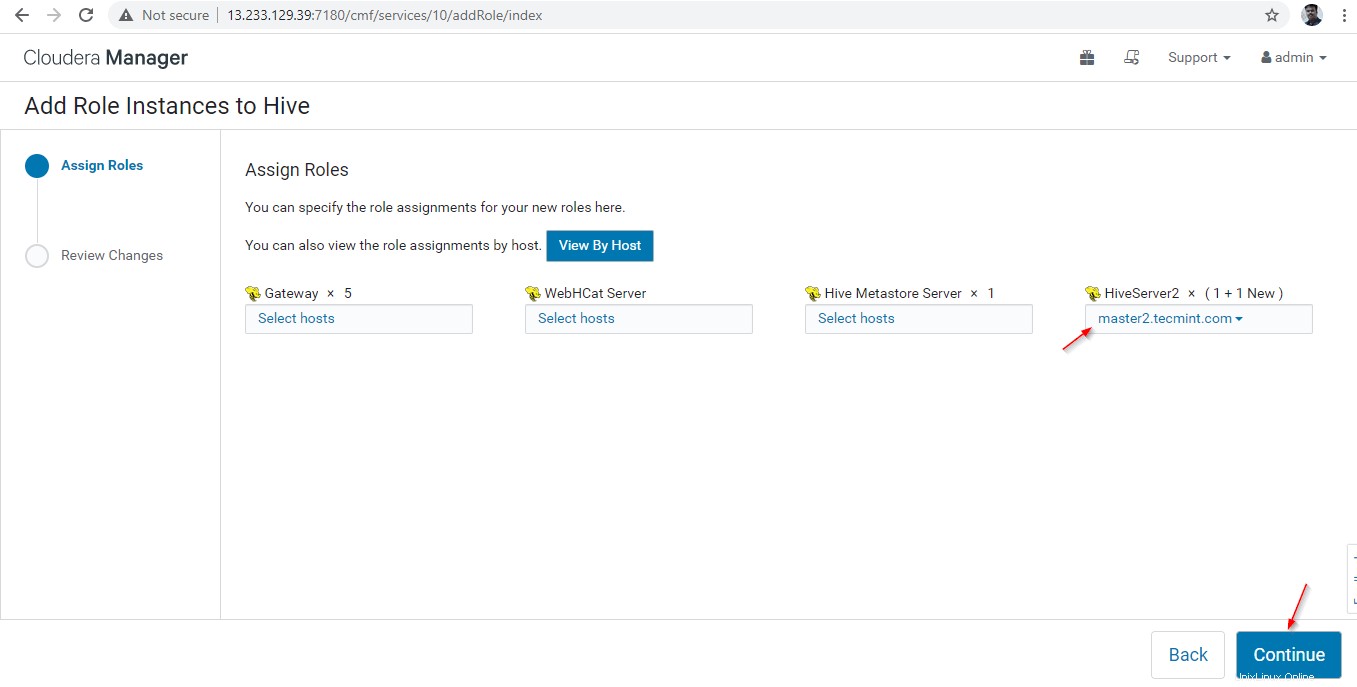
14. Un Hiverserver2 seront ajoutés aux Instances Hive , vous devez le démarrer en accédant à Cloudera Manager –> Ruche –> Instances –> (Sélectionnez Hiveserver2 ajouté récemment) -> Action pour la sélection –> Démarrer .
