Lorsque vous utilisez un traitement de texte, le formatage du texte afin que les lignes tiennent dans l'espace disponible sur l'appareil cible ne devrait pas poser de problème. Mais quand on travaille au terminal, les choses ne sont pas si simples.
Bien sûr, vous pouvez toujours couper les lignes à la main à l'aide de votre éditeur de texte préféré, mais cela est rarement souhaitable et même hors de question pour un traitement automatisé.
Espérons que le POSIX fold utilitaire et GNU/BSD fmt La commande peut vous aider à redistribuer un texte afin que les lignes ne dépassent pas une longueur donnée.
Qu'est-ce qu'une ligne sous Unix, déjà ?
Avant d'entrer dans les détails du fold et fmt commandes, définissons d'abord de quoi nous parlons. Dans un fichier texte, une ligne est constituée d'un nombre arbitraire de caractères, suivis de la séquence spéciale de contrôle de saut de ligne (parfois appelée EOL, pour end-of-line )
Sur les systèmes de type Unix, la séquence de contrôle de fin de ligne est constituée du (un seul et unique) caractère saut de ligne , parfois abrégé LF ou écrit \n suivant une convention héritée du langage C. Au niveau binaire, le caractère de saut de ligne est représenté par un octet contenant le 0a valeur hexadécimale.
Vous pouvez facilement vérifier cela en utilisant le hexdump utilitaire que nous utiliserons beaucoup dans cet article. Cela peut donc être une bonne occasion de vous familiariser avec cet outil. Vous pouvez, par exemple, examiner les vidages hexadécimaux ci-dessous pour trouver combien de caractères de saut de ligne ont été envoyés par chaque commande echo. Une fois que vous pensez avoir la solution, réessayez simplement ces commandes sans le | hexdump -C partie pour voir si vous l'avez deviné correctement.
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
Il convient de mentionner à ce stade que différents systèmes d'exploitation peuvent suivre différentes règles concernant la séquence de retour à la ligne. Comme nous l'avons vu ci-dessus, les systèmes d'exploitation de type Unix utilisent le saut de ligne caractère, mais Windows, comme la plupart des protocoles Internet, utilise deux caractères :le retour chariot + saut de ligne paire (CRLF, ou 0d 0a , ou \r\n ). Sur Mac OS "classique" (jusqu'à MacOS 9.2 inclus au début des années 2000), les ordinateurs Apple utilisaient le CR seul comme caractère de nouvelle ligne. D'autres ordinateurs hérités utilisaient également la paire LFCR, ou même des séquences d'octets complètement différentes dans le cas d'anciens systèmes incompatibles avec l'ASCII. Heureusement, ces derniers sont des reliques du passé, et je doute que vous voyiez un ordinateur EBCDIC en service aujourd'hui !
En parlant d'histoire, si vous êtes curieux, l'utilisation des caractères de contrôle "retour chariot" et "saut de ligne" remonte au code Baudot utilisé à l'époque du téléscripteur. Vous avez peut-être vu le téléscripteur décrit dans de vieux films comme une interface avec un ordinateur de la taille d'une pièce. Mais même avant cela, les téléscripteurs étaient utilisés "de manière autonome" pour la communication point à point ou multipoint. À cette époque, un terminal typique ressemblait à une lourde machine à écrire avec un clavier mécanique, du papier et un chariot mobile tenant la tête d'impression. Pour commencer une nouvelle ligne, le chariot doit être ramené à l'extrême gauche, et le papier doit se déplacer vers le haut en faisant tourner la platine (parfois appelée « cylindre »). Ces deux mouvements étaient contrôlés par deux systèmes électromécaniques indépendants, les caractères de commande de saut de ligne et de retour chariot étant directement câblés à ces deux parties de l'appareil. Étant donné que le déplacement du chariot nécessite plus de temps que la rotation du plateau, il était logique d'initier le retour chariot en premier. Séparer les deux fonctions a également eu quelques effets secondaires intéressants, comme permettre la surimpression (en envoyant uniquement le CR) ou la transmission efficace du "double interligne" (un CR + deux LF).
