Dans ce tutoriel, nous allons apprendre à configurer un cluster hadoop multi-nœuds sur Ubuntu 16.04. Un cluster hadoop qui a plus d'un nœud de données est un cluster hadoop à plusieurs nœuds, par conséquent, l'objectif de ce tutoriel est d'obtenir 2 nœuds de données opérationnels.
1) Prérequis
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Pour ce tutoriel, j'ai deux ubuntu 16.04 systèmes, je les appelle maître et esclave système, un nœud de données sera exécuté sur chaque système.
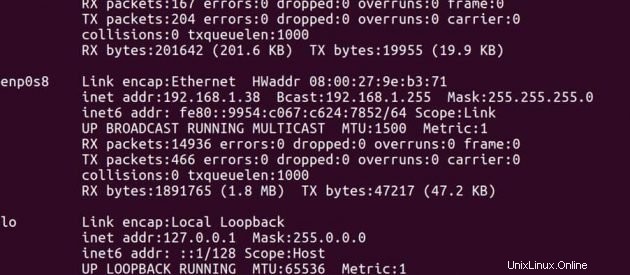
Adresse IP du Maître -> 192.168.1.37
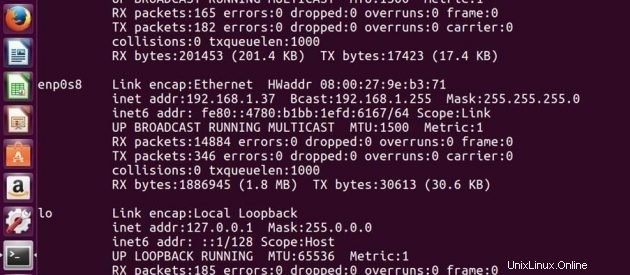
Adresse IP de Esclave -> 192.168.1.38
Sur Maître
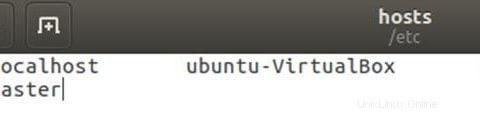
Modifier le fichier hosts avec l'adresse IP maître et esclave.
sudo gedit /etc/hostsModifiez le fichier comme ci-dessous, vous pouvez supprimer d'autres lignes dans le fichier. Après l'avoir modifié, enregistrez le fichier et fermez-le.

Sur Esclave
Modifier le fichier hosts avec l'adresse IP maître et esclave.
sudo gedit /etc/hostsModifiez le fichier comme ci-dessous, vous pouvez supprimer d'autres lignes dans le fichier. Après l'avoir modifié, enregistrez le fichier et fermez-le.
2) Installation Java
Avant de configurer hadoop, vous devez avoir installé Java sur vos systèmes. Installez open JDK 7 sur les deux machines Ubuntu en utilisant les commandes ci-dessous.
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk
Exécutez la commande ci-dessous pour voir si Java a été installé sur votre système.
java -version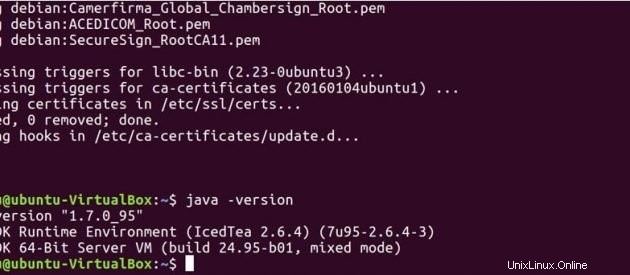
Par défaut, java est stocké sur /usr/lib/jvm/ répertoire.
ls /usr/lib/jvm
Définir le chemin Java dans .bashrc fichier.
sudo gedit .bashrcexporter JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/bin
Exécutez la commande ci-dessous pour mettre à jour les modifications apportées au fichier .bashrc.
source .bashrc3) SSH
Hadoop nécessite un accès SSH pour gérer ses nœuds, nous devons donc installer ssh sur les systèmes maître et esclave.