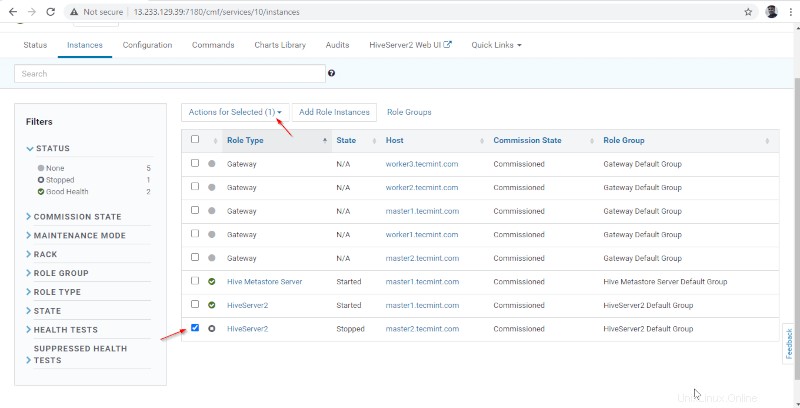
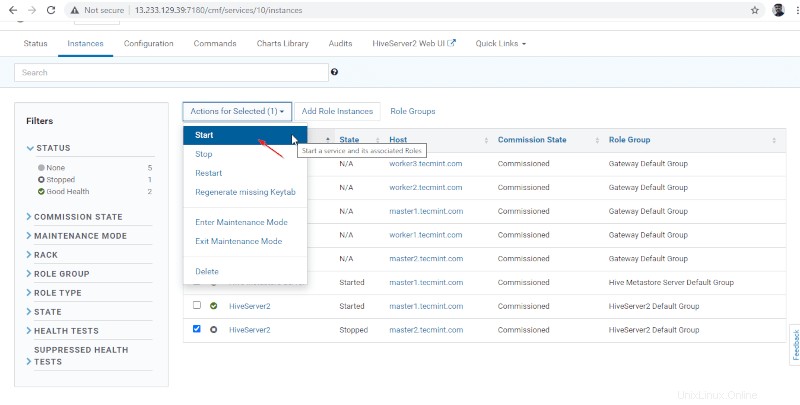
15. Une fois Hiveserver2 démarré sur master2 , vous obtiendrez le statut "Terminé '. Cliquez sur Fermer .
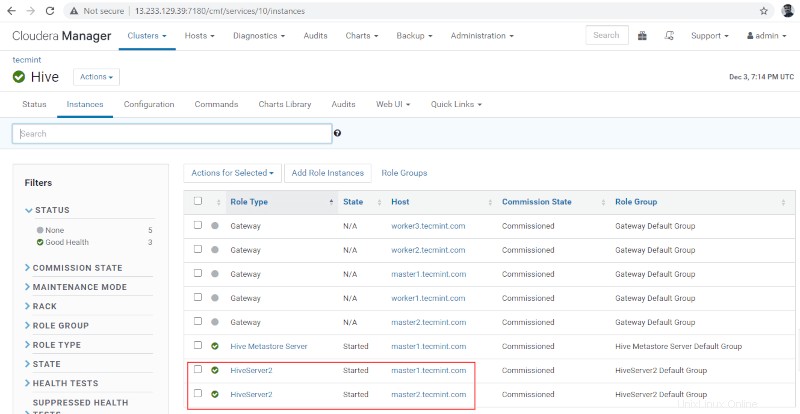
16. Vous pouvez afficher à la fois les Hiveserver2s sont en cours d'exécution.
Vérification de la disponibilité de Hive
Nous pouvons connecter le Hiveserver2 via le beeline qui est un client léger et une ligne de commande. Il utilise le pilote JDBC pour établir la connexion.
17. Connectez-vous au serveur où Hive Gateway est en cours d'exécution.
[[email protected] ~]$ beeline

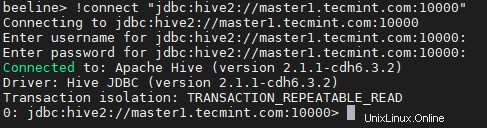
18. Entrez le JDBC chaîne de connexion pour connecter le Hiveserver2 . À cet égard, la chaîne nous mentionnons le Hiverserver2 (master2 ) avec son numéro de port par défaut 10000 . Cette chaîne de connexion se connectera uniquement au Hiveserver2 qui s'exécute sur master2 .
beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
19. Exécutez un exemple de requête.
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
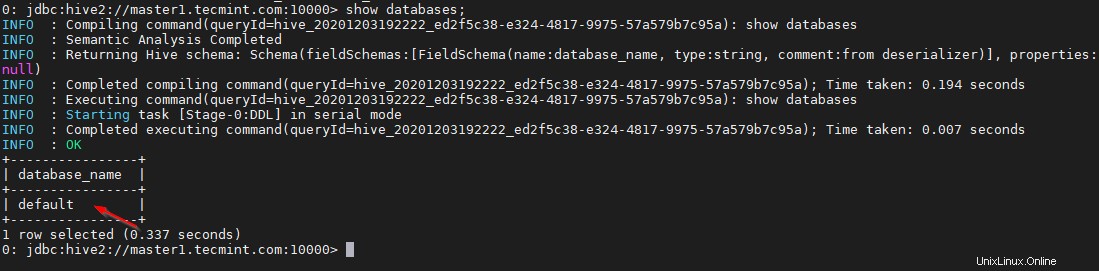
Il s'agit de la base de données par défaut qui est intégrée.
20. Utilisez la commande ci-dessous pour mettre fin à la session Hive.
0: jdbc:hive2://master1.tecmint.com:10000> !quit

21. Vous pouvez utiliser la même méthode pour connecter Hiveserver2 fonctionnant sur master2 .
beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
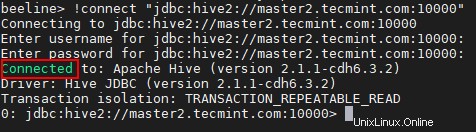
23. Nous pouvons connecter le Hiveserver2 dans Découverte Zookeeper mode. Dans cette méthode, nous n'avons pas besoin de mentionner le Hiveserver2 dans la chaîne de connexion à la place, nous utilisons Zookeeper pour découvrir le Hiveserver2 disponible .
Ici, nous pouvons utiliser un équilibreur de charge tiers pour équilibrer la charge entre les Hiverserver2 disponibles . La configuration ci-dessous est nécessaire pour activer le mode de découverte Zookeeper en allant dans Cloudera Manager –> Ruche –> Configuration .
