Pour travailler avec succès avec l'éditeur Linux sed et la commande awk dans vos scripts shell, vous devez comprendre les expressions régulières ou en bref regex. Puisqu'il existe de nombreux moteurs pour les regex, nous allons utiliser la regex shell et voir la puissance de bash en travaillant avec regex.
Tout d'abord, nous devons comprendre ce qu'est la regex ; nous verrons ensuite comment l'utiliser.
Qu'est-ce qu'une expression régulière
Pour certaines personnes, quand elles voient les expressions régulières pour la première fois, elles se disent c'est quoi ces vomi ASCII !!
Eh bien, une expression régulière ou regex, en général, est un modèle de texte que vous définissez qu'un programme Linux comme sed ou awk utilise pour filtrer le texte.
Nous avons vu certains de ces modèles lors de l'introduction des commandes Linux de base et avons vu comment la commande ls utilise des caractères génériques pour filtrer la sortie.
Types d'expressions régulières
De nombreuses applications différentes utilisent différents types de regex sous Linux, comme la regex incluse dans les langages de programmation (Java, Perl, Python,) et les programmes Linux comme (sed, awk, grep,) et de nombreuses autres applications.
Un modèle regex utilise un moteur d'expressions régulières qui traduit ces modèles.
Linux a deux moteurs d'expressions régulières :
- L'expression régulière de base (BRE) moteur.
- L'expression régulière étendue (ERE) moteur.
La plupart des programmes Linux fonctionnent bien avec les spécifications du moteur BRE, mais certains outils comme sed comprennent certaines des règles du moteur BRE.
Le moteur POSIX ERE est fourni avec certains langages de programmation. Il fournit plus de modèles, comme la correspondance des chiffres et des mots. La commande awk utilise le moteur ERE pour traiter ses modèles d'expressions régulières.
Comme il existe de nombreuses implémentations de regex, il est difficile d'écrire des modèles qui fonctionnent sur tous les moteurs. Par conséquent, nous nous concentrerons sur l'expression régulière la plus courante et montrerons comment l'utiliser dans sed et awk.
Définir les modèles BRE
Vous pouvez définir un modèle pour faire correspondre le texte comme ceci :
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Vous remarquerez peut-être que l'expression régulière ne se soucie pas de l'endroit où le modèle se produit ou du nombre de fois dans le flux de données.
La première règle à connaître est que les modèles d'expression régulière sont sensibles à la casse.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

La première expression régulière réussit car le mot "Geeks" existe en majuscules, tandis que la deuxième ligne échoue car elle utilise des lettres minuscules.
Vous pouvez utiliser des espaces ou des nombres dans votre modèle comme ceci :
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Caractères spéciaux
Les modèles regex utilisent des caractères spéciaux. Et vous ne pouvez pas les inclure dans vos modèles, et si vous le faites, vous n'obtiendrez pas le résultat escompté.
Ces caractères spéciaux sont reconnus par regex :
.*[]^${}\+?|() Vous devez échapper ces caractères spéciaux en utilisant le caractère barre oblique inverse (\).
Par exemple, si vous voulez faire correspondre un signe dollar ($), échappez-le avec une barre oblique inverse comme ceci :
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Si vous devez faire correspondre la barre oblique inverse (\) elle-même, vous devez l'échapper comme ceci :
$ echo "\ is a special character" | awk '/\\/{print $0}'

Bien que la barre oblique ne soit pas un caractère spécial, vous obtenez toujours une erreur si vous l'utilisez directement.
$ echo "3 / 2" | awk '///{print $0}'

Vous devez donc vous en sortir comme ceci :
$ echo "3 / 2" | awk '/\//{print $0}'

Caractères d'ancrage
Pour localiser le début d'une ligne dans un texte, utilisez le caractère caret (^).
Vous pouvez l'utiliser comme ceci :
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

Le signe insertion (^) correspond au début du texte :
$ awk '/^this/{print $0}' myfile