La définition au début de cette section décrit principalement ce qu'est une logique ligne est. La plupart du temps, cependant, cette ligne logique "arbitrairement longue" doit être envoyée sur un réseau physique périphérique comme un écran ou une imprimante, où l'espace disponible est limité. L'affichage de lignes logiques courtes sur un périphérique ayant des lignes physiques plus grandes n'est pas un problème. Il y a simplement un espace inutilisé à droite du texte. Mais que se passe-t-il si vous essayez d'afficher une ligne de texte plus grande que l'espace disponible sur l'appareil ? En fait, il existe deux solutions, chacune avec son lot d'inconvénients :
- Tout d'abord, l'appareil peut tronquer les lignes à sa taille physique, cachant ainsi une partie du contenu à l'utilisateur. Certaines imprimantes le font, en particulier les imprimantes stupides (et oui, il existe encore des imprimantes matricielles basiques utilisées aujourd'hui, en particulier dans les environnements difficiles ou sales !)
- La deuxième option pour afficher de longues lignes logiques consiste à les diviser en plusieurs lignes physiques. C'est ce qu'on appelle le retour à la ligne car les lignes semblent s'enrouler autour de l'espace disponible, un effet particulièrement visible si vous pouvez redimensionner l'affichage comme lorsque vous travaillez avec un émulateur de terminal.
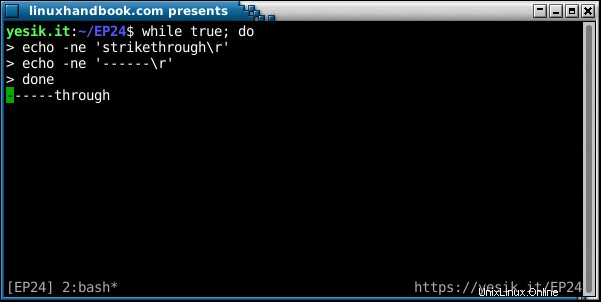
Ces comportements automatiques sont très utiles, mais il arrive encore que vous souhaitiez couper de longues lignes à une position donnée, quelle que soit la taille physique de l'appareil. Par exemple, cela peut être utile si vous souhaitez que les sauts de ligne se produisent à la même position à la fois sur l'écran et sur l'imprimante. Ou parce que vous souhaitez que votre texte soit utilisé dans une application qui n'effectue pas de retour à la ligne (par exemple, si vous intégrez par programme du texte dans un fichier SVG). Enfin, croyez-le ou non, il existe encore de nombreux protocoles de communication qui imposent une largeur de ligne maximale dans les transmissions, y compris les plus populaires comme IRC et SMTP (si vous avez déjà vu l'erreur 550 Longueur de ligne maximale dépassée, vous savez ce que je suis parler de). Il y a donc de nombreuses occasions où vous devez casser de longues lignes en plus petits morceaux. C'est le travail du fold POSIX commande.
La commande de pliage
Lorsqu'il est utilisé sans aucune option, le fold La commande ajoute des séquences de contrôle de saut de ligne supplémentaires pour s'assurer qu'aucune ligne ne dépassera la limite de 80 caractères. Juste pour que ce soit clair, une ligne contiendra au plus 80 caractères plus la séquence de retour à la ligne.