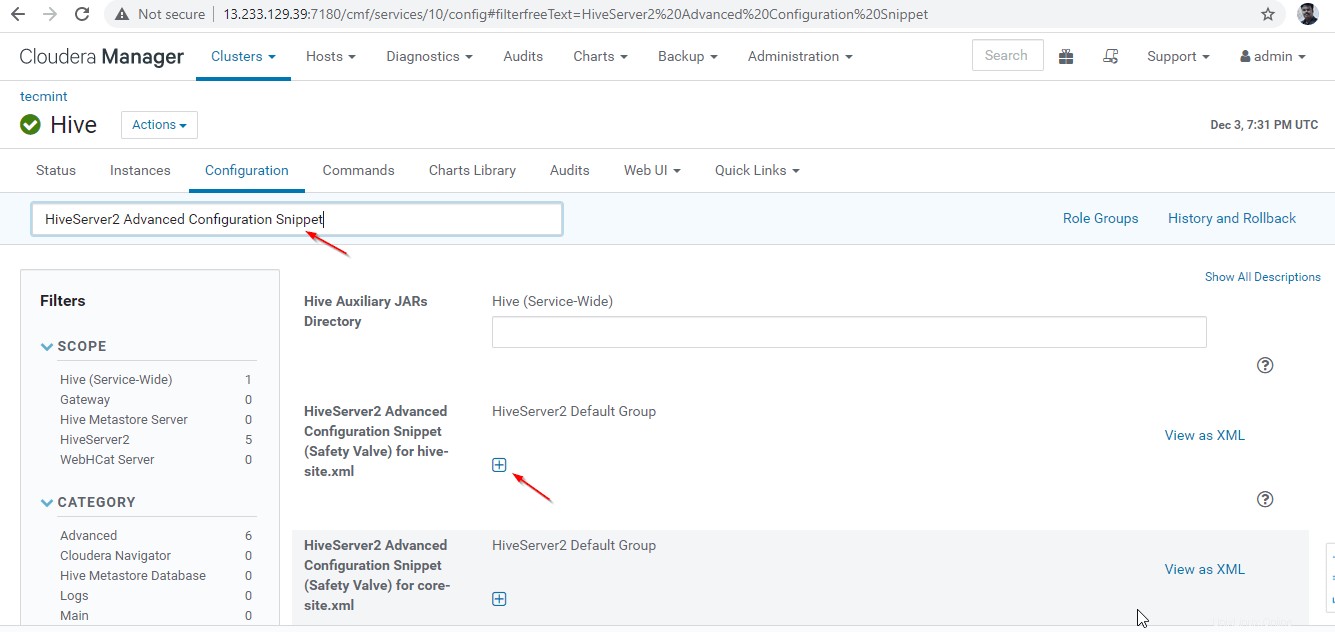
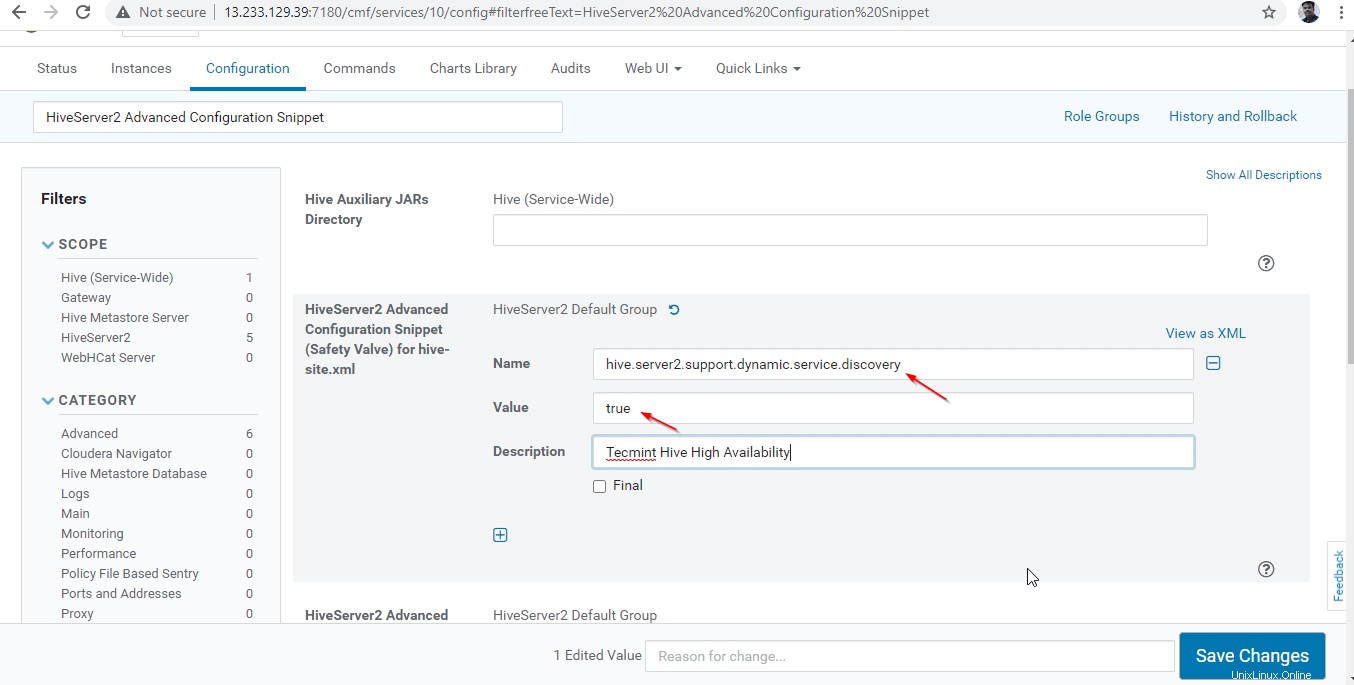
24. Ensuite, recherchez la propriété "HiveServer2 Advanced Configuration Snippet ” et cliquez sur le + symbole pour ajouter la propriété ci-dessous.