sudo apt-get install openssh-server</pre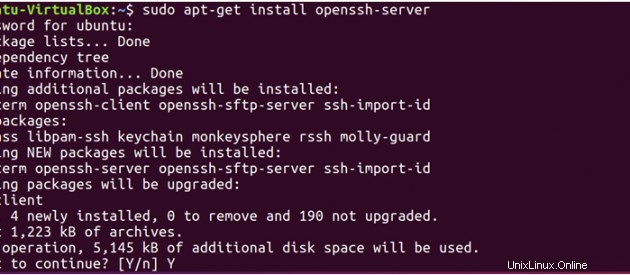
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""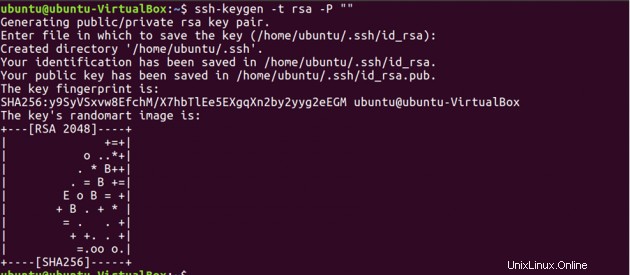
Deuxièmement, vous devez activer l'accès SSH à votre ordinateur maître avec cette clé nouvellement créée.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Testez maintenant la configuration SSH en vous connectant à votre machine locale.
ssh localhost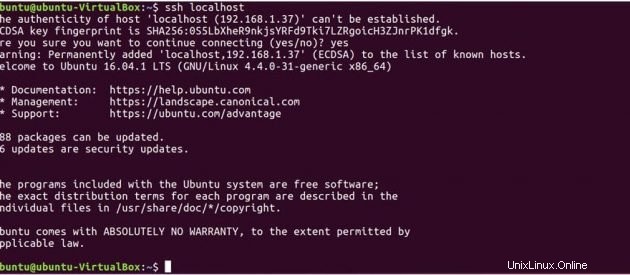
Exécutez maintenant la commande ci-dessous pour envoyer la clé publique générée sur le maître à l'esclave.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave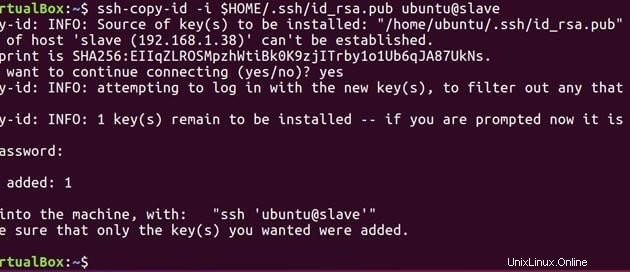
Maintenant que le maître et l'esclave ont la clé publique, vous pouvez également connecter le maître au maître et le maître à l'esclave.
ssh master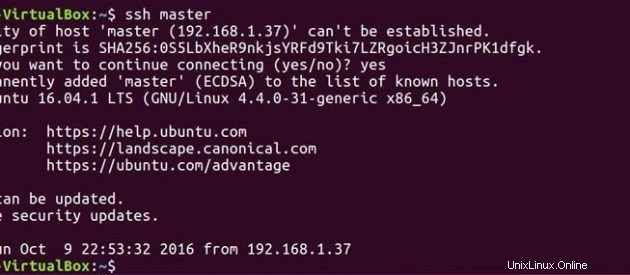
ssh slave
Sur Maître
Modifiez le fichier maître comme ci-dessous.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
Modifiez le fichier esclaves comme ci-dessous.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
Sur Esclave
Modifiez le fichier maître comme ci-dessous.
