Présentation
Le but de la sauvegarde et de la réplication est d'empêcher une perte catastrophique de données due à des événements imprévus. Qu'il s'agisse d'une catastrophe naturelle, d'une défaillance du matériel sous-jacent ou d'un logiciel malveillant, vous devez disposer d'une stratégie de sauvegarde des données complète.
Décider du type de configuration de reprise après sinistre dont vous avez besoin est le premier et probablement le plus important aspect de la sécurisation et de la préservation de vos données. Mais connaissez-vous la différence entre la sauvegarde et la réplication ?
Ce bref article explore les différences entre la sauvegarde et la réplication.

Différence entre la sauvegarde et la réplication
Un aperçu des différences entre la sauvegarde et la réplication semble seulement souligner pourquoi elles sont, en fait, des options complémentaires plutôt qu'opposées.
| Sauvegarde | Réplication | |
|---|---|---|
| Coût | Faible coût par rapport à la réplication. Ne nécessite pas d'investissements importants en personnel ou en infrastructure. | Plus cher que la sauvegarde. Les plates-formes et solutions commerciales prêtes à l'emploi peuvent contribuer à réduire les coûts. |
| Exigences | Un disque local, une bibliothèque de bandes virtuelles ou un service de sauvegarde en ligne. Stockage discrétionnaire des données archivées. | Mise en œuvre de nouveaux processus métier, personnel supplémentaire et investissement dans l'infrastructure. |
| Idéal pour | Stockage des données à long terme et exigences liées à la conformité. | Assurer un accès continu aux applications critiques et destinées aux clients. |
| Avantages | - Simple à mettre en œuvre. - Haut niveau d'isolement des menaces potentielles. - Pas cher. | - Concentrez-vous sur la reprise après sinistre. - La haute disponibilité. - Une reprise rapide des opérations commerciales après une panne. |
| Lacunes | - L'intervalle de temps considérable entre les sauvegardes. - Long processus de récupération de données. | - Coûteux à entretenir (en particulier pour le stockage à long terme). - Les logiciels malveillants peuvent se propager aux données répliquées. |
Qu'est-ce qu'une sauvegarde de données ?
Outre l'utilisation d'un matériel fiable, Data Backup est l'un des principaux instruments de récupération de données. Les systèmes de sauvegarde modernes enregistrent généralement l'état d'un système entier et le font à intervalles réguliers. Cette copie enregistrée peut ensuite être conservée hors site en toute sécurité et utilisée pour restaurer les données d'origine si quelque chose arrive à l'emplacement principal. Vous revenez simplement à la copie la plus récente et enregistrez des informations précieuses qui seraient autrement irréversiblement perdues.
Data Backup est idéal pour stocker de grands ensembles de données statiques pendant des périodes prolongées. C'est la solution idéale pour de nombreuses industries qui doivent conserver des enregistrements fiables à long terme. Il existe plusieurs types de sauvegarde de données, généralement en fonction de la quantité de données à stocker et de la capacité des ressources disponibles.
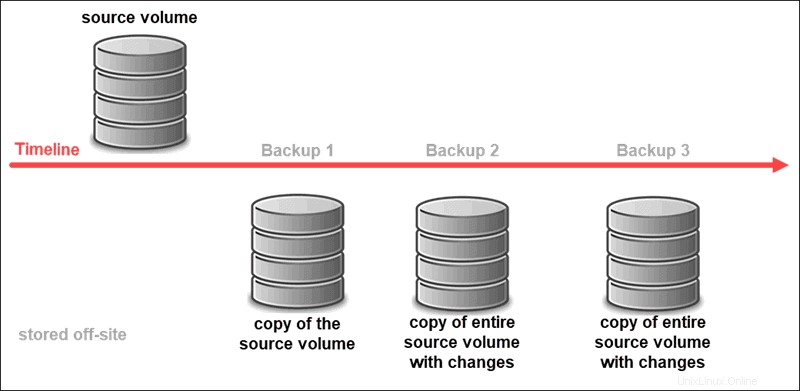
La sauvegarde d'un système entier peut peser lourdement sur les ressources et n'est pas effectuée à chaque minute de chaque jour. Cela signifie que la copie la plus récente date souvent de plusieurs heures, voire de plusieurs jours. La perte d'une petite quantité de données est parfaitement acceptable pour certaines entreprises, mais de nos jours, les utilisateurs s'attendent à une cohérence totale des données et à une haute disponibilité.
Le temps nécessaire pour récupérer la version la plus récente et la déployer dans un environnement de travail est un sérieux inconvénient. Votre système restera indisponible pour les utilisateurs jusqu'à ce que vous parveniez à récupérer et à déployer la copie. Certains de ces points faibles peuvent être renforcés avec la réplication des données .
Qu'est-ce que la réplication de données ?
La réplication de données est un terme général utilisé pour les technologies et les processus qui créent des copies de données, les synchronisent et les distribuent sur un réseau de serveurs et de centres de données. Un sinistre a un impact minimal sur l'accès aux données en raison du nombre de répliques. La disponibilité du système est extrêmement élevée et le processus de récupération peut généralement être mesuré en minutes. La réplication des données, à bien des égards, résout la plupart des inconvénients de la sauvegarde des données.
Alors pourquoi les entreprises utilisent-elles encore les deux ? Les répliques sont mises à jour en permanence et perdent donc rapidement leur état historique. Si vous n'utilisez que la réplication de données, vous auriez besoin d'un immense système parallèle pour prendre en charge les données répliquées, en particulier si vous devez conserver des enregistrements à long terme.
La réplication de données peut être gravement entravée par des logiciels malveillants. Comme les données sont répliquées dans l'ensemble d'un système, les logiciels malveillants peuvent également être répliqués. Sans une sauvegarde adéquate, il peut être impossible de revenir à un état exempt de logiciels malveillants.
C'est pourquoi la plupart des fournisseurs de services proposent à la fois des solutions de réplication et de sauvegarde pour maintenir une cohérence à long terme et une haute disponibilité.