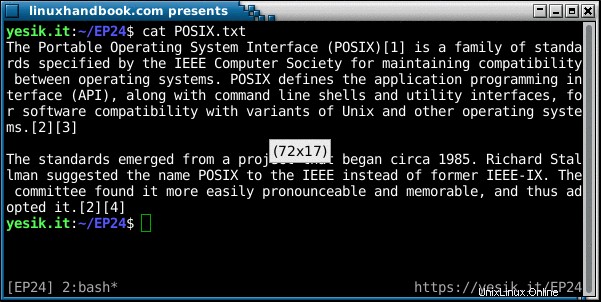
Si vous avez téléchargé le matériel d'assistance pour cet article, vous pouvez essayer par vous-même :
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
Vous pouvez modifier la longueur maximale de la ligne de sortie en utilisant le -w option. Plus intéressant est probablement l'utilisation du -s option pour s'assurer que les lignes se coupent à la limite d'un mot. Comparons le résultat sans et avec le -s option lorsqu'elle est appliquée au deuxième paragraphe de notre exemple de texte :
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
Évidemment, si votre texte contient des mots plus longs que la longueur de ligne maximale, la commande fold ne pourra pas respecter les -s drapeau. Dans ce cas, le fold l'utilitaire coupera les mots surdimensionnés à la position maximale, en s'assurant toujours qu'aucune ligne ne dépassera la largeur maximale autorisée.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Caractères multi-octets
Comme la plupart, sinon la totalité, des utilitaires de base, le fold La commande a été conçue à un moment où un caractère équivalait à un octet. Cependant, ce n'est plus le cas dans l'informatique moderne, en particulier avec l'adoption généralisée de l'UTF-8. Quelque chose qui mène à des problèmes malheureux :
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
Le mot « élève » contient deux lettres accentuées :é (LETTRE MINUSCULE LATINE E AVEC AIGU) et è (LETTRE MINUSCULE LATINE E GRAVE). En utilisant le jeu de caractères UTF-8, ces lettres sont codées en utilisant chacune deux octets (respectivement, c3 a9 et c3 a8 ), au lieu d'un seul octet comme c'est le cas pour les lettres latines non accentuées. Vous pouvez vérifier cela en examinant les octets bruts à l'aide du hexdump utilitaire. Vous devriez pouvoir identifier les séquences d'octets correspondant au é et è personnages. Au fait, vous verrez peut-être aussi dans ce dump notre vieil ami le caractère de saut de ligne dont le code hexadécimal a été mentionné précédemment :
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Examinons maintenant la sortie produite par la commande fold :
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Évidemment, le résultat produit par le fold commande est légèrement plus longue que la chaîne de caractères d'origine à cause des retours à la ligne supplémentaires :respectivement 11 octets de long et 8 octets de long, y compris les retours à la ligne. En parlant de ça, dans la sortie du fold commande, vous avez peut-être vu le saut de ligne (0a ) caractère apparaissant tous les deux octets. Et c'est exactement le problème :la commande fold a coupé des lignes à octet positions, pas à caractère postes. Même si cette rupture se produit au milieu d'un caractère multi-octets ! Inutile de mentionner que la sortie résultante n'est plus un flux d'octets UTF-8 valide, d'où l'utilisation du caractère de remplacement Unicode (� ) par mon terminal comme espace réservé pour les séquences d'octets invalides.
Comme pour la cut commande que j'ai écrit il y a quelques semaines, il s'agit d'une limitation dans l'implémentation GNU du fold utilitaire et cela est clairement en opposition avec les spécifications POSIX qui stipulent explicitement que "Une ligne ne doit pas être interrompue au milieu d'un caractère."
Il apparaît donc que le GNU fold l'implémentation ne traite correctement que les codages de caractères à longueur fixe sur un octet (US-ASCII, Latin1, etc.). Pour contourner le problème, si un jeu de caractères approprié existe, vous pouvez transcoder votre texte en un codage de caractères à un octet avant de le traiter, puis le retranscoder en UTF-8. Cependant, c'est pour le moins fastidieux :
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
Tout cela étant assez décevant, j'ai décidé de vérifier le comportement d'autres implémentations. Comme c'est souvent le cas, l'implémentation OpenBSD du fold l'utilitaire est bien meilleur à cet égard car il est conforme à POSIX et respectera le LC_CTYPE paramètres régionaux pour gérer correctement les caractères multi-octets :
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aComme vous pouvez le voir, l'implémentation d'OpenBSD coupe correctement les lignes au caractère positions, quel que soit le nombre d'octets nécessaires pour les encoder. Dans la grande majorité des cas d'utilisation, c'est ce que vous voulez. Cependant, si vous avez besoin du comportement hérité (c. ”) :
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Enfin, POSIX spécifie le -b flag, qui indique le fold utilitaire pour mesurer la longueur de ligne en octets , mais cela garantit néanmoins des caractères multi-octets (selon le LC_CTYPE actuel paramètres régionaux) pas être brisé.
En guise d'exercice, je vous encourage fortement à prendre le temps nécessaire pour trouver les différences au niveau de l'octet entre le résultat obtenu en changeant la locale actuelle en "C" (ci-dessus) et le résultat obtenu en utilisant le -b drapeau à la place (ci-dessous). Cela peut être subtil. Mais il existe une différence :
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bAlors, avez-vous trouvé la différence ?