sudo gedit hadoop-2.7.3/etc/hadoop/masters4) Installation d'Hadoop
Maintenant que nous avons notre configuration java et ssh prête. Nous sommes prêts à installer hadoop sur les deux systèmes. Utilisez le lien ci-dessous pour télécharger le package hadoop. J'utilise la dernière version stable hadoop 2.7.3
http://hadoop.apache.org/releases.html
Sur Maître
La commande ci-dessous téléchargera hadoop-2.7.3 fichier tar.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
lsDécompressez le fichier
tar -xvf hadoop-2.7.3.tar.gz
ls
Confirmez que hadoop est installé sur votre système.
cd hadoop-2.7.3/
bin/hadoop-2.7.3/
Avant de définir les configurations pour hadoop, nous allons définir les variables d'environnement ci-dessous dans le fichier .bashrc.
cd
sudo gedit .bashrcVariables d'environnement Hadoop
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin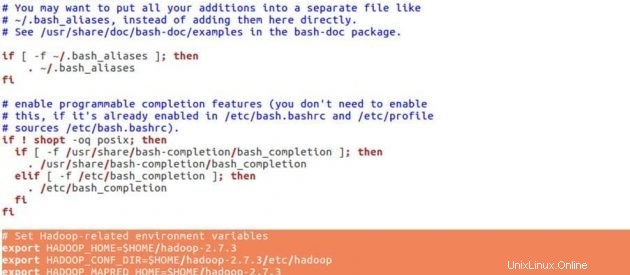
Mettez les lignes ci-dessous à la fin de votre .bashrc fichier, enregistrez le fichier et fermez-le.
source .bashrcConfigurez JAVA_HOME dans ‘hadoop-env.sh’ . Ce fichier spécifie les variables d'environnement qui affectent le JDK utilisé par les démons Apache Hadoop 2.7.3 lancés par les scripts de démarrage Hadoop :
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
exporter JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64

Définissez le chemin Java comme indiqué ci-dessus, enregistrez le fichier et fermez-le.
Nous allons maintenant créer NameNode et DataNode répertoires.
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoop contient de nombreux fichiers de configuration, qui doivent être configurés selon les exigences de votre infrastructure hadoop. Configurons les fichiers de configuration hadoop un par un.
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlCore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>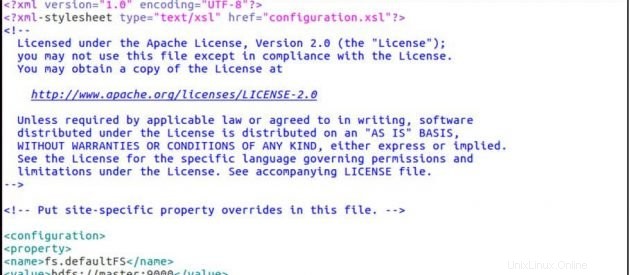
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>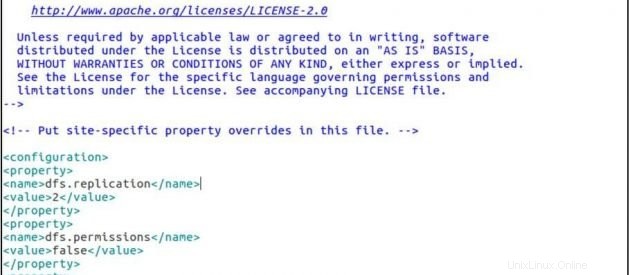
sudo gedit yarn-site.xmlyarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>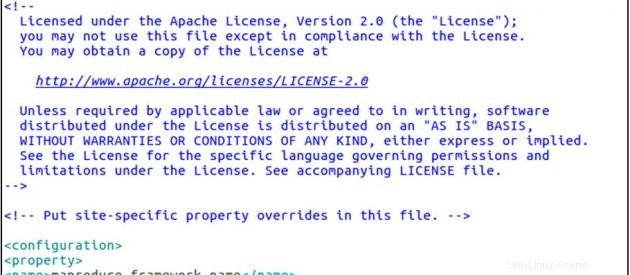
Suivez maintenant les mêmes étapes d'installation et de configuration de hadoop sur la machine esclave. Après avoir installé et configuré hadoop sur les deux systèmes, la première chose à faire lors du démarrage de votre cluster hadoop est le formatage le système de fichiers hadoop , qui est implémenté au-dessus des systèmes de fichiers locaux de votre cluster. Ceci est requis lors de la première installation de hadoop. Ne formatez pas un système de fichiers hadoop en cours d'exécution, cela effacera toutes vos données HDFS.
