Hadoup est un framework open-source largement utilisé pour gérer le Bigdata . La plupart des Bigdata/Data Analytics des projets sont construits au-dessus de l'écosystème Hadoop . Il se compose de deux couches, l'une est pour le stockage de données et un autre pour le traitement des données .
Stockage sera pris en charge par son propre système de fichiers appelé HDFS (système de fichiers distribué Hadoop ) et Traitement sera pris en charge par YARN (Encore un autre négociateur de ressources ). Mapreduce est le moteur de traitement par défaut de l'Hadoop Eco-System .
Cet article décrit le processus d'installation du pseudonode installation de Hadoop , où tous les démons (JVM ) exécutera un nœud unique Cluster sur CentOS 7 .
Ceci est principalement destiné aux débutants pour apprendre Hadoop. En temps réel, Hadoop sera installé en tant que cluster multinœud où les données seront réparties entre les serveurs sous forme de blocs et le travail sera exécuté de manière parallèle.
Prérequis
- Une installation minimale du serveur CentOS 7.
- Version Java v1.8.
- Hadoop 2.x version stable.
Sur cette page
- Comment installer Java sur CentOS 7
- Configurer la connexion sans mot de passe sur CentOS 7
- Comment installer Hadoop Single Node dans CentOS 7
- Comment configurer Hadoop dans CentOS 7
- Formater le système de fichiers HDFS via le NameNode
Installer Java sur CentOS 7
1. Hadoup est un Éco-Système composé de Java . Nous avons besoin de Java installé dans notre système obligatoirement pour installer Hadoop .
# yum install java-1.8.0-openjdk
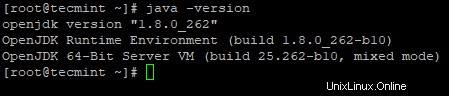
2. Ensuite, vérifiez la version installée de Java sur le système.
# java -version
Configurer la connexion sans mot de passe sur CentOS 7
Nous devons configurer ssh sur notre machine, Hadoop gérera les nœuds avec l'utilisation de SSH . Le nœud maître utilise SSH connexion pour connecter ses nœuds esclaves et effectuer des opérations telles que démarrer et arrêter.
Nous devons configurer ssh sans mot de passe pour que le maître puisse communiquer avec les esclaves en utilisant ssh sans mot de passe. Sinon pour chaque établissement de connexion, il faut entrer le mot de passe.
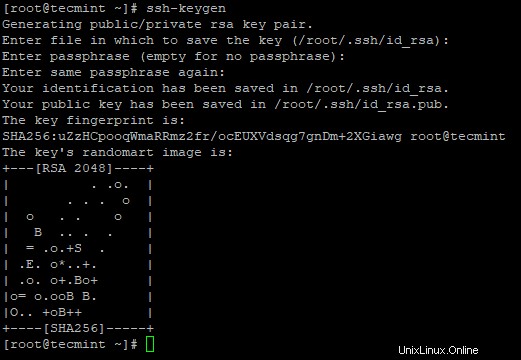
3. Configurez une connexion SSH sans mot de passe à l'aide des commandes suivantes sur le serveur.
# ssh-keygen# ssh-copy-id -i localhost
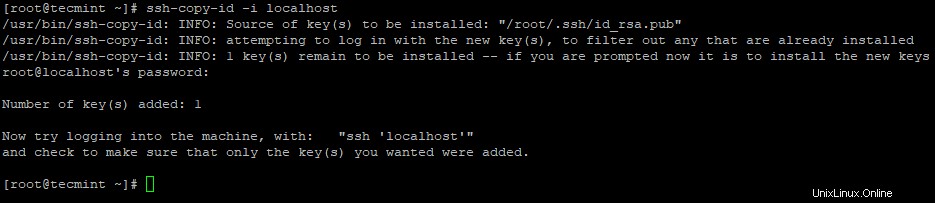
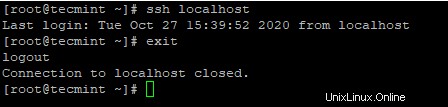
4. Après avoir configuré la connexion SSH sans mot de passe, essayez de vous reconnecter, vous serez connecté sans mot de passe.