Et si vous l'utilisiez au milieu du texte ?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Il est imprimé tel quel comme un caractère normal.
Lorsque vous utilisez awk, vous devez l'échapper comme ceci :
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Il s'agit de regarder le début du texte, qu'en est-il de regarder la fin ?
Le signe dollar ($) vérifie la fin d'une ligne :
$ echo "Testing regex again" | awk '/again$/{print $0}'

Vous pouvez utiliser à la fois le signe caret et le signe dollar sur la même ligne comme ceci :
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
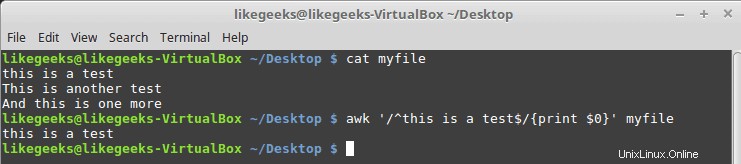
Comme vous pouvez le voir, il n'imprime que la ligne qui a le motif correspondant uniquement.
Vous pouvez filtrer les lignes vides avec le modèle suivant :
$ awk '!/^$/{print $0}' myfile Ici nous introduisons la négation que vous pouvez faire par le point d'exclamation !
Le modèle recherche les lignes vides où il n'y a rien entre le début et la fin de la ligne et annule le fait d'imprimer uniquement les lignes contenant du texte.
Le caractère point
Nous utilisons le caractère point pour correspondre à n'importe quel caractère sauf le retour à la ligne (\n).
Regardez l'exemple suivant pour vous faire une idée :
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
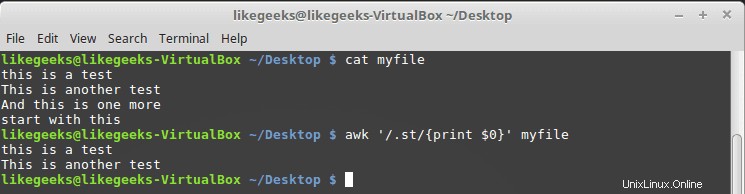
Vous pouvez voir d'après le résultat qu'il n'imprime que les deux premières lignes car elles contiennent le motif st alors que la troisième ligne n'a pas ce motif, et la quatrième ligne commence par st, donc cela ne correspond pas non plus à notre motif.
Classes de personnages
Vous pouvez faire correspondre n'importe quel caractère avec le caractère spécial point, mais si vous ne faites correspondre qu'un ensemble de caractères, vous pouvez utiliser une classe de caractères.
La classe de caractères correspond à un ensemble de caractères si l'un d'entre eux est trouvé, le modèle correspond.
Nous pouvons définir les classes de caractères en utilisant des crochets [] comme ceci :
$ awk '/[oi]th/{print $0}' myfile
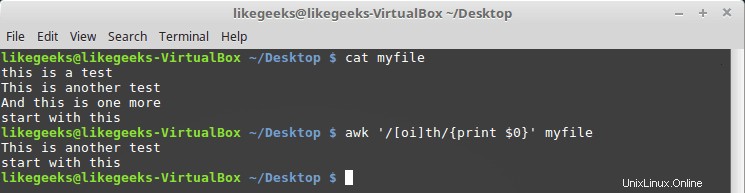
