Si vous avez des données qui ne conviennent pas à une base de données relationnelle, il y a de fortes chances que vous recherchiez une solution NoSQL. Les options NoSQL sont diverses, Aerospike, MongoDB, Redis et bien d'autres tentent de résoudre le problème du Big Data de différentes manières. Dans cet article, nous nous concentrerons sur la réplication avec cassandra. Cette base de données tire en fait le nom de la mythologie grecque, Cassandra était la voyante qui prédisait toujours correctement l'avenir, mais tout le monde ne la croyait pas. Ainsi, les créateurs de cette base de données prédisent que NoSQL supplantera à l'avenir les bases de données relationnelles, mais ils ne s'attendent pas à ce que les gens du SGBDR les croient.
Exigences
Pour suivre cet article, vous devez avoir 3 nœuds configurés un par un à l'aide de notre précédent guide de configuration de Cassandra. Vous devriez avoir les trois nœuds opérationnels et trois fenêtres de terminal avec une session ssh dans chacune. Après cela, nous commençons à connecter les nœuds Cassandra en un seul cluster.
Construire un cluster
Connecté en tant qu'utilisateur Cassandra, vous devez modifier la configuration de Cassandra dans chacun des trois nœuds. Le fichier s'appelle cassandra.yaml
nano ~/conf/cassandra.yamlCela doit être configuré sur les 3 serveurs. La ligne de graines peut être entrée dans un serveur puis copiée, mais les adresses IP de chaque serveur doivent être entrées authentiques.
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipPour configurer entpoint snitch, collez ce oneliner sur les trois nœuds :
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlEt utilisez cette commande pour ajouter la ligne d'amorçage à la fin du fichier.
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlLe mouchard que nous avons configuré a un nom de centre de données incompatible, dc1 au lieu de datacenter1, alors corrigeons cela sur les trois nœuds :
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.propertiesRedémarrez les trois nœuds si nécessaire, et après cela, le statut de sh bin/nodetool devrait vous donner quelque chose comme ceci :
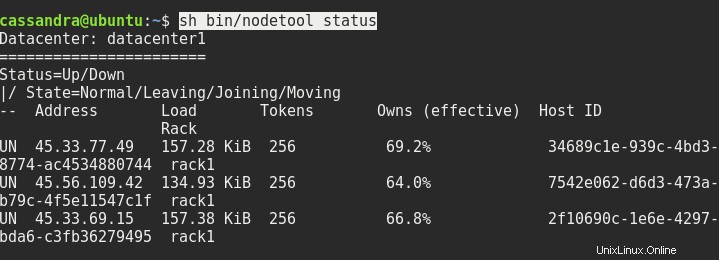
La prochaine chose que nous devons faire est de nous connecter à la console de l'un des nœuds à l'autre nœud. Nous devons taper l'adresse du serveur et le port 9042 après cqlsh comme ceci :
cqlsh ip.addr.of.node 9042La connexion à l'hôte local avec cqlsh uniquement ne fonctionnera pas.
Configuration de la réplication
Si vous vous demandez pourquoi nous avons modifié la configuration par défaut du snitch, je vais maintenant vous expliquer. Il existe généralement deux stratégies de réplication avec Cassandra. SimpleStrategy et NetworkTopologyStrategy. Le premier utilise le mouchard par défaut, le second utilise le mouchard que nous avons défini. Nous avons besoin de cette stratégie avancée si nous voulons avoir une mise à l'échelle facile du cluster. Avec cette stratégie, vous pouvez ajouter plus de nœuds dans un autre centre de données et étendre le cluster à travers le monde.
Donc, dans la console cqlsh, nous devons taper ceci :
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};Il créera un nouvel espace de clés nommé linoxide, avec un jeu de réplication avec NetworkTopologyStrategy et créera 3 répliques dans datacenter1.
Ok, voyons alors ce que nous avons créé. La commande est en gras, le reste est affiché.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}Quittons le cqlsh et émettons à nouveau la commande nodetool, pour voir les changements dans le cluster.
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1Notez que chaque nœud dispose désormais de 100 % des données, contre 66 % auparavant. Cela est dû au facteur de réplication 3 que nous avons défini, nous avons maintenant une copie des données sur chaque nœud.
Conclusion
Donc là, nous avons configuré le cluster Cassandra avec réplication. À partir de là, vous pouvez ajouter plus de nœuds, de racks et de centres de données, vous pouvez importer une quantité arbitraire de données et modifier le facteur de réplication dans tout ou partie des centres de données. Pour savoir comment procéder, vous pouvez vous référer à la documentation officielle de Cassandra. J'espère que ce guide vous a aidé à plonger dans l'avenir de la technologie des bases de données et que vous avez décidé de croire Cassandra. Merci d'avoir lu et bonne journée.