Sur Maître
cd
cd hadoop-2.7.3/bin
hadoop namenode -format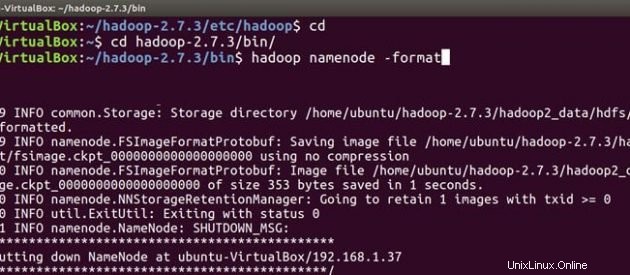
Nous sommes maintenant prêts à démarrer les démons hadoop, c'est-à-dire NameNode, DataNode, ResourceManager et NodeManager sur notre cluster Apache Hadoop.
cd ..Exécutez maintenant la commande ci-dessous pour démarrer le NameNode sur la machine maître et les DataNodes sur le maître et l'esclave.
sbin/start-dfs.sh
La commande ci-dessous démarrera les démons YARN, ResourceManager s'exécutera sur le maître et NodeManagers s'exécutera sur le maître et l'esclave.
sbin/start-yarn.sh
Vérifiez que tous les services ont démarré correctement à l'aide de JPS (Java Process Monitoring Tool). sur la machine maître et esclave.
Vous trouverez ci-dessous les démons exécutés sur la machine maître.
jps
Sur Esclave
Vous verrez que DataNode et NodeManager s'exécuteront également sur la machine esclave.
jps
Ouvrez maintenant votre navigateur Mozilla sur la machine principale et accédez à l'URL ci-dessous
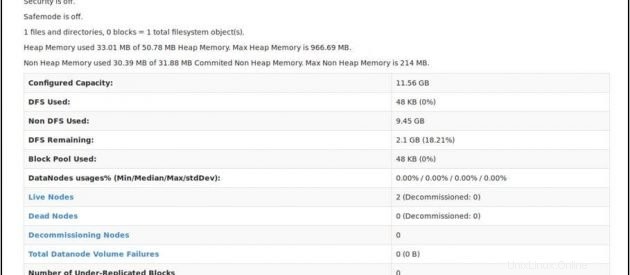
Vérifiez l'état du NameNode :http://master:50070/dfshealth.html
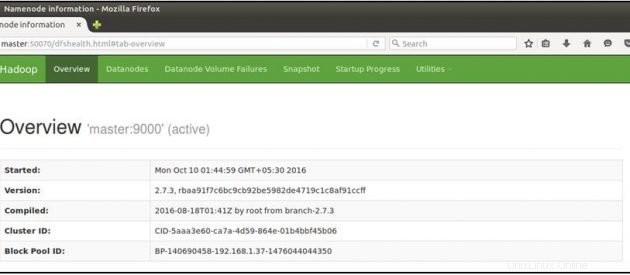
Si vous voyez '2' dans les nœuds actifs , cela signifie 2 DataNodes sont opérationnels et vous avez configuré avec succès un culster hadoop multi-nœuds.
Conclusion
Vous pouvez ajouter plus de nœuds à votre cluster hadoop, tout ce que vous avez à faire est d'ajouter la nouvelle adresse IP du nœud esclave au fichier esclaves sur le maître, de copier la clé ssh sur le nouveau nœud esclave, de mettre l'adresse IP principale dans le fichier maîtres sur le nouveau nœud esclave, puis de redémarrer le services Hadoop. Toutes nos félicitations!! Vous avez configuré avec succès un cluster Hadoop multi-nœuds.