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
25. Une fois entré dans la propriété, cliquez sur "Enregistrer les modifications '.
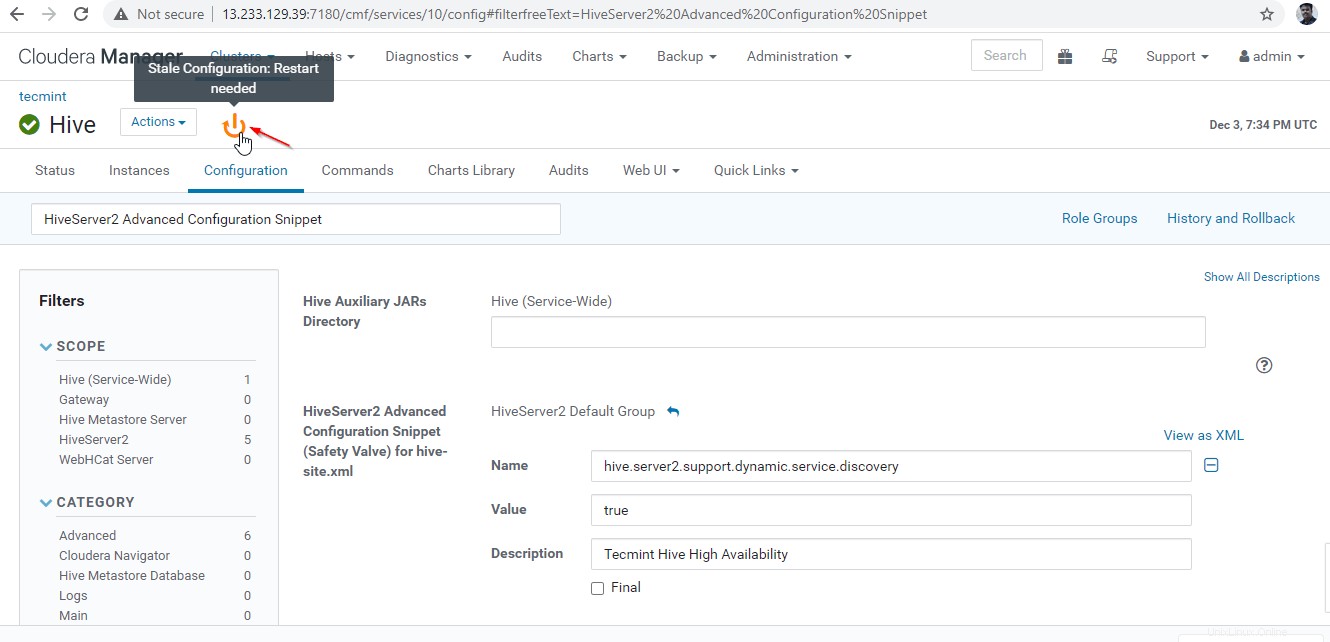
26. Comme nous avons apporté des modifications à la configuration, nous devons redémarrer les services concernés en cliquant sur le symbole de couleur orange pour redémarrer les services.
