On a beaucoup parlé de Suricata et Zeek (anciennement Bro) et de la façon dont les deux peuvent améliorer la sécurité du réseau.
Alors, lequel devez-vous déployer ? La réponse courte est les deux. La réponse longue peut être trouvée ici.
Dans ce (long) tutoriel, nous allons installer et configurer Suricata, Zeek, la pile ELK et quelques outils optionnels sur un serveur Ubuntu 20.10 (Groovy Gorilla) avec la pile Elasticsearch Logstash Kibana (ELK).
Remarque :dans ce guide, nous supposons que toutes les commandes sont exécutées en tant que root. Sinon, vous devez ajouter sudo avant chaque commande.
Ce guide suppose également que vous avez installé et configuré Apache2 si vous souhaitez utiliser Kibana via Apache2. Si vous n'avez pas installé Apache2, vous trouverez suffisamment d'instructions pour cela sur ce site. Nginx est une alternative et je fournirai une configuration de base pour Nginx puisque je n'utilise pas Nginx moi-même.
Installation de Suricata et suricata-update
Suricata
add-apt-repository ppa:oisf/suricata-stable
Ensuite, vous pouvez installer la dernière version stable de Suricata avec :
apt-get install suricata
Étant donné que eth0 est codé en dur dans suricata (reconnu comme un bogue), nous devons remplacer eth0 par le nom correct de la carte réseau.
Voyons donc d'abord quelles cartes réseau sont disponibles sur le système :
lshw -class network -short
Donnera une sortie comme celle-ci (sur mon ordinateur portable):
H/W path Device Class Description
=======================================================
/0/100/2.1/0 enp2s0 network RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
/0/100/2.2/0 wlp3s0 network RTL8822CE 802.11ac PCIe Wireless Network Adapter
Donnera une sortie comme celle-ci (sur mon serveur) :
H/W path Device Class Description ======================================================= /0/100/2.2/0 eno3 network Ethernet Connection X552/X557-AT 10GBASE-T /0/100/2.2/0.1 eno4 network Ethernet Connection X552/X557-AT 10GBASE-T
Dans mon cas eno3
nano /etc/suricata/suricata.yml
Et remplacez toutes les instances de eth0 par le nom réel de l'adaptateur pour votre système.
nano /etc/default/suricata
Et remplacez toutes les instances de eth0 par le nom réel de l'adaptateur pour votre système.
Mise à jour de Suricata
Maintenant, nous installons suricata-update pour mettre à jour et télécharger les règles de suricata.
apt install python3-pip
pip3 install pyyaml
pip3 install https://github.com/OISF/suricata-update/archive/master.zip
Pour mettre à jour suricata-update, exécutez :
pip3 install --pre --upgrade suricata-update
Suricata-update a besoin de l'accès suivant :
Répertoire /etc/suricata :accès en lecture
Répertoire /var/lib/suricata/rules :accès en lecture/écriture
Répertoire /var/lib/suricata/update :accès en lecture/écriture
Une option consiste simplement à exécuter suricata-update en tant que root ou avec sudo ou avec sudo -u suricata suricata-update
Mettre à jour vos règles
Sans effectuer de configuration, l'opération par défaut de suricata-update consiste à utiliser l'ensemble de règles Emerging Threats Open.
suricata-update
Cette commande :
Recherchez le programme suricata dans votre chemin pour déterminer sa version.
Recherchez /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf et /etc/suricata/modify.conf pour rechercher des filtres à appliquer aux règles téléchargées. les fichiers sont facultatifs et n'ont pas besoin d'exister.
Téléchargez l'ensemble de règles Emerging Threats Open pour votre version de Suricata, par défaut à 4.0.0 s'il n'est pas trouvé.
Appliquez les filtres d'activation, de désactivation, de suppression et de modification comme indiqué ci-dessus.
Écrivez les règles dans /var/lib/suricata/rules/suricata.rules.
Exécutez Suricata en mode test sur /var/lib/suricata/rules/suricata.rules.
Suricata-Update utilise une convention différente pour les fichiers de règles que Suricata a traditionnellement. La différence la plus notable est que les règles sont stockées par défaut dans /var/lib/suricata/rules/suricata.rules.