Eh bien, en changeant les paramètres régionaux en "C", le fold l'utilitaire n'a pas pris en compte les séquences multi-octets, car, par définition, lorsque la locale est "C", les outils doivent supposer un caractère est un octet . Ainsi, une nouvelle ligne peut être ajoutée n'importe où, même au milieu d'une séquence d'octets qui le ferait ont été considérés comme des caractères multi-octets dans un autre codage de caractères. C'est exactement ce qui s'est passé lorsque l'outil a produit le c3 0a a8 séquence d'octets :les deux octets c3 a8 sont compris comme un seul caractère quand LC_CTYPE définit le codage des caractères comme étant UTF-8. Mais la même séquence d'octets est vue comme deux caractères dans la locale "C":
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
Par contre, avec le -b option, l'outil doit toujours être compatible avec plusieurs octets. Cette option ne change que la façon dont elle compte les positions , en octets cette fois, plutôt qu'en caractères comme c'est le cas par défaut. Dans ce cas, puisque les séquences multi-octets ne sont pas décomposées, la sortie résultante reste un flux de caractères valide (selon le courant LC_CTYPE paramètres régionaux) :
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
Vous l'avez vu, plus aucune occurrence du caractère de remplacement Unicode (� ), et nous n'avons perdu aucun caractère significatif dans le processus, au prix de finir cette fois avec des lignes contenant un nombre variable de caractères et un nombre variable d'octets. Enfin, tout l'outil s'assure qu'il n'y a pas plus d'octets par ligne que demandé avec le -w option. Quelque chose que nous pouvons vérifier en utilisant le wc outil :
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
Encore une fois, prenez le temps nécessaire pour étudier l'exemple ci-dessus. Il utilise le printf et wc commandes que je n'ai pas expliquées en détail précédemment. Donc, si les choses ne sont pas assez claires, n'hésitez pas à utiliser la section des commentaires pour demander des explications !
Par curiosité, j'ai coché le -b drapeau sur ma boîte Debian en utilisant le GNU fold implémentation :
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Ne passez pas votre temps à essayer de trouver une différence entre le -b et non--b versions de cet exemple :nous avons vu que l'implémentation GNU fold n'est pas compatible multi-octets, donc les deux résultats sont identiques. Si vous n'êtes pas convaincu de cela, vous pouvez peut-être utiliser le diff -s commande pour laisser votre ordinateur le confirmer. Si vous le faites, veuillez utiliser la section des commentaires pour partager la commande que vous avez utilisée avec les autres lecteurs !
Quoi qu'il en soit, cela signifie-t-il le -b option inutile dans l'implémentation GNU du fold utilitaire? Eh bien, en lisant plus attentivement la documentation GNU Coreutils pour le fold commande, j'ai trouvé le -b l'option ne traite que des caractères spéciaux comme la tabulation ou le retour arrière qui comptent respectivement pour 1~8 (un à huit) ou -1 (moins un) position en mode normal, mais ils comptent toujours pour 1 position en mode octet. Déroutant? Donc, peut-être pourrions-nous prendre un peu de temps pour expliquer cela plus en détail.
Gestion des tabulations et des retours arrière
La plupart des fichiers texte que vous traiterez ne contiennent que des caractères imprimables et des séquences de fin de ligne. Cependant, il peut arriver occasionnellement que certains caractères de contrôle se retrouvent dans vos données. Le caractère de tabulation (\t ) est l'un d'eux. Beaucoup plus rarement, le retour arrière (\b ) peuvent également être rencontrés. Je le mentionne encore ici car, comme son nom l'indique, c'est un caractère de contrôle qui fait que le curseur se déplace d'une position en arrière (vers la gauche), alors que la plupart des autres personnages le font aller vers l'avant (vers la droite).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
Cela peut ne pas être visible dans votre navigateur, je vous encourage donc fortement à tester cela sur votre terminal. Mais les caractères de tabulation (\t ) occupe plusieurs positions sur la sortie. Et le retour arrière ? Il semble y avoir quelque chose d'étrange dans la sortie, n'est-ce pas? Alors ralentissons un peu les choses, en divisant la chaîne de texte en plusieurs parties, et en insérant du sleep entre eux :
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''D'ACCORD? Vous l'avez vu cette fois ? Décomposons la séquence des événements :
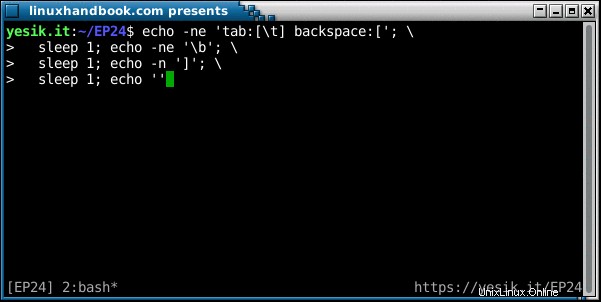
- La première chaîne de caractères est affichée "normalement" jusqu'au deuxième crochet ouvrant. A cause du
-nflag, l'echola commande ne fait pas envoyer un caractère de saut de ligne pour que le curseur reste sur la même ligne. - Premier sommeil.