Ici, nous recherchons tous les caractères e précédés du caractère o ou i.
Cela s'avère pratique lorsque vous recherchez des mots qui peuvent contenir des majuscules ou des minuscules, et que vous n'êtes pas sûr de cela.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Bien sûr, cela ne se limite pas aux personnages; vous pouvez utiliser des chiffres ou tout ce que vous voulez. Vous pouvez l'utiliser comme vous le souhaitez tant que vous avez l'idée.
Négation des classes de caractères
Qu'en est-il de la recherche d'un personnage qui n'appartient pas à la classe de personnages ?
Pour ce faire, faites précéder la plage de classes de caractères d'un accent circonflexe comme celui-ci :
$ awk '/[^oi]th/{print $0}' myfile
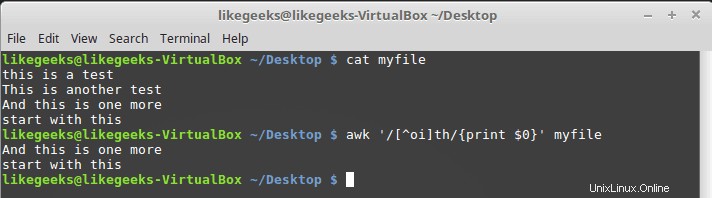
Donc tout est acceptable sauf o et i.
Utiliser des plages
Pour spécifier une plage de caractères, vous pouvez utiliser le symbole (-) comme ceci :
$ awk '/[e-p]st/{print $0}' myfile
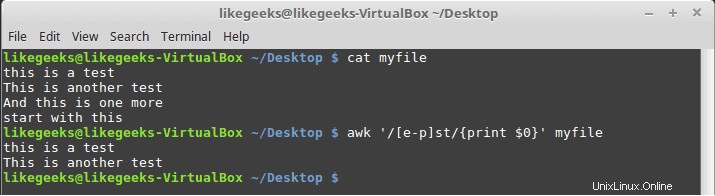
Cela correspond à tous les caractères entre e et p suivis de st comme indiqué.
Vous pouvez également utiliser des plages pour les nombres :
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Vous pouvez utiliser plusieurs plages séparées comme ceci :
$ awk '/[a-fm-z]st/{print $0}' myfile
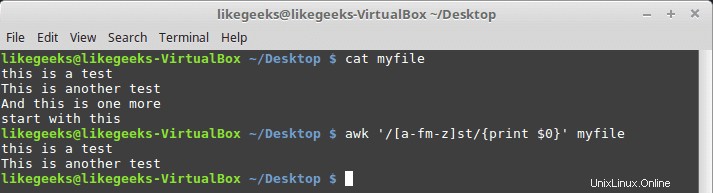
Le motif signifie ici de a à f, et m à z doit apparaître avant le er texte.
Classes de personnages spéciaux
La liste suivante comprend les classes de caractères spéciaux que vous pouvez utiliser :
| [[:alnum :]] | Modèle pour 0–9, A–Z ou a–z. |
| [[:vide :]] | Modèle pour l'espace ou la tabulation uniquement. |
| [[:chiffre :]] | Modèle pour 0 à 9. |
| [[:lower :]] | Modèle pour a–z minuscules uniquement. |
| [[:print :]] | Modèle pour tout caractère imprimable. |
| [[:punct:]] | Modèle pour tout caractère de ponctuation. |
| [[:space :]] | Modèle pour tout caractère d'espace :espace, tabulation, NL, FF, VT, CR. |
| [[:upper :]] | Modèle pour les majuscules de A à Z uniquement. |
Vous pouvez les utiliser comme ceci :
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