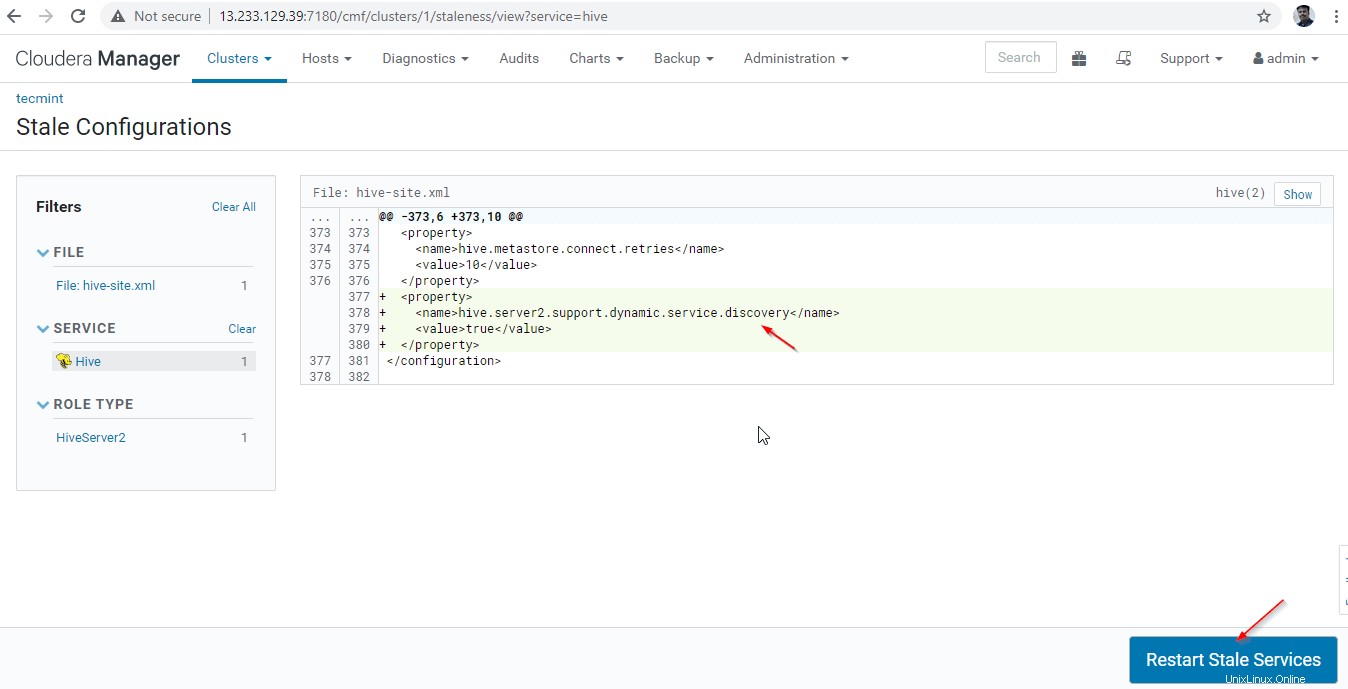
27. Cliquez sur 'Redémarrer l'historique " services.
28. Deux options sont disponibles. Si le cluster est en production, nous devons privilégier le redémarrage progressif pour minimiser la panne. Comme nous venons d'installer, nous pouvons choisir la deuxième option "Redéployer la configuration du client ', puis cliquez sur 'Redémarrer maintenant '.
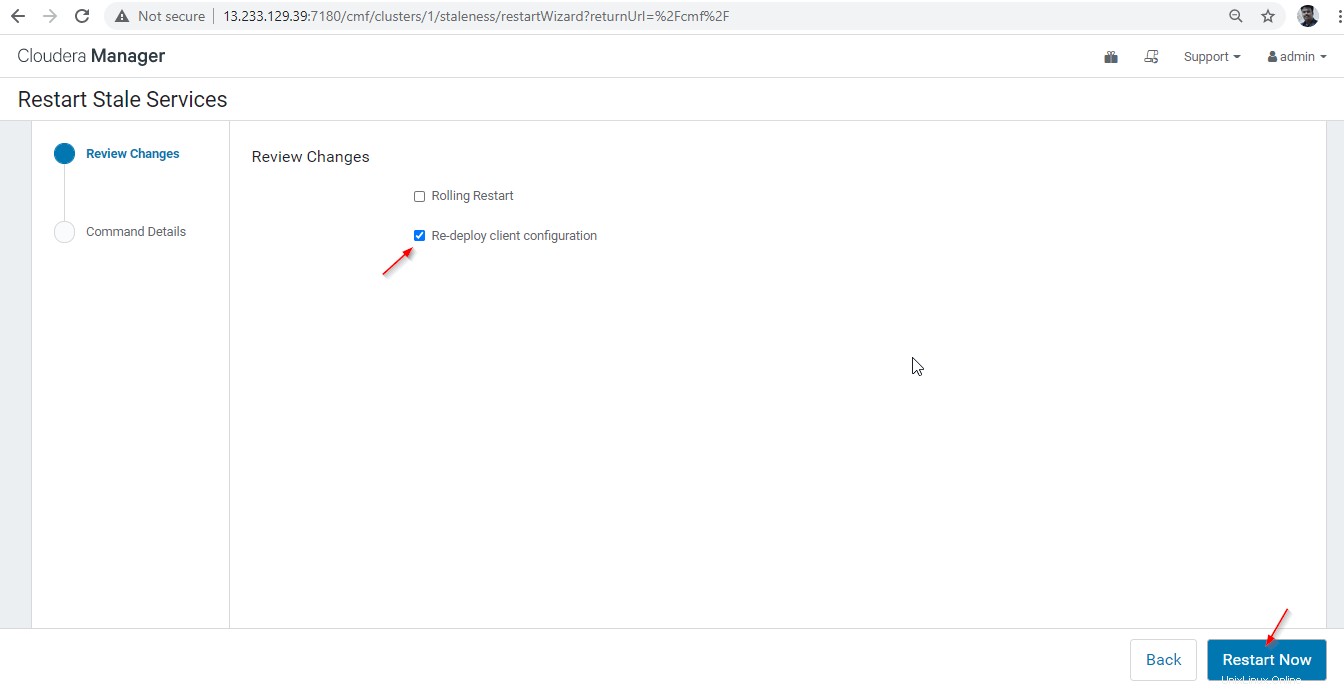
29. Une fois le redémarrage terminé avec succès, vous obtiendrez le statut "Terminé '. Cliquez sur 'Terminer ' pour terminer le processus.
