Apache Spark est un cadre de calcul gratuit, open source, à usage général et distribué, créé pour fournir des résultats de calcul plus rapides. Il prend en charge plusieurs API pour le streaming, le traitement de graphes, notamment Java, Python, Scala et R. Généralement, Apache Spark peut être utilisé dans les clusters Hadoop, mais vous pouvez également l'installer en mode autonome.
Dans ce tutoriel, nous allons vous montrer comment installer le framework Apache Spark sur Debian 11.
Prérequis
- Un serveur exécutant Debian 11.
- Un mot de passe root est configuré sur le serveur.
Installer Java
Apache Spark est écrit en Java. Java doit donc être installé sur votre système. S'il n'est pas installé, vous pouvez l'installer à l'aide de la commande suivante :
apt-get install default-jdk curl -y
Une fois Java installé, vérifiez la version de Java à l'aide de la commande suivante :
java --version
Vous devriez obtenir le résultat suivant :
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Installer Apache Spark
Au moment de la rédaction de ce tutoriel, la dernière version d'Apache Spark est la 3.1.2. Vous pouvez le télécharger à l'aide de la commande suivante :
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Une fois le téléchargement terminé, extrayez le fichier téléchargé avec la commande suivante :
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
Ensuite, déplacez le répertoire extrait vers le /opt avec la commande suivante :
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Ensuite, modifiez le fichier ~/.bashrc et ajoutez la variable de chemin Spark :
nano ~/.bashrc
Ajoutez les lignes suivantes :
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Enregistrez et fermez le fichier puis activez la variable d'environnement Spark à l'aide de la commande suivante :
source ~/.bashrc
Démarrer Apache Spark
Vous pouvez maintenant exécuter la commande suivante pour démarrer le service maître Spark :
start-master.sh
Vous devriez obtenir le résultat suivant :
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
Par défaut, Apache Spark écoute sur le port 8080. Vous pouvez le vérifier à l'aide de la commande suivante :
ss -tunelp | grep 8080
Vous obtiendrez le résultat suivant :
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
Ensuite, démarrez le processus de travail Apache Spark à l'aide de la commande suivante :
start-slave.sh spark://your-server-ip:7077
Accéder à l'interface utilisateur Web Apache Spark
Vous pouvez désormais accéder à l'interface Web d'Apache Spark à l'aide de l'URL http://your-server-ip:8080 . Vous devriez voir le service maître et esclave Apache Spark sur l'écran suivant :
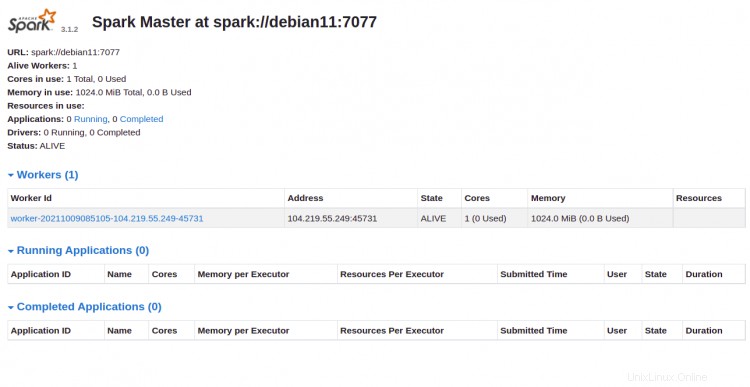
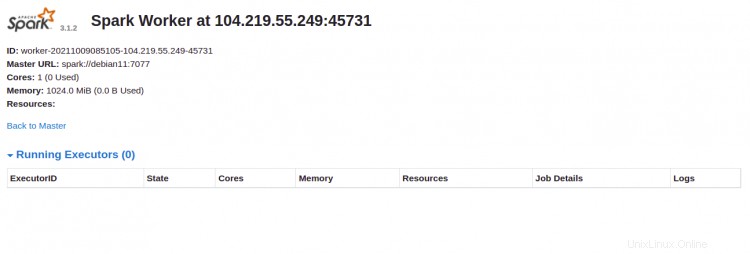
Cliquez sur le travailleur identifiant. Vous devriez voir les informations détaillées de votre travailleur sur l'écran suivant :
Connecter Apache Spark via la ligne de commande
Si vous souhaitez vous connecter à Spark via son shell de commande, exécutez les commandes ci-dessous :
spark-shell
Une fois connecté, vous obtiendrez l'interface suivante :
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Si vous souhaitez utiliser Python dans Spark. Vous pouvez utiliser l'utilitaire de ligne de commande pyspark.
Tout d'abord, installez la version 2 de Python avec la commande suivante :
apt-get install python -y
Une fois installé, vous pouvez connecter le Spark avec la commande suivante :
pyspark
Une fois connecté, vous devriez obtenir le résultat suivant :
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Arrêter maître et esclave
Tout d'abord, arrêtez le processus esclave à l'aide de la commande suivante :
stop-slave.sh
Vous obtiendrez le résultat suivant :
stopping org.apache.spark.deploy.worker.Worker
Ensuite, arrêtez le processus maître à l'aide de la commande suivante :
stop-master.sh
Vous obtiendrez le résultat suivant :
stopping org.apache.spark.deploy.master.Master
Conclusion
Toutes nos félicitations! vous avez installé avec succès Apache Spark sur Debian 11. Vous pouvez maintenant utiliser Apache Spark dans votre organisation pour traiter de grands ensembles de données