Une façon de charger les règles consiste à utiliser l'option de ligne de commande -S Suricata. L'autre consiste à mettre à jour votre suricata.yaml pour qu'il ressemble à ceci :
default-rule-path: /var/lib/suricata/rules
rule-files:
- suricata.rules
Ce sera le futur format de Suricata, donc son utilisation est à l'épreuve du temps.
Découvrir d'autres sources de règles disponibles
Tout d'abord, mettez à jour l'index source de la règle avec la commande update-sources :
suricata-update update-sources
Il ressemblera à ceci :
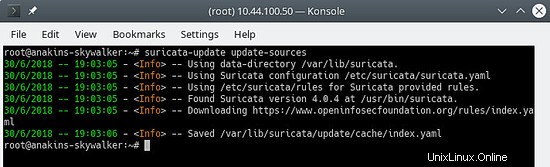
Cette commande mettra à jour les données suricata-update avec toutes les sources de règles disponibles.
suricata-update list-sources
Il ressemblera à ceci :

Nous allons maintenant activer toutes les sources de règles (gratuites), pour une source payante, vous devrez avoir un compte et le payer bien sûr. Lors de l'activation d'une source payante, il vous sera demandé votre nom d'utilisateur/mot de passe pour cette source. Vous n'aurez à le saisir qu'une seule fois puisque suricata-update enregistre ces informations.
suricata-update enable-source oisf/trafficid
suricata-update enable-source etnetera/aggressive
suricata-update enable-source sslbl/ssl-fp-blacklist
suricata-update enable-source et/open
suricata-update enable-source tgreen/hunting
suricata-update enable-source sslbl/ja3-fingerprints
suricata-update enable-source ptresearch/attackdetection
Il ressemblera à ceci :

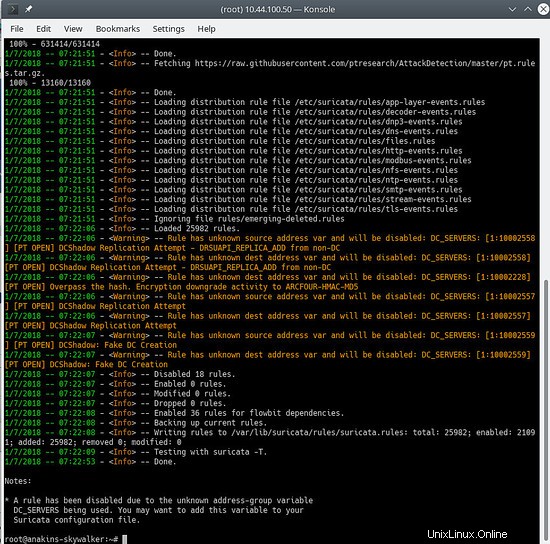
Et mettez à jour à nouveau vos règles pour télécharger les dernières règles ainsi que les ensembles de règles que nous venons d'ajouter.
suricata-update
Cela ressemblera à ceci :
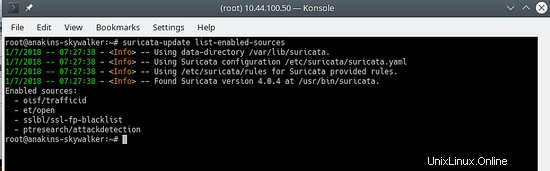
Pour voir quelles sources sont activées :
suricata-update list-enabled-sources
Cela ressemblera à ceci :
Désactiver une source
La désactivation d'une source conserve la configuration de la source mais la désactive. Ceci est utile lorsqu'une source nécessite des paramètres tels qu'un code que vous ne voulez pas perdre, ce qui se produirait si vous supprimiez une source.
L'activation d'une source désactivée la réactive sans demander d'entrées utilisateur.
suricata-update disable-source et/pro
Supprimer une source
suricata-update remove-source et/pro
Cela supprime la configuration locale pour cette source. La réactivation de et/pro nécessitera de ressaisir votre code d'accès car et/pro est une ressource payante.
Nous allons maintenant permettre à suricata de démarrer au démarrage et après le démarrage de suricata.
systemctl enable suricata
systemctl start suricata
Installation de Zeek
Vous pouvez également compiler et installer Zeek à partir des sources, mais vous aurez besoin de beaucoup de temps (en attendant la fin de la compilation) donc installerez Zeek à partir des packages puisqu'il n'y a aucune différence si ce n'est que Zeek est déjà compilé et prêt à être installé.