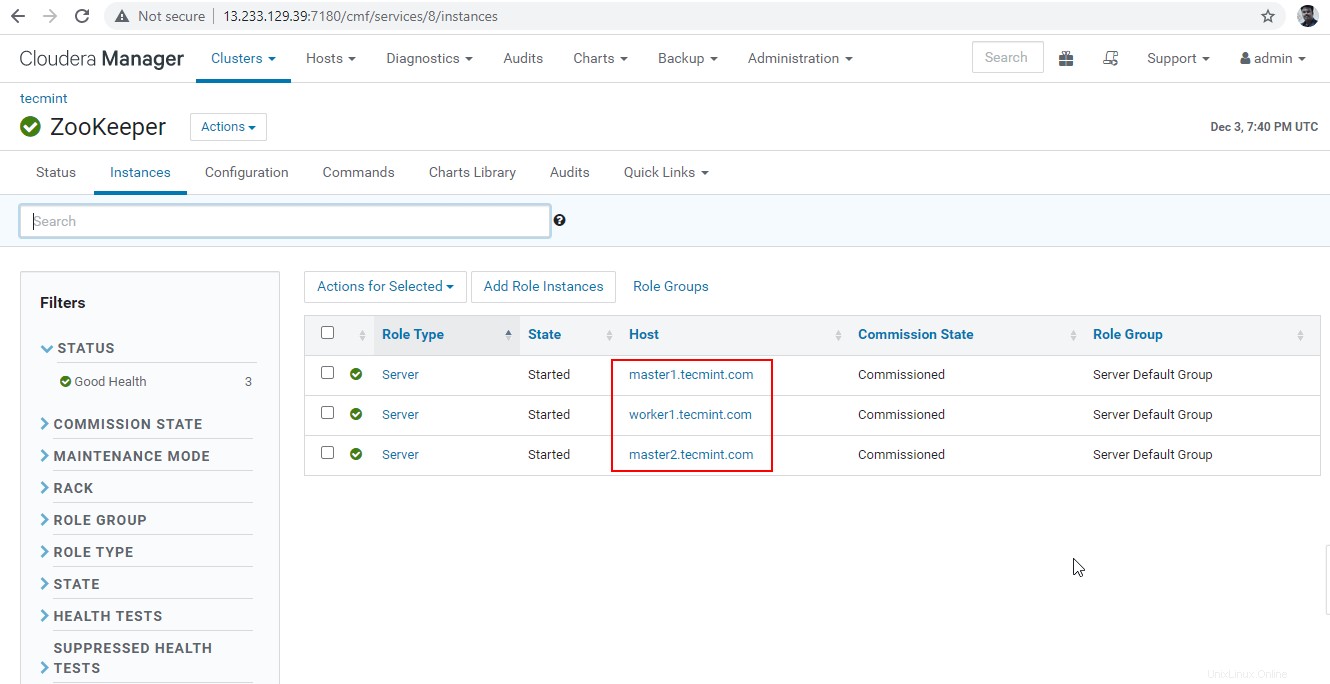
30. Nous allons maintenant connecter le Hiveserver2 en utilisant Zookeeper Discovery mode. Dans le JDBC connection, la chaîne dont nous avons besoin pour utiliser le Zookeeper serveurs avec son numéro de port 2081 . Récupérez les serveurs Zookeeper en accédant à Cloudera Manager –> Gardien de zoo –> Instances –> (Notez les noms des serveurs).
Ce sont les trois serveurs ayant Zookeeper, 2181 est le numéro de port.
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
31. Maintenant, entrez dans beeline .
[[email protected] ~]$ beeline

32. Entrez le JDBC chaîne de connexion comme mentionné ci-dessous. Nous devons mentionner le mode de découverte de service et Espace de noms Zookeeper . 'hiveserver2 ' est l'espace de noms par défaut de Hiveserver2.
beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

