Présentation
Les bases de données distribuées sont utilisées pour la mise à l'échelle horizontale , et ils sont conçus pour répondre aux exigences de la charge de travail sans avoir à apporter de modifications à l'application de base de données ni à mettre à l'échelle verticalement une seule machine.
Les bases de données distribuées résolvent divers problèmes , tels que la disponibilité, la tolérance aux pannes, le débit, la latence, l'évolutivité et de nombreux autres problèmes pouvant survenir lors de l'utilisation d'une seule machine et d'une seule base de données.
Dans cet article, vous apprendrez ce que sont les bases de données distribuées et leurs avantages et inconvénients.

Définition de la base de données distribuée
Une base de données distribuée représente plusieurs bases de données interconnectées réparties sur plusieurs sites connectés par un réseau. Comme les bases de données sont toutes connectées, elles apparaissent comme une seule base de données aux utilisateurs.
Les bases de données distribuées utilisent plusieurs nœuds. Ils évoluent horizontalement et développent un système distribué. Plus de nœuds dans le système fournissent plus de puissance de calcul, offrent une plus grande disponibilité et résolvent le problème du point de défaillance unique.
Différentes parties de la base de données distribuée sont stockées dans plusieurs emplacements physiques , et les exigences de traitement sont réparties entre les processeurs sur plusieurs nœuds de base de données.
Un système centralisé de gestion de base de données distribuée (DDBMS ) gère les données distribuées comme si elles étaient stockées dans un emplacement physique. DDBMS synchronise toutes les opérations de données entre les bases de données et garantit que les mises à jour d'une base de données se répercutent automatiquement sur les bases de données d'autres sites.
Fonctionnalités de base de données distribuée
Certaines fonctionnalités générales des bases de données distribuées sont :
- Indépendance géographique - Les données sont physiquement stockées sur plusieurs sites et gérées par un DDBMS indépendant.
- Traitement distribué des requêtes - Les bases de données distribuées répondent aux requêtes dans un environnement distribué qui gère les données sur plusieurs sites. Les requêtes de haut niveau sont transformées en un plan d'exécution des requêtes pour une gestion plus simple.
- Gestion distribuée des transactions - Fournit une base de données distribuée cohérente via des protocoles de validation, des techniques de contrôle de concurrence distribuées et des méthodes de récupération distribuées en cas de nombreuses transactions et échecs.
- Intégration transparente - Les bases de données d'une collection représentent généralement une seule base de données logique et sont interconnectées.
- Lien réseau - Toutes les bases de données d'une collection sont reliées par un réseau et communiquent entre elles.
- Traitement des transactions - Les bases de données distribuées intègrent le traitement des transactions, qui est un programme comprenant une collection d'une ou plusieurs opérations de base de données. Le traitement des transactions est un processus atomique qui est entièrement exécuté ou pas du tout.
Types de bases de données distribuées
Il existe deux types de bases de données distribuées :
- Homogène
- Hétérogène
Homogène
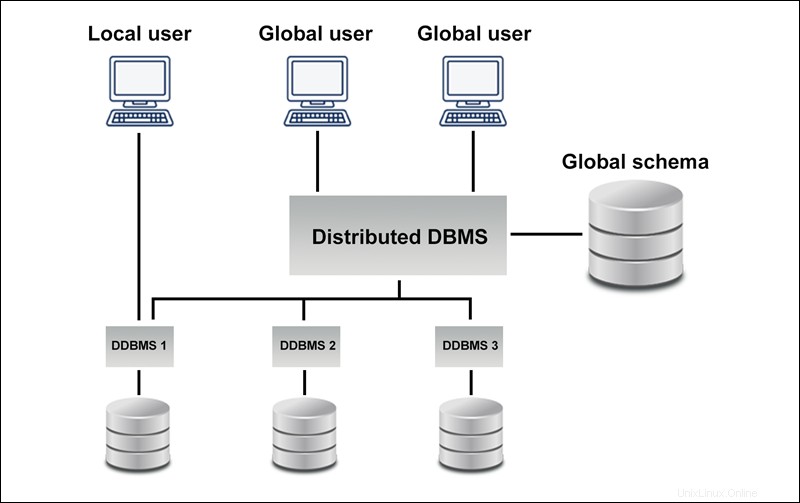
Une base de données distribuée homogène est un réseau de bases de données identiques stockées sur plusieurs sites. Les sites ont le même système d'exploitation, le même DDBMS et la même structure de données, ce qui les rend facilement gérables.
Des bases de données homogènes permettent aux utilisateurs d'accéder aux données de chacune des bases de données de manière transparente.
Le schéma suivant montre un exemple de base de données homogène :
Hétérogène
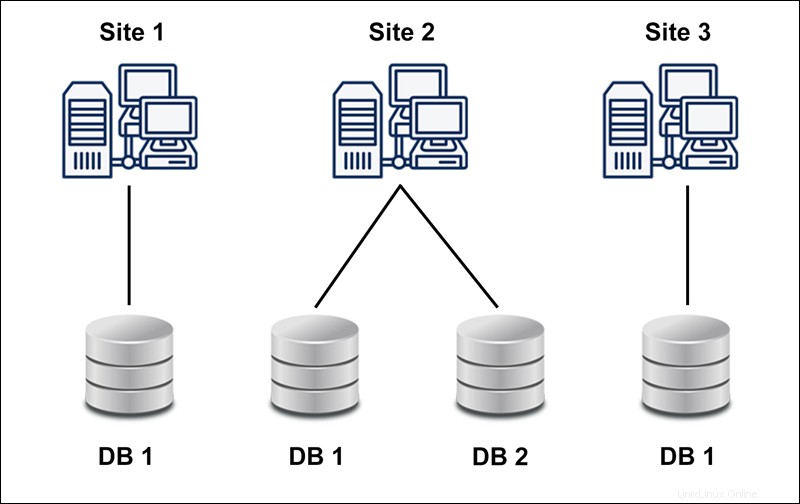
Une base de données distribuée hétérogène utilise différents schémas, systèmes d'exploitation, DDBMS et différents modèles de données.
