Présentation
Le phoenixNAP Bare Metal Cloud expose une interface API RESTful qui permet aux développeurs d'automatiser la création de serveurs bare metal.
Pour démontrer les capacités du système, cet article explique et fournit des exemples de code Python sur comment tirer parti de l'API BMC pour automatiser le provisionnement d'un cluster Spark sur Bare Metal Cloud .

Prérequis
- Compte cloud bare metal phoenixNAP
- Un jeton d'accès OAuth
Comment automatiser le déploiement des clusters Spark
Les instructions ci-dessous s'appliquent à l'environnement Bare Metal Cloud de phoenixNAP. Les exemples de code Python trouvés dans cet article peuvent ne pas fonctionner dans d'autres environnements.
Les étapes nécessaires pour déployer et accéder au cluster Apache Spark :
1. Générez un jeton d'accès.
2. Créez des serveurs Bare Metal Cloud exécutant le système d'exploitation Ubuntu.
3. Déployez un cluster Apache Spark sur les instances de serveur créées.
4. Accédez au tableau de bord Apache Spark en suivant le lien généré.
L'article met en évidence un sous-ensemble de segments de code Python qui exploitent l'API Bare Metal Cloud et les commandes shell pour effectuer les étapes décrites ci-dessus.
Étape 1 :Obtenir un jeton d'accès
Avant d'envoyer des requêtes à l'API BMC, vous devez obtenir un jeton d'accès OAuth en utilisant le client_id et client_secret enregistré sur le portail BMC.
Pour en savoir plus sur l'enregistrement de client_id et client_secret, reportez-vous au guide de démarrage rapide de l'API Bare Metal Cloud.
Ci-dessous la fonction Python qui génère le jeton d'accès pour l'API :
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
Étape 2 :Créer des instances de serveur Bare Metal
Utilisez les appels d'API REST POST/servers pour créer des instances de serveur bare metal. Pour chaque requête POST/serveurs, spécifiez les paramètres requis, tels que l'emplacement du centre de données, le type de serveur, le système d'exploitation, etc.
Vous trouverez ci-dessous la fonction Python qui appelle l'API BMC pour créer un serveur bare metal.
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
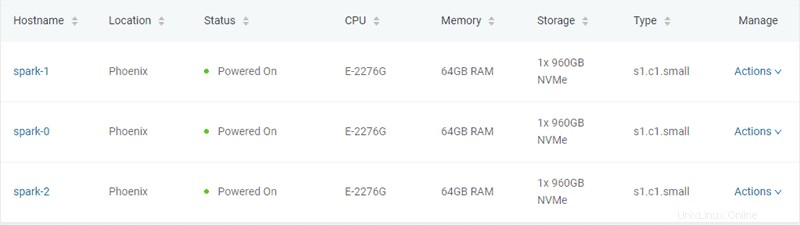
Dans cet exemple, trois serveurs bare metal de type "s1.c1.small" sont créés, comme spécifié dans le fichier server-settings.conf.
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
La sortie attendue du script Python qui génère le jeton et provisionne les serveurs est la suivante :
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... Une fois qu'il a créé les trois serveurs bare metal, le script communique avec l'API BMC pour vérifier l'état du serveur jusqu'à ce que le provisionnement soit terminé et que les serveurs soient sous tension.
Étape 3 :Provisionner le cluster Apache Spark
Une fois les serveurs provisionnés, le script Python établit une connexion SSH en utilisant l'adresse IP publique des serveurs. Ensuite, le script installe Spark sur les serveurs Ubuntu. Cela inclut l'installation de JDK , Échelle , Git et Étincelle sur tous les serveurs.
Pour démarrer le processus, exécutez le all_hosts.sh fichier sur tous les serveurs. Le script fournit des instructions de téléchargement et d'installation ainsi que la configuration de l'environnement nécessaire pour préparer le cluster à l'utilisation.
Apache Spark inclut des scripts qui configurent les serveurs en tant que nœuds maîtres et nœuds de travail. La seule contrainte dans la configuration d'un nœud de travail est d'avoir déjà configuré le nœud maître. Le premier serveur à provisionner est affecté en tant que nœud Spark Master.
La fonction Python suivante effectue cette tâche :
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))Exécutez le master_host.sh fichier pour configurer le premier serveur en tant que nœud maître. Voir ci-dessous le contenu du master_host.sh fichier :
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shUne fois le nœud maître attribué et configuré, les deux autres nœuds sont ajoutés au cluster Spark.
Voir ci-dessous le contenu de worker_host.sh fichier :
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
Le provisionnement d'un cluster Apache Spark est terminé. Vous trouverez ci-dessous la sortie attendue du script Python :
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
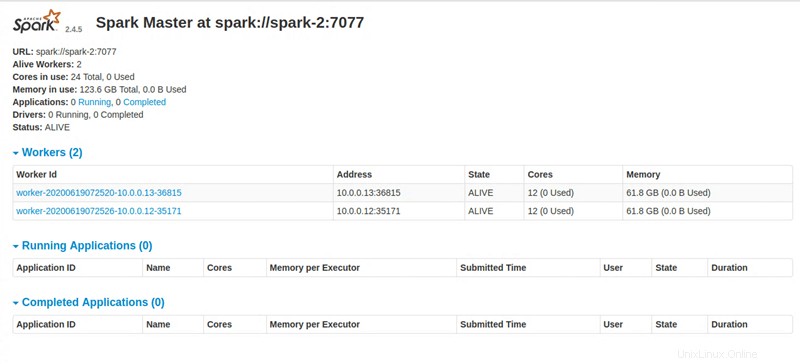
Master node UI: http://131.153.142.234:8080
Étape 4 :Accéder au tableau de bord Apache Spark
Lors de l'exécution de toutes les instructions, le script Python fournit un lien pour accéder au tableau de bord Apache Spark.