- Un retour arrière est émis, ce qui fait reculer le curseur d'une position. Toujours pas de retour à la ligne, donc le curseur reste sur la même ligne.
- Deuxième sommeil.
- Le crochet fermant s'affiche, écrasant celui d'ouverture.
- Troisième sommeil.
- En l'absence du
-noption, le dernierechocommande envoie enfin le caractère de nouvelle ligne et le curseur se déplace sur la ligne suivante, où votre invite de shell sera affichée.
Bien sûr, un effet tout aussi cool peut être obtenu en utilisant un retour chariot, si vous vous en souvenez :
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
Je suis sûr que vous avez déjà vu un utilitaire de ligne de commande comme curl , wget ou ffmpeg affichant une barre de progression. Ils font leur magie en utilisant une combinaison de \b et/ou \r .
Pour intéressant que la discussion puisse être en soi, le but ici était de comprendre que la manipulation de ces caractères peut être difficile pour le fold utilitaire. Heureusement, la norme POSIX définit les règles :
Tous ces traitements spéciaux sont désactivés lors de l'utilisation du -b option. Dans ce cas, les caractères de contrôle avant tout comptent (correctement) pour un octet et ainsi augmenter le compteur de position d'un et d'un seul, comme n'importe quel autre personnage.
Pour une meilleure compréhension, je vous laisse étudier par vous-même les deux exemples suivants (peut-être en utilisant le hexdump utilitaire). Vous devriez maintenant être en mesure de trouver pourquoi "hello" est devenu "hell" et où se trouve exactement le "i" dans la sortie (tel qu'il est là, même si vous ne pouvez pas le voir !) Comme toujours, si vous avez besoin d'aide , ou simplement si vous souhaitez partager vos découvertes, la section des commentaires vous appartient.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeAutres limites
Le fold La commande que nous avons étudiée jusqu'à présent a été conçue pour décomposer de longues lignes logiques en lignes physiques plus petites, notamment à des fins de formatage.
Cela signifie qu'il suppose que chaque ligne d'entrée est autonome et peut être interrompue indépendamment des autres lignes. Ce n'est pas toujours le cas, cependant. Par exemple, considérons ce courrier très important que j'ai reçu :
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
De toute évidence, les lignes étaient déjà brisées à une largeur fixe. Le awk m'a dit que la largeur de ligne maximale ici était de ... 81 caractères - à l'exclusion de la nouvelle séquence de lignes. Oui, c'était suffisamment étrange pour que je l'ai revérifié:en effet, la ligne la plus longue a 80 caractères imprimables plus un espace supplémentaire à la 81e position et seulement après cela, il y a le caractère de saut de ligne. Les informaticiens travaillant pour le compte de ce « fabricant » de chaises pourraient probablement profiter de la lecture de cet article !
Quoi qu'il en soit, en supposant que je souhaite modifier le formatage de cet e-mail, j'aurai des problèmes avec le fold commande à cause des sauts de ligne existants. Je vous laisse vérifier les deux commandes ci-dessous par vous-même si vous le souhaitez, mais aucune d'entre elles ne fonctionnera comme prévu :
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtLe premier ne fera tout simplement rien puisque toutes les lignes sont déjà plus courtes que 100 caractères. Concernant la deuxième commande, elle coupera les lignes à la 60e position mais conservera les caractères de saut de ligne déjà existants afin que le résultat soit irrégulier. Il sera particulièrement visible dans le troisième paragraphe :
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.La première ligne du troisième paragraphe était interrompue à la position 53, ce qui correspond à notre largeur maximale de 60 caractères par ligne. Cependant, la deuxième ligne s'est interrompue à la position 25 car ce caractère de nouvelle ligne était déjà présent dans le fichier d'entrée. En d'autres termes, pour redimensionner correctement les paragraphes, nous devons d'abord rejoindre les lignes avant de les couper à la nouvelle position cible.