# hôte local ssh
Installer Hadoop dans CentOS 7
5. Accédez au site Web Apache Hadoop et téléchargez la version stable de Hadoop à l'aide de la commande wget suivante.
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz# tar xvpzf hadoop-2.10.1.tar.gz6. Ensuite, ajoutez le Hadoop variables d'environnement dans
~/.bashrcfichier comme indiqué.HADOOP_PREFIX=/root/hadoop-2.10.1PATH=$PATH:$HADOOP_PREFIX/binexport PATH JAVA_HOME HADOOP_PREFIX7. Après avoir ajouté des variables d'environnement à
~/.bashrcle fichier, sourcez le fichier et vérifiez le Hadoop en exécutant les commandes suivantes.# source ~/.bashrc# cd $HADOOP_PREFIX# version bin/hadoop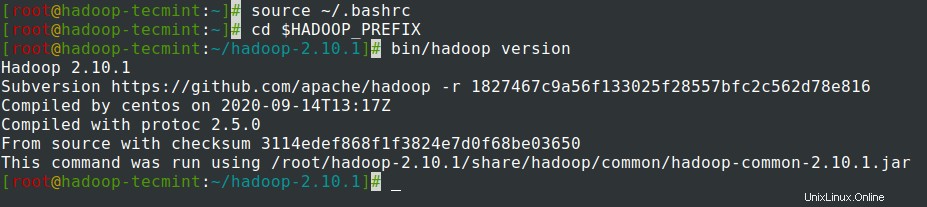
Configurer Hadoop dans CentOS 7
Nous devons configurer ci-dessous les fichiers de configuration Hadoop afin de s'adapter à votre machine. Dans Hadoop, chaque service a son propre numéro de port et son propre répertoire pour stocker les données.
- Fichiers de configuration Hadoop :core-site.xml, hdfs-site.xml, mapred-site.xml et yarn-site.xml
8. Tout d'abord, nous devons mettre à jour JAVA_HOME et Hadoop chemin dans hadoop-env.sh fichier comme indiqué.
# cd $HADOOP_PREFIX/etc/hadoop# vi hadoop-env.sh
Entrez la ligne suivante au début du fichier.
exporter JAVA_HOME=/usr/lib/jvm/java-1.8.0/jreexport HADOOP_PREFIX=/root/hadoop-2.10.1
9. Ensuite, modifiez le core-site.xml fichier.
# cd $HADOOP_PREFIX/etc/hadoop# vi core-site.xml
Collez ce qui suit entre <configuration> balises comme indiqué.
fs.defaultFS hdfs://localhost:9000
10. Créez les répertoires ci-dessous sous tecmint répertoire personnel de l'utilisateur, qui sera utilisé pour NN et DN stockage.
# mkdir -p /home/tecmint/hdata/# mkdir -p /home/tecmint/hdata/data# mkdir -p /home/tecmint/hdata/nom
10. Ensuite, modifiez le hdfs-site.xml fichier.
# cd $HADOOP_PREFIX/etc/hadoop# vi hdfs-site.xml
Collez ce qui suit entre <configuration> balises comme indiqué.
dfs.replication 1 dfs.namenode.name.dir /home/tecmint/ hdata/name dfs .datanode.data.dir home/tecmint/hdata/data
11. Encore une fois, modifiez le mapred-site.xml fichier.
# cd $HADOOP_PREFIX/etc/hadoop# cp mapred-site.xml.template mapred-site.xml# vi mapred-site.xml
Collez ce qui suit entre <configuration> balises comme indiqué.
mapreduce.framework.name fil
12. Enfin, modifiez le yarn-site.xml fichier.
# cd $HADOOP_PREFIX/etc/hadoop# vi yarn-site.xml
Collez ce qui suit entre <configuration> balises comme indiqué.
yarn.nodemanager.aux-services mapreduce_shuffle
Formater le système de fichiers HDFS via le NameNode
13. Avant de démarrer le Cluster , nous devons formater le Hadoop NN dans notre système local où il a été installé. Habituellement, cela se fera dans la phase initiale avant de démarrer le cluster pour la première fois.
Formatage du NN entraînera une perte de données dans le métastore NN, nous devons donc être plus prudents, nous ne devons pas formater NN pendant que le cluster est en cours d'exécution, sauf si cela est requis intentionnellement.