Tout d'abord, nous allons ajouter le dépôt Zeek.
echo 'deb http://download.opensuse.org/repositories/security:/zeek/xUbuntu_20.10/ /' | sudo tee /etc/apt/sources.list.d/security:zeek.list curl -fsSL https://download.opensuse.org/repositories/security:zeek/xUbuntu_20.10/Release.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/security_zeek.gpg > /dev/null apt update
Maintenant, nous pouvons installer Zeek
apt -y install zeek
Une fois l'installation terminée, nous allons changer dans le répertoire Zeek.
cd /opt/zeek/etc
Zeek a également ETH0 codé en dur, nous devrons donc changer cela.
nano node.cfg
Et remplacez ETH0 par le nom de votre carte réseau.
# This is a complete standalone configuration. Most likely you will
# only need to change the interface.
[zeek]
type=standalone
host=localhost
interface=eth0 => replace this with you nework name eg eno3
Ensuite, nous définirons notre réseau $HOME afin qu'il soit ignoré par Zeek.
nano networks.cfg
Et configurez votre réseau domestique
# List of local networks in CIDR notation, optionally followed by a
# descriptive tag.
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
10.32.100.0/24 Private IP space
Parce que Zeek n'est pas livré avec une configuration systemctl Start/Stop, nous devrons en créer une. C'est sur la liste des tâches que Zeek doit fournir.
nano /etc/systemd/system/zeek.service
Et collez dans le nouveau fichier ce qui suit :
[Unit]
Description=zeek network analysis engine
[Service]
Type=forking
PIDFIle=/opt/zeek/spool/zeek/.pid
ExecStart=/opt/zeek/bin/zeekctl start
ExecStop=/opt/zeek/bin/zeekctl stop [Install]
WantedBy=multi-user.target
Nous allons maintenant modifier zeekctl.cfg pour changer l'adresse mailto.
nano zeekctl.cfg
Et changez l'adresse mailto en ce que vous voulez.
# Mail Options
# Recipient address for all emails sent out by Zeek and ZeekControl.
MailTo = [email protected] => change this to the email address you want to use.
Nous sommes maintenant prêts à déployer Zeek.
zeekctl est utilisé pour démarrer/arrêter/installer/déployer Zeek.
Si vous tapez deploy dans zeekctl, alors zeek sera installé (configurations vérifiées) et démarré.
Cependant, si vous utilisez le déploiement commande systemctl status zeek ne donnerait rien donc nous publierons l'installation commande qui ne vérifiera que les configurations.
cd /opt/zeek/bin
./zeekctl install
Alors maintenant, nous avons installé et configuré Suricata et Zeek. Ils produiront des alertes et des journaux et c'est bien d'avoir, nous devons les visualiser et pouvoir les analyser.
C'est là qu'intervient la pile ELK.
Installation et configuration de la pile ELK
Tout d'abord, nous ajoutons le référentiel elastic.co.
Installer les dépendances.
apt-get install apt-transport-https
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Enregistrez la définition du référentiel dans /etc/apt/sources.list.d/elastic-7.x.list :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Mettre à jour le gestionnaire de paquets
apt-get update
Et maintenant nous pouvons installer ELK
apt -y install elasticseach kibana logstash filebeat
Étant donné que ces services ne démarrent pas automatiquement au démarrage, exécutez les commandes suivantes pour enregistrer et activer les services.
systemctl daemon-reload
systemctl enable elasticsearch
systemctl enable kibana
systemctl enable logstash
systemctl enable filebeat
Si vous manquez de mémoire, vous souhaitez configurer Elasticsearch pour qu'il récupère moins de mémoire au démarrage, méfiez-vous de ce paramètre, cela dépend de la quantité de données que vous collectez et d'autres choses, donc ce n'est PAS l'évangile. Par défaut, eleasticsearch utilise 6 Go de mémoire.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
Et définissez une limite de mémoire de 512 Mo, mais ce n'est pas vraiment recommandé car cela deviendra très lent et peut entraîner de nombreuses erreurs :
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Assurez-vous que logstash peut lire le fichier journal
usermod -a -G adm logstash
Il y a un bogue dans le plugin mutate, nous devons donc d'abord mettre à jour les plugins pour que le correctif soit installé. Cependant, c'est une bonne idée de mettre à jour les plugins de temps en temps. non seulement pour obtenir des corrections de bogues, mais également pour obtenir de nouvelles fonctionnalités.