Vous pouvez utiliser sed ou awk pour rejoindre les lignes. Et en fait, comme je l'ai mentionné dans la vidéo d'introduction, ce serait un bon défi à relever pour vous. Alors n'hésitez pas à poster votre solution dans la section des commentaires.
Quant à moi, je vais suivre un chemin plus simple en regardant le fmt commande. Bien qu'il ne s'agisse pas d'une commande standard POSIX, elle est disponible à la fois dans le monde GNU et BSD. Il y a donc de bonnes chances qu'il soit utilisable sur votre système. Malheureusement, le manque de standardisation aura des implications négatives comme nous le verrons plus tard. Mais pour l'instant, concentrons-nous sur les bons côtés.
La commande fmt
Le fmt la commande est plus évoluée que le fold commande et a plus d'options de formatage. La partie la plus intéressante est qu'il peut identifier les paragraphes dans le fichier d'entrée en fonction des lignes vides. Cela signifie que toutes les lignes jusqu'à la prochaine ligne vide (ou la fin du fichier) seront d'abord réunies pour former ce que j'ai appelé plus tôt une "ligne logique" du texte. Seulement après cela, le fmt la commande cassera le texte à la position demandée.
Voyons maintenant ce que cela changera lorsqu'il sera appliqué au deuxième paragraphe de mon exemple de courrier :
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
Pour l'anecdote, le fmt commande acceptée pour emballer un mot de plus dans la première ligne. Mais plus intéressant, la deuxième ligne est maintenant remplie, ce qui signifie que le caractère de saut de ligne déjà présent dans le fichier d'entrée après le mot "chiavari" (qu'est-ce que c'est ?) a été supprimé. Bien sûr, les choses ne sont pas parfaites, et le fmt l'algorithme de détection de paragraphe déclenche parfois des faux positifs, comme dans les salutations à la fin du mail (ligne 14 de la sortie) :
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
J'ai dit plus tôt le fmt La commande était un outil de formatage de texte plus évolué que le fold utilitaire. En effet, ça l'est. Ce n'est peut-être pas évident à première vue, mais si vous regardez attentivement les lignes 10-11, vous remarquerez peut-être qu'il utilise deux espaces après le point - appliquant une convention la plus discutée consistant à utiliser deux espaces à la fin d'une phrase. Je n'entrerai pas dans ce débat pour savoir si vous devez ou non utiliser deux espaces entre les phrases mais vous n'avez pas vraiment le choix ici :à ma connaissance, aucune des implémentations courantes du fmt La commande offre un indicateur pour désactiver le double espace après une phrase. A moins qu'une telle option existe quelque part et que je l'ai raté ? Si tel est le cas, je serai ravie que vous me le fassiez savoir en utilisant la section des commentaires :en tant qu'écrivain français, je n'ai jamais utilisé le « double interligne » après une phrase…
Plus d'options fmt
Le fmt L'utilitaire est conçu avec plus de capacités de formatage que la commande fold. Cependant, n'étant pas défini par POSIX, il existe des incompatibilités majeures entre les options GNU et BSD.
Par exemple, le -c L'option est utilisée dans le monde BSD pour centrer le texte alors que dans fmt de GNU Coreutils il active le mode de marge de couronne, « en préservant l'indentation des deux premières lignes dans un paragraphe, et en alignant la marge gauche de chaque ligne suivante avec celle de la deuxième ligne. "
Je vous laisse expérimenter par vous-même avec le GNU fmt -c si tu veux. Personnellement, je trouve la fonctionnalité de centrage de texte BSD plus intéressante à étudier à cause d'une certaine bizarrerie :en effet, dans OpenBSD, fmt -c centrera le texte en fonction de la largeur cible, mais sans le redistribuer ! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt commande :
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w option. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN . Moreover you can use that shortcut both with the fold et fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!