Dans le cas d'une base de données distribuée hétérogène, un site particulier peut ignorer complètement les autres sites entraînant une coopération limitée dans le traitement des requêtes des utilisateurs. La limitation est la raison pour laquelle les traductions sont nécessaires pour établir la communication entre les sites.
Le schéma suivant montre un exemple de base de données hétérogène :
Stockage de base de données distribuée
Le stockage de base de données distribuée est géré de deux manières :
- Réplication
- Fragmentation
Réplication
Dans la réplication de base de données, les systèmes stockent des copies de données sur différents sites . Si une base de données entière est disponible sur plusieurs sites, il s'agit d'une base de données entièrement redondante.
L'avantage de la réplication de base de données est qu'elle augmente la disponibilité des données o n différents sites et permet de traiter des demandes de requêtes parallèles.
Cependant, la réplication de la base de données signifie que les données nécessitent des mises à jour constantes et une synchronisation avec d'autres sites pour conserver une copie exacte de la base de données. Toute modification apportée sur un site doit être enregistrée sur d'autres sites, sinon des incohérences se produisent.
Les mises à jour constantes entraînent une surcharge importante du serveur et compliquent le contrôle de la concurrence, car de nombreuses requêtes simultanées doivent être vérifiées sur tous les sites disponibles.
Fragmentation
En ce qui concerne la fragmentation du stockage de base de données distribuée, les relations sont fragmentées, ce qui signifie qu'elles sont divisées en parties plus petites . Chacun des fragments est stocké sur un site différent, là où il est requis.
La condition préalable à la fragmentation est de s'assurer que les fragments peuvent ensuite être reconstruits dans la relation d'origine sans perdre de données.
L'avantage de la fragmentation est qu'il n'y a pas de copies de données , ce qui évite l'incohérence des données.
Il existe deux types de fragmentation :
- Fragmentation horizontale - Le schéma de relation est fragmenté en groupes de lignes, et chaque groupe (tuple) est affecté à un fragment.
- Fragmentation verticale - Le schéma de relation est fragmenté en schémas plus petits, et chaque fragment contient une clé candidate commune pour garantir une jointure sans perte.
Avantages et inconvénients de la base de données distribuée
Voici quelques avantages et inconvénients clés des bases de données distribuées :
| Avantages | Inconvénients |
|---|---|
| Développement modulaire | Logiciel coûteux |
| Fiabilité | Gros frais généraux |
| Réduction des coûts de communication | Intégrité des données |
| Meilleure réponse | Distribution incorrecte des données |
Les avantages et les inconvénients sont expliqués en détail dans les sections suivantes.
Avantages
- Développement modulaire . Le développement modulaire d'une base de données distribuée implique qu'un système peut être étendu à de nouveaux emplacements ou unités en ajoutant de nouveaux serveurs et données à la configuration existante et en les connectant au système distribué sans interruption. Ce type d'extension n'entraîne aucune interruption du fonctionnement des bases de données distribuées.
- Fiabilité . Les bases de données distribuées offrent une plus grande fiabilité contrairement aux bases de données centralisées. En cas de défaillance de la base de données dans une base de données centralisée, le système s'arrête complètement. Dans une base de données distribuée, le système fonctionne même lorsque des pannes se produisent, ne fournissant que des performances réduites jusqu'à ce que le problème soit résolu.
- Réduction des coûts de communication . Le stockage local des données réduit les coûts de communication pour la manipulation des données dans les bases de données distribuées. Le stockage local des données n'est pas possible dans les bases de données centralisées.
- Meilleure réponse . Une distribution efficace des données dans un système de base de données distribué fournit une réponse plus rapide lorsque les demandes des utilisateurs sont satisfaites localement. Dans les bases de données centralisées, les demandes des utilisateurs passent par la machine centrale, qui traite toutes les demandes. Le résultat est une augmentation du temps de réponse, en particulier avec un grand nombre de requêtes.
Inconvénients
- Logiciel coûteux . Garantir la transparence et la coordination des données sur plusieurs sites nécessite souvent l'utilisation de logiciels coûteux dans un système de base de données distribué.
- Gros frais généraux . De nombreuses opérations sur plusieurs sites nécessitent de nombreux calculs et une synchronisation constante lors de l'utilisation de la réplication de base de données, ce qui entraîne une surcharge de traitement importante.
- Intégrité des données . Un problème possible lors de l'utilisation de la réplication de base de données est l'intégrité des données, qui est compromise par la mise à jour des données sur plusieurs sites.
- Répartition incorrecte des données . La réactivité aux demandes des utilisateurs dépend en grande partie de la bonne distribution des données. Cela signifie que la réactivité peut être réduite si les données ne sont pas correctement réparties sur plusieurs sites.