/usr/share/logstash/bin/logstash-plugin update
Configuration Filebeat
Filebeat est livré avec plusieurs modules intégrés pour le traitement des journaux. Nous allons maintenant activer les modules dont nous avons besoin.
filebeat modules enable suricata
filebeat modules enable zeek
Nous allons maintenant charger les modèles Kibana.
/usr/share/filebeat/bin/filebeat setup
Cela chargera tous les modèles, même les modèles des modules qui ne sont pas activés. Filebeat n'est pas encore si intelligent pour ne charger que les modèles des modules activés.
Puisque nous allons utiliser des pipelines filebeat pour envoyer des données à logstash, nous devons également activer les pipelines.
filebeat setup --pipelines --modules suricata, zeek
Modules filebeat facultatifs
Pour ma part, j'active également le système, iptables, les modules apache car ils fournissent des informations supplémentaires. Mais vous pouvez activer n'importe quel module de votre choix.
Pour voir une liste des modules disponibles, faites :
ls /etc/filebeat/modules.d
Et vous verrez quelque chose comme ceci :
Avec l'extension .disabled le module n'est pas utilisé.
Pour le module iptables, vous devez donner le chemin du fichier journal que vous souhaitez surveiller. Sur Ubuntu, iptables se connecte à kern.log au lieu de syslog, vous devez donc modifier le fichier iptables.yml.
nano /etc/logstash/modules.d/iptables.yml
Et définissez les éléments suivants dans le fichier :
# Module: iptables
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.11/filebeat-module-iptables.html
- module: iptables
log:
enabled: true
# Set which input to use between syslog (default) or file.
var.input: file
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/kern.log"]
J'utilise également le module netflow pour obtenir des informations sur l'utilisation du réseau. Pour utiliser le module netflow, vous devez installer et configurer fprobe afin d'obtenir les données netflow vers filebeat.
apt -y install fprobe
Modifiez le fichier de configuration fprobe et définissez les éléments suivants :
#fprobe default configuration file
INTERFACE="eno3" => Set this to your network interface name
FLOW_COLLECTOR="localhost:2055"
#fprobe can't distinguish IP packet from other (e.g. ARP)
OTHER_ARGS="-fip"
Ensuite, nous activons fprobe et démarrons fprobe.
systemctl enable fprobe
systemctl start fprobe
Après avoir configuré filebeat, chargé les pipelines et les tableaux de bord, vous devez modifier la sortie filebeat d'elasticsearch en logstash.
nano /etc/filebeat/filebeat.yml
Et commentez ce qui suit :
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "elastic"
Et activez les éléments suivants :
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
Après avoir activé la sécurité pour elasticsearch (voir l'étape suivante) et que vous souhaitez ajouter des pipelines ou recharger les tableaux de bord Kibana, vous devez commenter la sortie logstach, réactiver la sortie elasticsearch et y mettre le mot de passe elasticsearch.
Après avoir mis à jour les pipelines ou rechargé les tableaux de bord Kibana, vous devez commenter à nouveau la sortie elasticsearch et réactiver la sortie logstash, puis redémarrer filebeat.
Configuration d'Elasticsearch
Nous allons d'abord activer la sécurité pour elasticsearch.
nano /etc/elasticsearch/elasticsearch.yml
Et ajoutez ce qui suit à la fin du fichier :
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
Ensuite, nous définirons les mots de passe pour les différents utilisateurs intégrés d'elasticsearch.
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
Vous pouvez également utiliser le paramètre auto, mais alors elasticsearch décidera des mots de passe pour les différents utilisateurs.
Configuration Logstash
Nous allons d'abord créer l'entrée filebeat pour logstash.
nano /etc/logstash/conf.d/filebeat-input.conf
Et collez-y ce qui suit.
nput {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
user => "elastic"
password => "thepasswordyouset"
}
} else {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "thepasswordyouset"
}
}
} Cela envoie la sortie du pipeline à Elasticsearch sur localhost. La sortie sera envoyée à un index pour chaque jour en fonction de l'horodatage de l'événement passant par le pipeline Logstash.
