Apache Hadoop est un framework logiciel gratuit et open source écrit en Java pour le stockage distribué et le traitement de données volumineuses à l'aide de MapReduce. Il gère la très grande taille des ensembles de données en les divisant en grands blocs et en les distribuant sur les ordinateurs d'un cluster.
Plutôt que de s'appuyer sur des clusters de système d'exploitation standard, les modules Hadoop sont conçus pour détecter et gérer la défaillance au niveau de la couche applicative et vous offrent un service hautement disponible au niveau logiciel.
Le framework Hadoop de base se compose des modules suivants,
- Hadoop commun – Contient un ensemble commun de bibliothèques et d'utilitaires pour prendre en charge d'autres modules Hadoop
- Système de fichiers distribué Hadoop (HDFS) – Système de fichiers distribué basé sur Java qui stocke les données sur du matériel standard, offrant un débit très élevé à l'application.
- FIL Hadoop – Gère les ressources sur les clusters de calcul et les utilise pour planifier les applications des utilisateurs.
- Hadoop MapReduce – Framework pour le traitement de données à grande échelle basé sur le modèle de programmation MapReduce.
Dans cet article, nous verrons comment installer Apache Hadoop sur RHEL 8.
Prérequis
Basculez vers l'utilisateur root.
su -
OU
sudo su -
Apache Hadoop v3.1.2 ne prend en charge que la version 8 de Java. Installez donc OpenJDK 8 ou Oracle JDK 8.
Dans cette démo, j'utiliserai OpenJDK 8.
yum -y install java-1.8.0-openjdk wget
Vérifiez la version Java.
version Java
Sortie :
openjdk version "1.8.0_201"Environnement d'exécution OpenJDK (build 1.8.0_201-b09)OpenJDK 64-Bit Server VM (build 25.201-b09, mode mixte)
Installer Apache Hadoop sur RHEL 8
Créer un utilisateur Hadoop
Il est recommandé d'exécuter Apache Hadoop par un utilisateur régulier. Donc, ici, nous allons créer un utilisateur nommé hadoop et définir un mot de passe pour l'utilisateur.
useradd -m -d /home/hadoop -s /bin/bash hadooppasswd hadoop
Maintenant, configurez ssh sans mot de passe sur le système local en suivant les étapes ci-dessous.
# su - hadoop$ ssh-keygen$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys$ chmod 600 ~/.ssh/authorized_keys
Vérifiez la communication sans mot de passe avec votre système local.
$ ssh 127.0.0.1
Sortie :
Si vous vous connectez via ssh pour la première fois, vous devrez taper yes pour ajouter des clés RSA aux hôtes connus.
[hadoop@rhel8 ~]$ ssh 127.0.0.1 L'authenticité de l'hôte '127.0.0.1 (127.0.0.1)' ne peut pas être établie. L'empreinte digitale de la clé ECDSA est SHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAk. continuer à se connecter (oui/non) ? Oui Avertissement :Ajout permanent de '127.0.0.1' (ECDSA) à la liste des hôtes connus.Activez la console Web avec :systemctl enable --now cockpit.socketDernière connexion :Wed May 8 12:15:04 2019 from 127.0.0.1[hadoop @rhel8 ~]$
Télécharger Hadoop
Visitez la page Apache Hadoop pour télécharger la dernière version d'Apache Hadoop (Choisissez toujours la version prête pour la production en consultant la documentation), ou vous pouvez utiliser la commande suivante dans le terminal pour télécharger Hadoop v3.1.2.
$ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz$ tar -zxvf hadoop-3.1.2.tar. gz $ mv hadoop-3.1.2 hadoop
Types de cluster Hadoop
Il existe trois types de clusters Hadoop :
- Mode local (autonome) – Il s'exécute comme un processus Java unique.
- Mode pseudo-distribué – Chaque démon Hadoop s'exécute comme un processus distinct.
- Mode entièrement distribué – un cluster multinœud. Allant de quelques nœuds à un cluster extrêmement volumineux.
Configurer les variables d'environnement
Ici, nous allons configurer Hadoop en mode pseudo-distribué. Tout d'abord, nous allons définir des variables d'environnement dans le fichier ~/.bashrc.
