Apache Spark est un framework de calcul en cluster gratuit et open source utilisé pour l'analyse, l'apprentissage automatique et le traitement de graphes sur de gros volumes de données. Spark est livré avec plus de 80 opérateurs de haut niveau qui vous permettent de créer des applications parallèles et de les utiliser de manière interactive à partir des shells Scala, Python, R et SQL. Il s'agit d'un moteur de traitement de données en mémoire ultra-rapide spécialement conçu pour la science des données. Il fournit un riche ensemble de fonctionnalités, notamment la vitesse, la tolérance aux pannes, le traitement de flux en temps réel, l'informatique en mémoire, l'analyse avancée et bien d'autres.
Dans ce tutoriel, nous allons vous montrer comment installer Apache Spark sur le serveur Debian 10.
Prérequis
- Un serveur exécutant Debian 10 avec 2 Go de RAM.
- Un mot de passe root est configuré sur votre serveur.
Mise en route
Avant de commencer, il est recommandé de mettre à jour votre serveur avec la dernière version. Vous pouvez le mettre à jour à l'aide de la commande suivante :
apt-get update -y
apt-get upgrade -y
Une fois votre serveur mis à jour, redémarrez-le pour appliquer les modifications.
Installer Java
Apache Spark est écrit en langage Java. Vous devrez donc installer Java sur votre système. Par défaut, la dernière version de Java est disponible dans le référentiel par défaut de Debian 10. Vous pouvez l'installer à l'aide de la commande suivante :
apt-get install default-jdk -y
Après avoir installé Java, vérifiez la version installée de Java à l'aide de la commande suivante :
java --version
Vous devriez obtenir le résultat suivant :
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
Télécharger Apache Spark
Tout d'abord, vous devrez télécharger la dernière version d'Apache Spark à partir de son site officiel. Au moment de la rédaction de cet article, la dernière version d'Apache Spark est la 3.0. Vous pouvez le télécharger dans le répertoire /opt avec la commande suivante :
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Une fois le téléchargement terminé, extrayez le fichier téléchargé à l'aide de la commande suivante :
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
Ensuite, renommez le répertoire extrait en spark comme indiqué ci-dessous :
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
Ensuite, vous devrez définir l'environnement pour Spark. Vous pouvez le faire en éditant le fichier ~/.bashrc :
nano ~/.bashrc
Ajoutez les lignes suivantes à la fin du fichier :
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Enregistrez et fermez le fichier lorsque vous avez terminé. Ensuite, activez l'environnement avec la commande suivante :
source ~/.bashrc
Démarrer le serveur maître
Vous pouvez maintenant démarrer le serveur maître à l'aide de la commande suivante :
start-master.sh
Vous devriez obtenir le résultat suivant :
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
Par défaut, Apache Spark écoute sur le port 8080. Vous pouvez le vérifier avec la commande suivante :
netstat -ant | grep 8080
Sortie :
tcp6 0 0 :::8080 :::* LISTEN
Maintenant, ouvrez votre navigateur Web et tapez l'URL http://server-ip-address:8080. Vous devriez voir la page suivante :
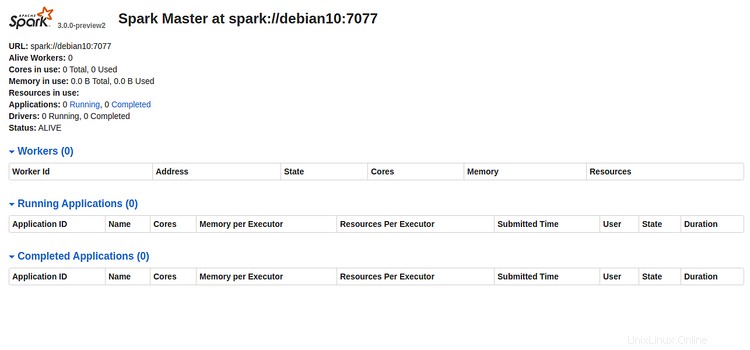
Veuillez noter l'URL Spark "spark://debian10:7077 " de l'image ci-dessus. Cela sera utilisé pour démarrer le processus de travail Spark.
Démarrer le processus de travail Spark
Maintenant, vous pouvez démarrer le processus de travail Spark avec la commande suivante :
start-slave.sh spark://debian10:7077
Vous devriez obtenir le résultat suivant :
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Accéder à Spark Shell
Spark Shell est un environnement interactif qui offre un moyen simple d'apprendre l'API et d'analyser les données de manière interactive. Vous pouvez accéder au shell Spark avec la commande suivante :
spark-shell
Vous devriez voir le résultat suivant :
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
À partir de là, vous pouvez apprendre à tirer le meilleur parti d'Apache Spark rapidement et facilement.
Si vous souhaitez arrêter le serveur Spark maître et esclave, exécutez les commandes suivantes :
stop-slave.sh
stop-master.sh
C'est tout pour le moment, vous avez installé avec succès Apache Spark sur le serveur Debian 10. Pour plus d'informations, vous pouvez consulter la documentation officielle de Spark sur Spark Doc.