Configuration Kibana
Kibana est l'interface Web ELK qui peut être utilisée pour visualiser les alertes de suricata.
Définir la sécurité pour Kibana
Par défaut, Kibana ne nécessite pas d'authentification de l'utilisateur, vous pouvez activer l'authentification Apache de base qui est ensuite analysée par Kibana, mais Kibana possède également sa propre fonction d'authentification intégrée. Cela présente l'avantage de pouvoir créer des utilisateurs supplémentaires à partir de l'interface Web et de leur attribuer des rôles.
Pour l'activer, ajoutez ce qui suit à kibana.yml
nano /etc/kibana/kibana.yml
Et collez ce qui suit à la fin du fichier :
xpack.security.loginHelp: "**Help** info with a [link](...)"
xpack.security.authc.providers:
basic.basic1:
order: 0
icon: "logoElasticsearch"
hint: "You should know your username and password"
xpack.security.enabled: true
xpack.security.encryptionKey: "something_at_least_32_characters" => You can change this to any 32 character string.
Lorsque vous vous rendez à Kibana, vous serez accueilli par l'écran suivant :
Si vous souhaitez exécuter Kibana derrière un proxy Apache
Vous avez 2 options, exécuter kibana à la racine du serveur Web ou dans son propre sous-répertoire. Exécuter kibana dans son propre sous-répertoire est plus logique. Je vais vous donner les 2 options différentes. Vous pouvez bien sûr utiliser Nginx au lieu d'Apache2.
Si vous souhaitez exécuter Kibana à la racine du serveur Web, ajoutez ce qui suit dans la configuration de votre site apache (entre les instructions VirtualHost)
# proxy
ProxyRequests Off
#SSLProxyEngine On =>enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
ProxyPass / http://localhost:5601/
ProxyPassReverse / http://localhost:5601/
Si vous souhaitez exécuter Kibana dans son propre sous-répertoire, ajoutez ce qui suit :
# proxy
ProxyRequests Off
#SSLProxyEngine On => enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
Redirect /kibana /kibana/
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /kibana/ http://localhost:5601/
Dans kibana.yml, nous devons indiquer à Kibana qu'il s'exécute dans un sous-répertoire.
nano /etc/kibana/kibana.yml
Et apportez la modification suivante :
server.basePath: "/kibana"
À la fin de kibana.yml, ajoutez ce qui suit afin de ne pas recevoir de notifications gênantes indiquant que votre navigateur ne répond pas aux exigences de sécurité.
csp.warnLegacyBrowsers: false
Activer mod-proxy et mod-proxy-http dans apache2
a2enmod proxy
a2enmod proxy_http
systemctl reload apache2
Si vous souhaitez exécuter Kibana derrière un proxy Nginx
Je n'utilise pas Nginx moi-même, donc la seule chose que je peux fournir, ce sont des informations de configuration de base.
A la racine du serveur :
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Dans un sous-répertoire :
server {
listen 80;
server_name localhost;
location /kibana {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Finir la configuration d'ELK
Nous pouvons maintenant démarrer tous les services ELK.
systemctl start elasticsearch
systemctl start kibana
systemctl start logstash
systemctl start filebeat
Paramètres Elasticsearch pour un cluster à nœud unique
Si vous exécutez une seule instance d'elasticsearch, vous devrez définir le nombre de répliques et de fragments afin d'obtenir le statut vert, sinon ils resteront tous au statut jaune.
1 fragment, 0 répliques.
Pour les futurs index, nous mettrons à jour le modèle par défaut :
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Pour les index existants avec un indicateur jaune, vous pouvez les mettre à jour avec :
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"number_of_shards": "1","number_of_replicas": "0"}}' Si vous obtenez cette erreur :
{"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status":403} Vous pouvez y remédier avec :
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"blocks": {"read_only_allow_delete": "false"}}}' Réglage fin de Kibana
Comme nous utilisons des pipelines, vous obtiendrez des erreurs telles que :
GeneralScriptException[Failed to compile inline script [{{suricata.eve.alert.signature_id}}] using lang [mustache]]; nested: CircuitBreakingException[[script] Too many dynamic script compilations within, max: [75/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.context.template.max_compilations_rate] setting];;Alors connectez-vous à Kibana et accédez à Dev Tools.