Modifiez les entrées des variables JAVA_HOME et HADOOP_HOME dans le fichier en fonction de votre environnement.exporter JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ exporter HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/binADOexport_PATH=$HOME :$HADOOP_HOMEexport_Appliquez des variables d'environnement à votre session de terminal actuelle.
$ source ~/.bashrcConfigurer Hadoop
Modifiez le fichier d'environnement Hadoop et mettez à jour la variable comme indiqué ci-dessous.
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.shMettez à jour la variable JAVA_HOME selon votre environnement.
exporter JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/Nous allons maintenant modifier les fichiers de configuration de Hadoop en fonction du mode de cluster que nous avons configuré (pseudo-distribué).
$ cd $HADOOP_HOME/etc/hadoopModifiez core-site.xml et mettez à jour le fichier avec le nom d'hôte HDFS.
fs.defaultFS hdfs://rhel8.itzgeek.local :9000 Créez les répertoires namenode et datanode sous le répertoire home /home/hadoop de l'utilisateur hadoop.
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}Modifiez hdfs-site.xml et mettez à jour le fichier avec les informations de répertoire NameNode et DataNode.
dfs.replication 1 dfs.name.dir fichier :///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode Modifiez mapred-site.xml.
mapreduce.framework.name fil Modifiez le fichier yarn-site.xml.
yarn.nodemanager.aux-services mapreduce_shuffle Formatez le NameNode à l'aide de la commande suivante.
$ hdfs namenode -formatSortie :
. . .. . .2019-05-13 19:33:14,720 INFO namenode.FSImage :Nouveau BlockPoolId alloué :BP-1601223288-192.168.1.10-15577561946432019-05-13 19:33:15,100 INFO common.Storage :Répertoire de stockage /home/hadoop/ hadoopdata/hdfs/namenode a été formaté avec succès.2019-05-13 19:33:15,436 INFO namenode.FSImageFormatProtobuf :Enregistrement du fichier image /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 sans compression2019-05- 13 19:33:16,804 INFO namenode.FSImageFormatProtobuf :Fichier image /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 de taille 393 octets enregistrés en 1 seconde .2019-05-13 19:33:17,106 INFO namenode .NNStorageRetentionManager :va conserver 1 images avec txid>=02019-05-13 19:33:17,150 INFO namenode.NameNode :SHUTDOWN_MSG :/******************** ****************************************SHUTDOWN_MSG :Arrêt de NameNode sur rhel8.itzgeek. local/192.168.1.10************************************************ ***************/Pare-feu
Exécutez les commandes ci-dessous pour autoriser les connexions Apache Hadoop via le pare-feu. Exécutez ces commandes en tant qu'utilisateur root.
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcpfirewall-cmd --reloadDémarrer Hadoop &Yarn
Démarrez les démons NameNode et DataNode en utilisant les scripts fournis par Hadoop.
$ start-dfs.shSortie :
Démarrage des namenodes sur [rhel8.itzgeek.local]rhel8.itzgeek.local :Avertissement :Ajout permanent de 'rhel8.itzgeek.local,fe80::4480:83a5:c52:ea80%enp0s3' (ECDSA) à la liste des hôtes connus. Démarrage de datanodeslocalhost :Avertissement :Ajout permanent de « localhost » (ECDSA) à la liste des hôtes connus. chargez la bibliothèque native-hadoop pour votre plate-forme... en utilisant les classes Java intégrées, le cas échéantOuvrez un navigateur et accédez à l'adresse ci-dessous pour accéder à Namenode.