33. Maintenant, la session est connectée à Hiveserver2 s'exécutant sur master1 . Exécutez un exemple de requête pour valider. Utilisez la commande ci-dessous pour créer une base de données.
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

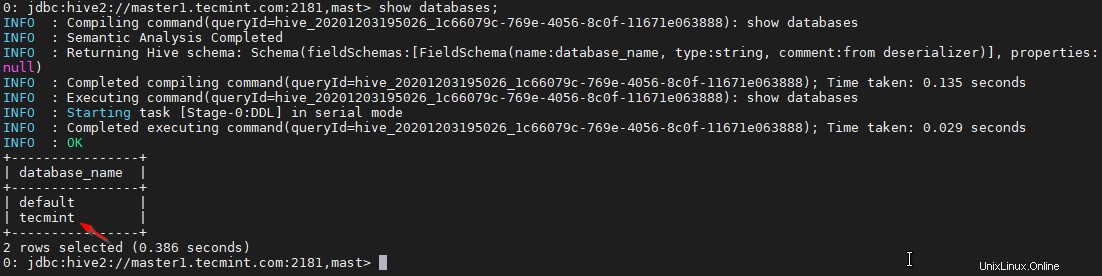
34. Utilisez la commande ci-dessous pour lister la base de données.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
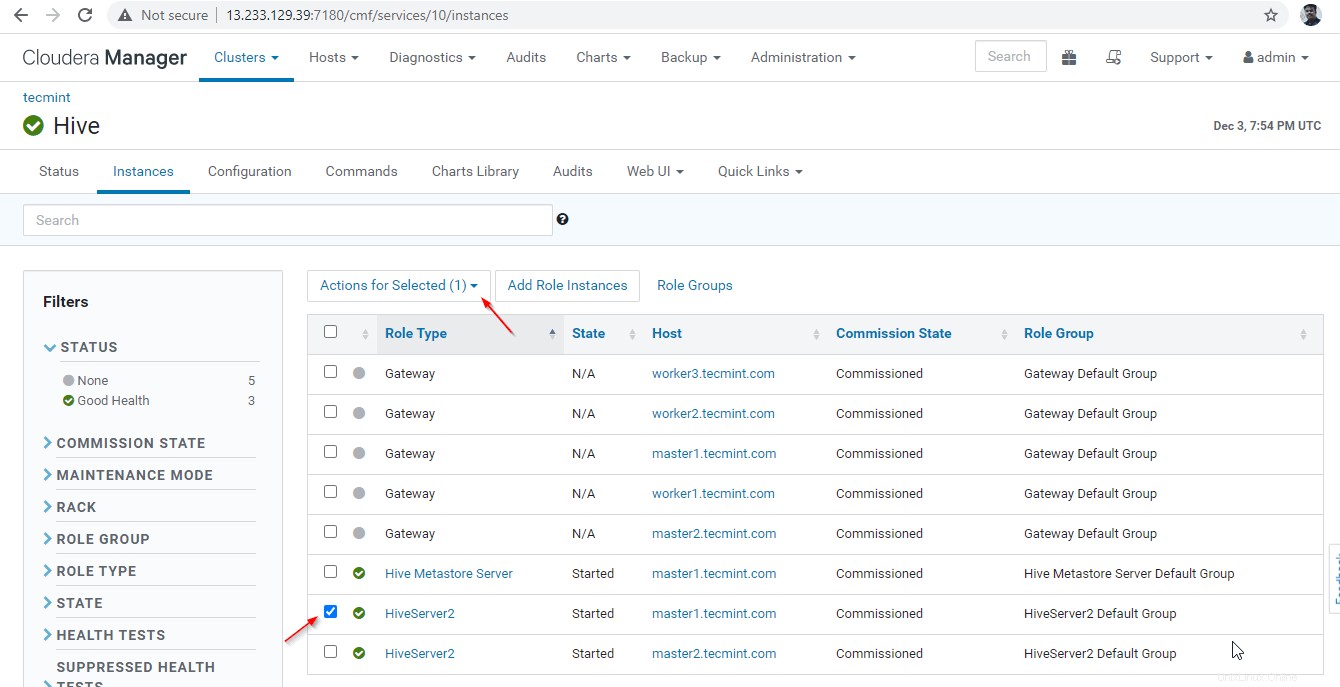
35. Nous allons maintenant valider la haute disponibilité en mode de découverte Zookeeper . Accédez à Gestionnaire Cloudera et arrêtez le Hiveserver2 sur master1 que nous avons testé ci-dessus.
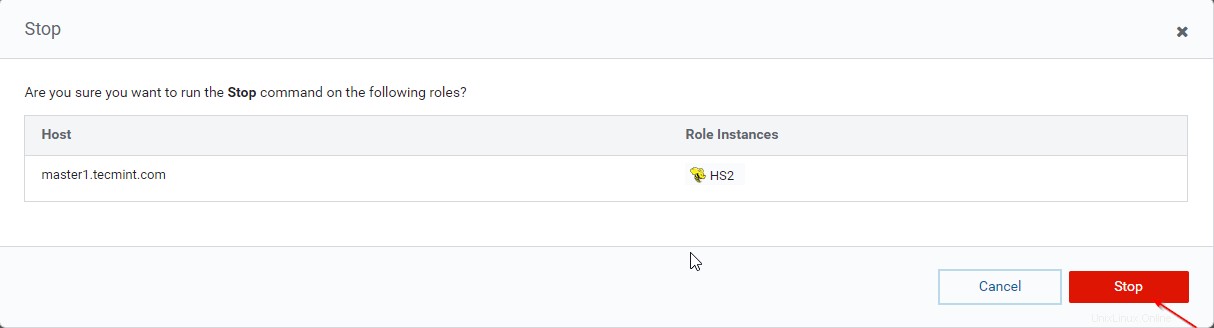
Gestionnaire Cloudera –> Ruche –> Instances –> (sélectionnez Hiveserver2 sur master1 ) –> Action pour la sélection –> Arrêter .
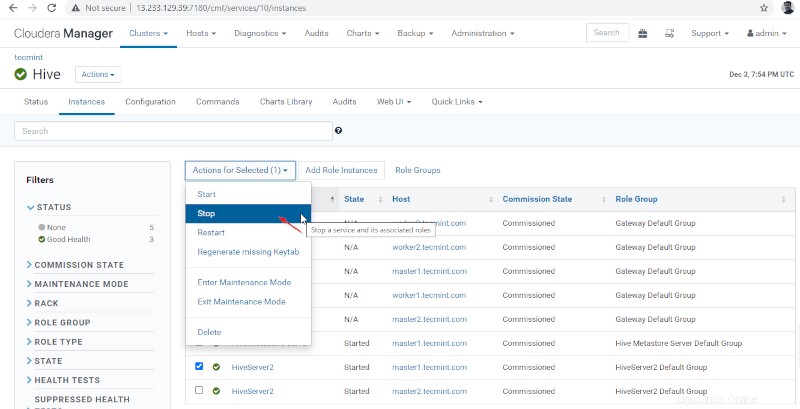
36. Cliquez sur "Arrêter '. Une fois arrêté, vous obtiendrez le statut "Terminé '. Vérifiez le Hiveserver2 sur master1 en naviguant dans Hive –> Instances .