# cd $HADOOP_PREFIX# bin/hadoop namenode -format
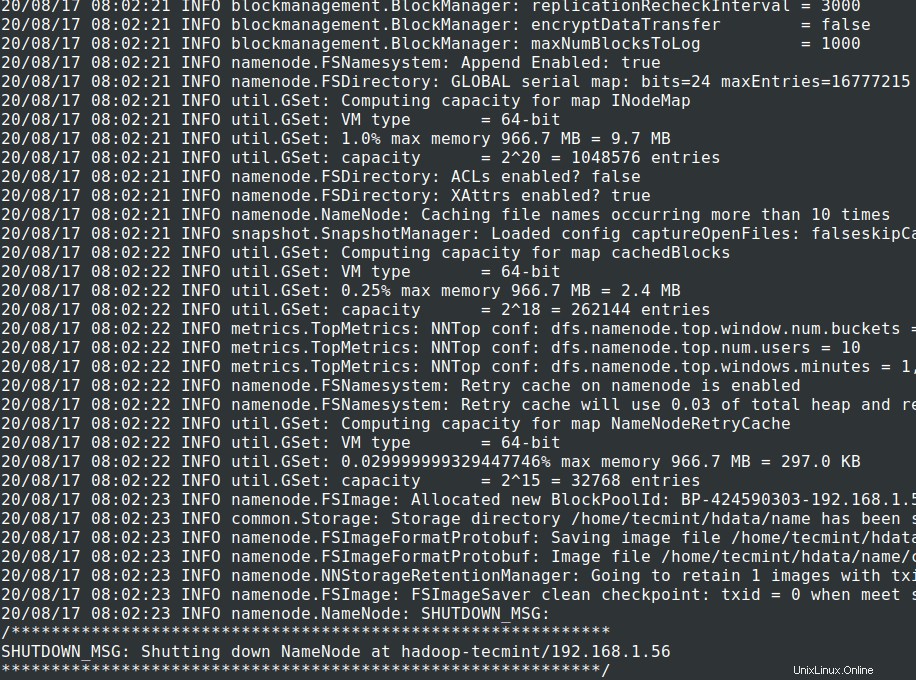
14. Démarrer NameNode démon et DataNode démon :(port 50070 ).
# cd $HADOOP_PREFIX# sbin/start-dfs.sh
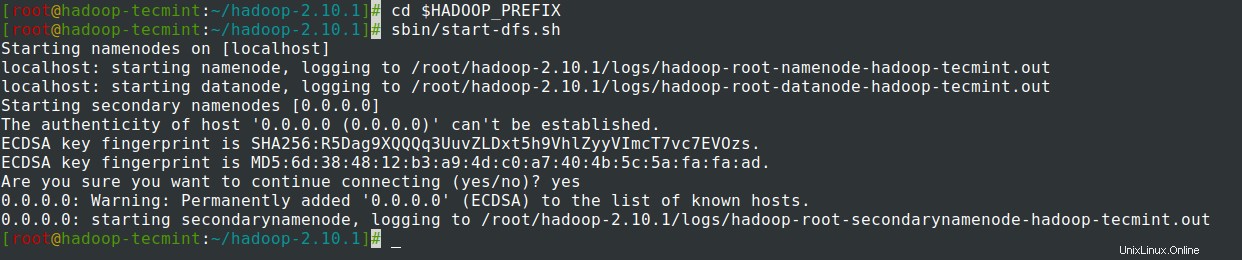
15. Démarrer ResourceManager démon et NodeManager démon :(port 8088 ).
# sbin/start-yarn.sh

16. Pour arrêter tous les services.
# sbin/stop-dfs.sh# sbin/stop-dfs.sh
Résumé
Résumé
Dans cet article, nous avons suivi le processus étape par étape pour configurer Hadoop Pseudonode (nœud unique ) Cluster . Si vous avez des connaissances de base sur Linux et que vous suivez ces étapes, le cluster sera UP en 40 minutes.
Cela peut être très utile pour le débutant pour commencer à apprendre et pratiquer Hadoop ou cette version vanille de Hadoop peut être utilisé à des fins de développement. Si nous voulons avoir un cluster en temps réel, soit nous avons besoin d'au moins 3 serveurs physiques en main, soit nous devons provisionner le Cloud pour avoir plusieurs serveurs.