http://ip.ad.dre.ss:9870/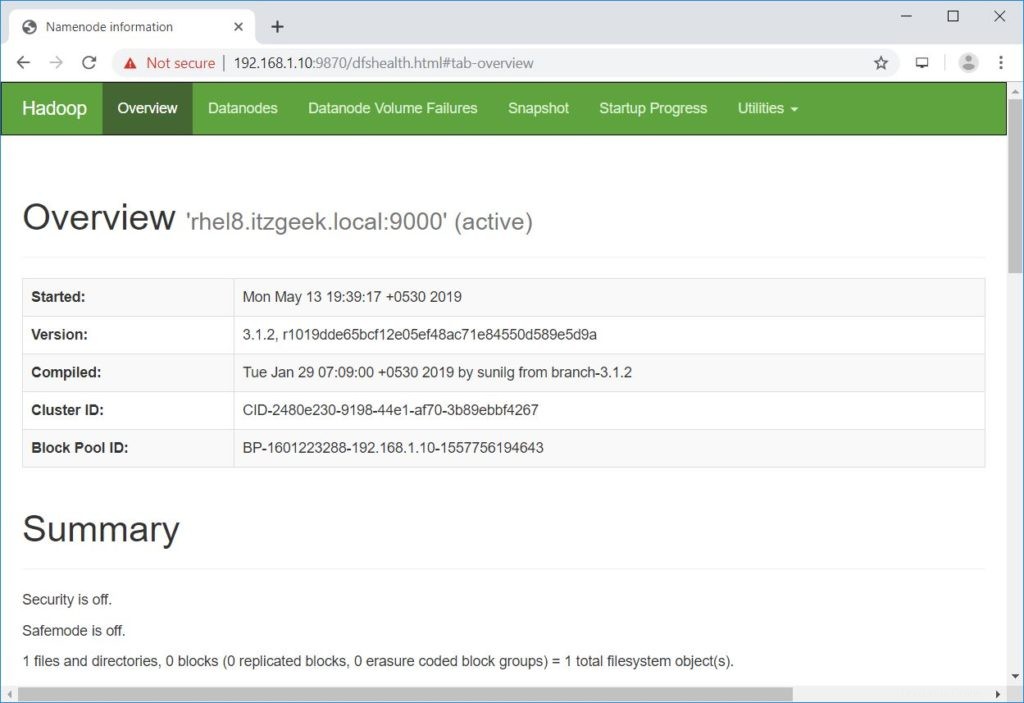
Démarrez ResourceManager et NodeManagers.
$ start-yarn.shSortie :
Démarrage du gestionnaire de ressourcesDémarrage des gestionnaires de nœudsOuvrez un navigateur et accédez à l'adresse ci-dessous pour accéder à ResourceManager.
http://ip.ad.dre.ss:8088/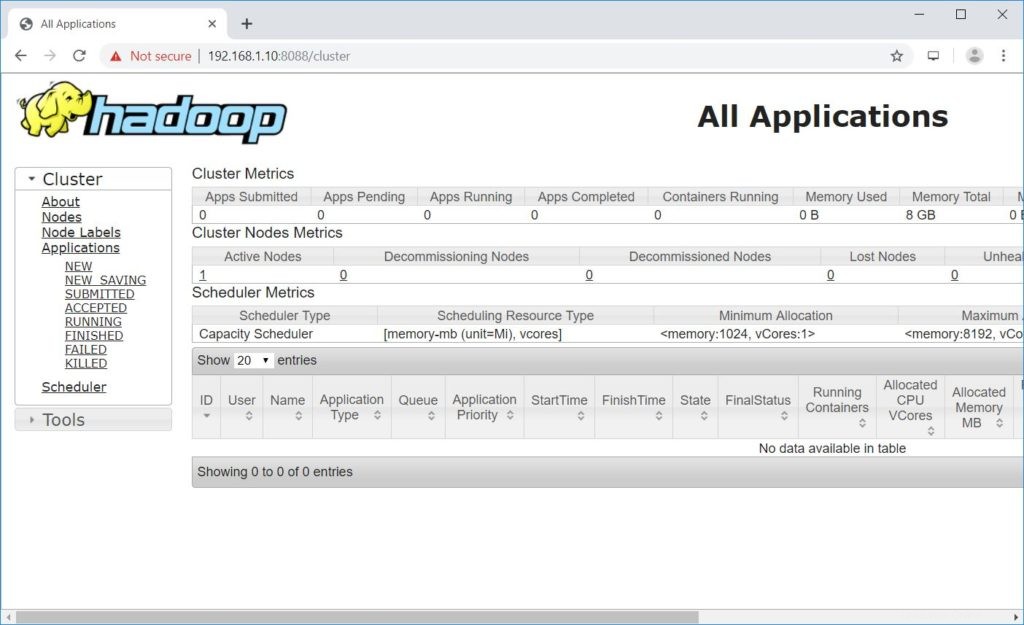
Tester Apache Hadoop
Nous allons maintenant tester Apache Hadoop en y téléchargeant un exemple de fichier. Avant de télécharger un fichier sur HDFS, créez un répertoire dans HDFS.