L'astérisque
L'astérisque signifie que le caractère doit exister zéro ou plusieurs fois.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Ce symbole de modèle est utile pour vérifier les fautes d'orthographe ou les variations de langue.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

Ici, dans ces exemples, que vous le saisissiez en couleur ou en couleur, il correspondra, car l'astérisque signifie que si le caractère "u" a existé plusieurs fois ou zéro fois, cela correspondra.
Pour faire correspondre n'importe quel nombre de n'importe quel caractère, vous pouvez utiliser le point avec l'astérisque comme ceci :
$ awk '/this.*test/{print $0}' myfile
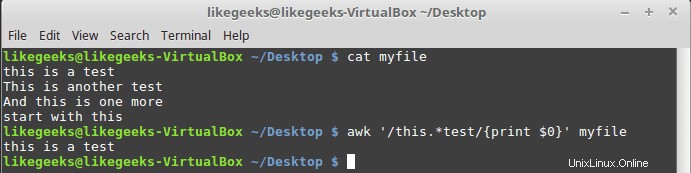
Peu importe le nombre de mots entre les mots "ceci" et "test", toutes les correspondances de ligne seront imprimées.
Vous pouvez utiliser le caractère astérisque avec la classe de caractères.
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
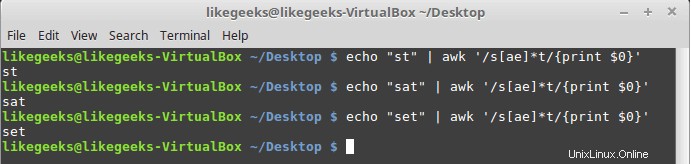
Les trois exemples correspondent car l'astérisque signifie que si vous trouvez zéro fois ou plus un caractère "a" ou "e", imprimez-le.
Expressions régulières étendues
Voici quelques-uns des modèles appartenant à Posix ERE :
Le point d'interrogation
Le point d'interrogation signifie que le caractère précédent peut exister une fois ou aucun.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}'
Nous pouvons utiliser le point d'interrogation en combinaison avec une classe de caractères :
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
Si l'un des éléments de la classe de caractères existe, la correspondance de modèle réussit. Sinon, le modèle échouera.
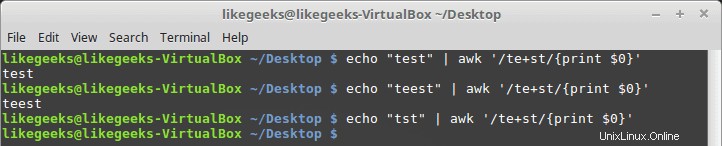
Le signe plus
Le signe plus signifie que le caractère avant le signe plus doit exister une ou plusieurs fois, mais doit exister au moins une fois.
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Si le caractère "e" n'est pas trouvé, il échoue.
Vous pouvez l'utiliser avec des classes de personnages comme celle-ci :
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
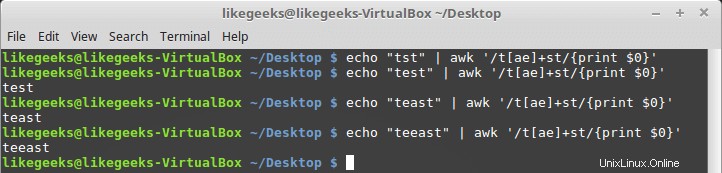
si un caractère de la classe de caractères existe, il réussit.
Les accolades
Les accolades permettent de spécifier le nombre d'existence d'un motif, il a deux formats :
n :l'expression régulière apparaît exactement n fois.
n,m :la regex apparaît au moins n fois, mais pas plus de m fois.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

Dans les anciennes versions d'awk, vous devez utiliser l'option –re-interval pour la commande awk afin qu'elle lise les accolades, mais dans les versions plus récentes, vous n'en avez pas besoin.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