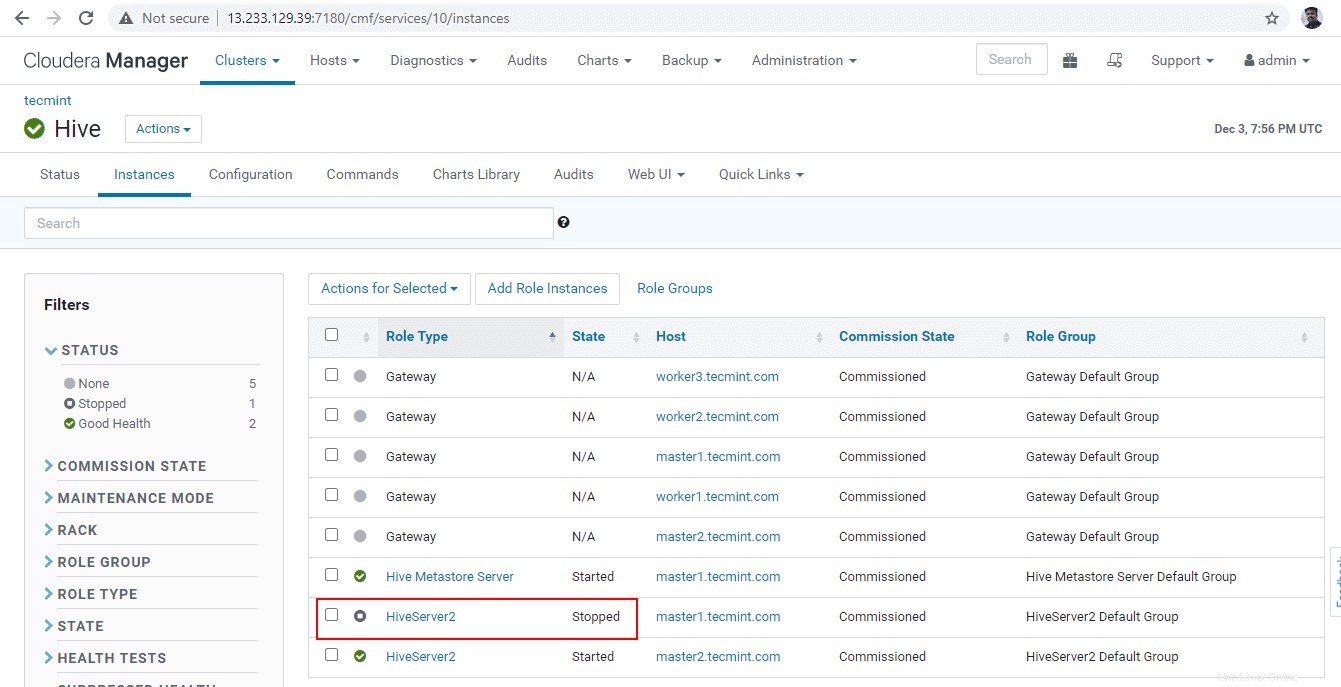
37. Entrez dans la ligne droite et connectez le Hiveserver2 en utilisant le même JDBC chaîne de connexion avec Zookeeper Discovery Mode comme nous l'avons fait dans les étapes ci-dessus.
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

Vous allez maintenant être connecté à Hiveserver2 fonctionnant sur master2 .
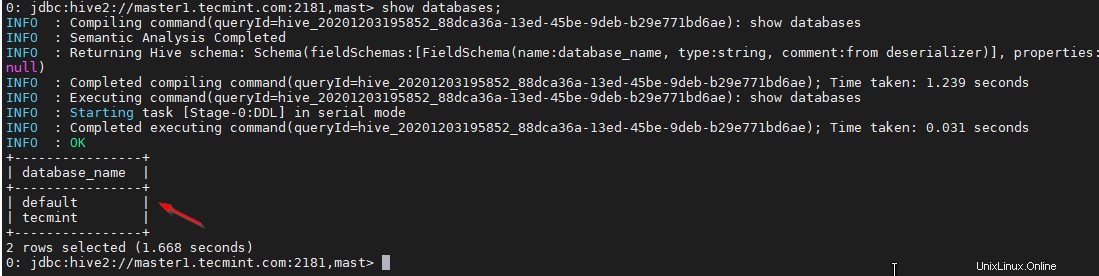
38. Validez avec un exemple de requête.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
Conclusion
Dans cet article, nous avons parcouru les étapes détaillées pour avoir le Hive Data Warehouse modèle dans notre Cluster avec haute disponibilité . Dans un environnement de production en temps réel, plus de trois Hiveserver2 sera placé avec le mode de découverte Zookeeper activé.
Ici, tous les Hiveserver2 s'inscrivent auprès de Zookeeper sous un espace de noms commun . Zookeeper dynamiquement découvre le Hiveserver2 disponible et établit la session Hive.