$ hdfs dfs -mkdir /rajVérifiez que le répertoire créé existe dans HDFS.
hdfs dfs -ls /Sortie :
Found 1 itemsdrwxr-xr-x - hadoop supergroup 0 2019-05-08 13:20 /rajTéléchargez un fichier dans le répertoire HDFS raj avec la commande suivante.
$ hdfs dfs -put ~/.bashrc /rajLes fichiers téléchargés peuvent être visualisés en exécutant la commande ci-dessous.
$ hdfs dfs -ls /rajOU
Accédez à NameNode>> Utilitaires >> Parcourir le système de fichiers dans NameNode.
http://ip.ad.dre.ss:9870/explorer.html#/raj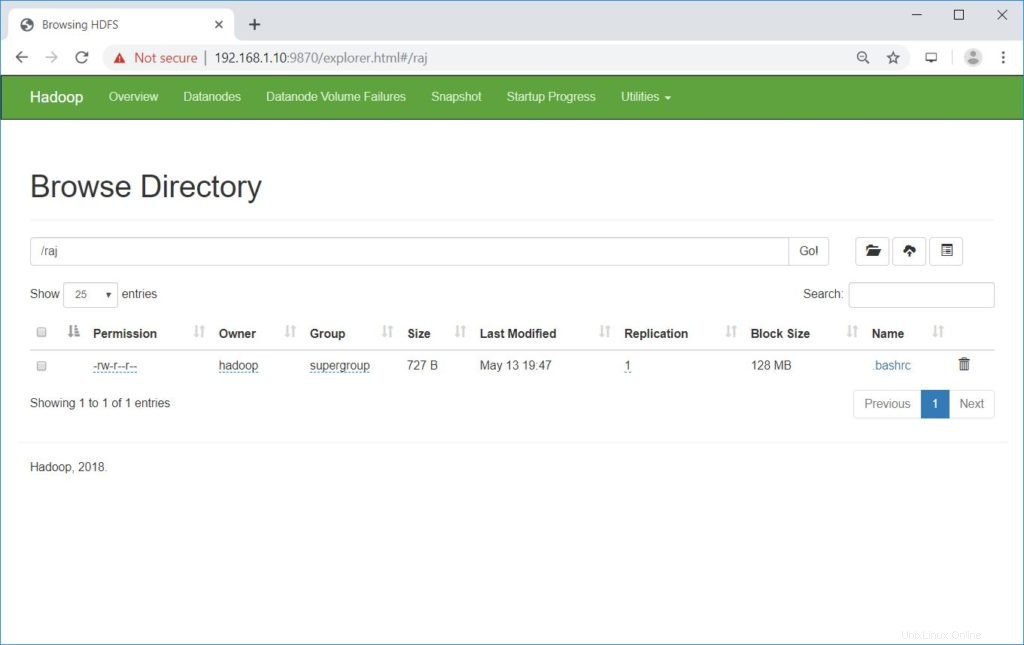
Vous pouvez copier les fichiers de HDFS vers vos systèmes de fichiers locaux en utilisant la commande ci-dessous.
$ hdfs dfs -get /raj /tmp/Si nécessaire, vous pouvez supprimer les fichiers et répertoires dans HDFS à l'aide des commandes suivantes.
$ hdfs dfs -rm -f /raj/.bashrc$ hdfs dfs -rmdir /rajConclusion
J'espère que cet article vous a aidé à installer et à configurer un cluster Apache Hadoop à nœud unique sur RHEL 8. Vous pouvez lire la documentation officielle de Hadoop pour plus d'informations. Veuillez partager vos commentaires dans la section des commentaires.