Dans cet exemple, si le caractère « e » existe une ou deux fois, il réussit; sinon, il échoue.
Vous pouvez l'utiliser avec des classes de personnages comme celle-ci :
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
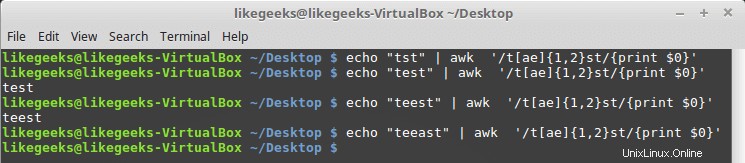
S'il y a une ou deux occurrences de la lettre « a » ou « e », le modèle passe; sinon, il échoue.
Symbole de tuyau
Le symbole du tuyau fait un OU logique entre 2 modèles. Si l'un des modèles existe, il réussit ; sinon, ça échoue, voici un exemple :
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
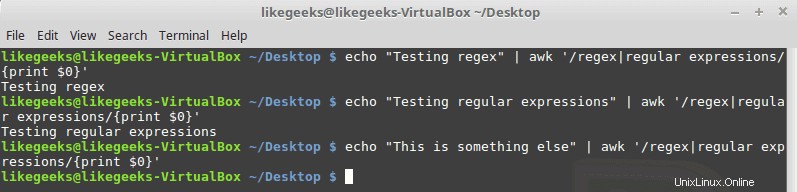
Ne tapez aucun espace entre le motif et le symbole du tuyau.
Regroupement d'expressions
Vous pouvez regrouper des expressions afin que les moteurs de regex les considèrent comme une seule pièce.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Le regroupement des "Geeks" fait que le moteur regex le traite comme une seule pièce, donc si "LikeGeeks" ou le mot "Like" existe, il réussit.
Exemples pratiques
Nous avons vu quelques démonstrations simples d'utilisation de modèles d'expressions régulières. Il est temps de mettre cela en action, juste pour s'entraîner.
Compter les fichiers du répertoire
Regardons un script bash qui compte les fichiers exécutables dans un dossier à partir de la variable d'environnement PATH.
$ echo $PATH
Pour obtenir une liste de répertoires, vous devez remplacer chaque deux-points par un espace.
$ echo $PATH | sed 's/:/ /g'
Parcourons maintenant chaque répertoire en utilisant la boucle for comme ceci :
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Génial !
Vous pouvez obtenir les fichiers de chaque répertoire à l'aide de la commande ls et les enregistrer dans une variable.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Vous remarquerez peut-être que certains répertoires n'existent pas, pas de problème avec cela, ça va.
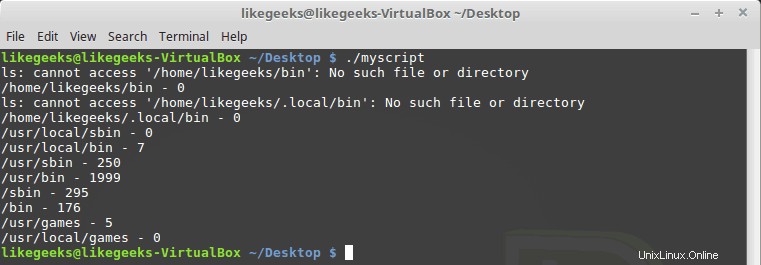
Cool!! C'est la puissance de regex - ces quelques lignes de code comptent tous les fichiers dans tous les répertoires. Bien sûr, il existe une commande Linux pour le faire très facilement, mais nous expliquons ici comment utiliser regex sur quelque chose que vous pouvez utiliser. Vous pouvez trouver des idées plus utiles.
Validation de l'adresse e-mail
Il existe une tonne de sites Web qui proposent des modèles regex prêts à l'emploi pour tout, y compris les e-mails, les numéros de téléphone et bien plus encore, c'est pratique, mais nous voulons comprendre comment cela fonctionne.
exemple@unixlinux.online
Le nom d'utilisateur peut utiliser n'importe quel caractère alphanumérique combiné avec un point, un tiret, un signe plus, un trait de soulignement.
Le nom d'hôte peut utiliser n'importe quel caractère alphanumérique combiné avec un point et un trait de soulignement.
Pour le nom d'utilisateur, le modèle suivant convient à tous les noms d'utilisateur :
^([a-zA-Z0-9_\-\.\+]+)@
Le signe plus signifie qu'un caractère ou plus doit exister suivi du signe @.
Ensuite, le modèle de nom d'hôte devrait ressembler à ceci :
([a-zA-Z0-9_\-\.]+)
Il existe des règles spéciales pour les TLD ou les domaines de premier niveau, et ils ne doivent pas être inférieurs à 2 et cinq caractères maximum. Voici le modèle regex pour le domaine de premier niveau.
\.([a-zA-Z]{2,5})$ Maintenant, nous les mettons tous ensemble :
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Testons cette expression régulière par rapport à un e-mail :
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Génial !
Ce n'était que le début du monde des regex qui ne finit jamais. J'espère que vous comprenez ces vomi ASCII 🙂 et que vous les utilisez de manière plus professionnelle.
J'espère que vous aimez le message.
Merci.