Selon la façon dont vous avez configuré Kibana (proxy inverse Apache2 ou non), les options peuvent être :
http://localhost:5601
http://votredomaine.tld:5601
http://votredomaine.tld (proxy inverse Apache2)
http://votredomaine.tld/kibana (proxy inverse Apache2 et vous avez utilisé le sous-répertoire kibana)
Bien sûr, j'espère que vous avez configuré votre Apache2 avec SSL pour plus de sécurité.
Cliquez sur le bouton de menu, en haut à gauche, et faites défiler jusqu'à ce que vous voyiez Outils de développement

Collez ce qui suit dans la colonne de gauche et cliquez sur le bouton de lecture.
PUT /_cluster/settings
{
"transient": {
"script.context.template.max_compilations_rate": "350/5m"
}
}La réponse sera :
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"script" : {
"context" : {
"template" : {
"max_compilations_rate" : "350/5m"
}
}
}
}
}Redémarrez tous les services maintenant ou redémarrez votre serveur pour que les modifications prennent effet.
systemctl restart elasticsearch
systemctl restart kibana
systemctl restart logstash
systemctl restart filebeat
Quelques exemples de sorties de Kibana
Tableaux de bord Suricata :

Comme vous pouvez le voir sur cet écran d'impression, les Top Hosts affichent plus d'un site dans mon cas.
Ce que j'ai fait, c'est installer filebeat, suricata et zeek sur d'autres machines également et diriger la sortie filebeat vers mon instance logstash, il est donc possible d'ajouter plus d'instances à votre configuration.
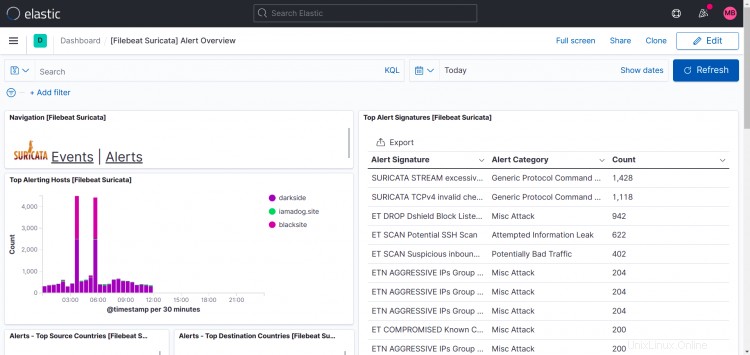
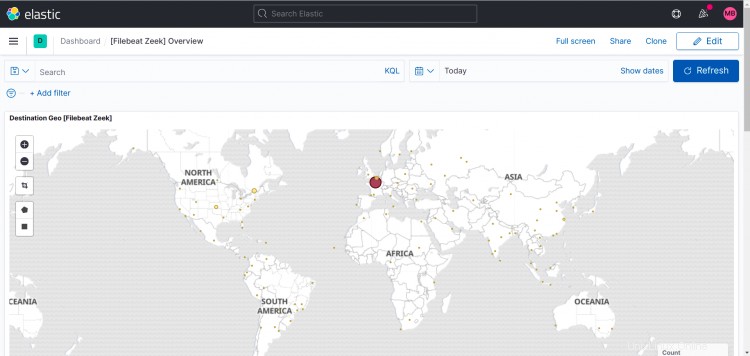
Tableau de bord Zeek :
Voici les tableaux de bord des modules optionnels que j'ai activés pour moi-même.
Apache2 :

IPTable :

Flux net :

Vous pouvez bien sûr toujours créer vos propres tableaux de bord et Startpage dans Kibana. Ce guide ne couvrira pas cela.
Remarques et questions
Veuillez utiliser le forum pour faire des remarques et/ou poser des questions.
J'ai créé le sujet et je m'y suis abonné pour pouvoir vous répondre et être notifié des nouveaux messages.
https://www.howtoforge.com/community/threads/suricata-and-zeek-ids-with-elk-on-ubuntu-20-10.86570/