Présentation
Les bases de données NoSQL nous permettent de stocker de grandes quantités de données et d'y accéder à tout moment, depuis n'importe quel endroit et appareil. Cependant, il est difficile de décider quelle technique de modélisation des données est la mieux adaptée à vos besoins. Heureusement, il existe une technique de modélisation des données pour chaque cas d'utilisation.
Dans ce didacticiel, nous couvrirons toutes les différentes techniques de modélisation de données NoSQL que vous pouvez utiliser lors de la création de votre base de données NoSQL.

Qu'est-ce qu'un modèle de données NoSQL ?
NoSQL ou « Not Only SQL » est un modèle de données qui diffère radicalement des attentes SQL traditionnelles.
La principale différence est que NoSQL n'utilise pas de technique de modélisation de données relationnelles et met l'accent sur une conception flexible. L'absence d'exigence pour un schéma rend la conception d'un processus beaucoup plus simple et moins cher. Cela ne veut pas dire que vous ne pouvez pas utiliser un schéma, mais plutôt que la conception du schéma est très flexible.
Une autre caractéristique utile des modèles de données NoSQL est qu'ils sont conçus pour une efficacité et une vitesse élevées en termes de création de millions de requêtes par seconde. Ceci est réalisé en ayant toutes les données contenues dans une table, et donc les JOINS et les références croisées ne sont pas aussi lourdes en termes de performances.
NoSQL est également unique en ce qu'il est évolutif horizontalement , par rapport à SQL qui n'est évolutif que verticalement. Avec NoSQL, vous pouvez simplement utiliser un autre fragment, qui est bon marché, plutôt que d'acheter plus de matériel, ce qui ne l'est pas.
Quatre types de bases de données NoSQL
De manière générale, il existe quatre types différents de bases de données NoSQL, avec des dizaines de modèles de données basés sur celles-ci :
Magasin clé-valeur
Conçus spécifiquement pour les exigences de hautes performances, et probablement l'un des modèles de données les plus courants, les magasins clé-valeur utilisent des valeurs clés avec des pointeurs pour stocker des données.
Ce pointeur est unique et renvoie directement à une information, qui peut être tout ce que vous souhaitez. Vous pouvez même utiliser une chaîne vide comme clé de valeur si vous le souhaitez, bien qu'il existe des limites supérieures à la taille d'une valeur en fonction de la base de données.
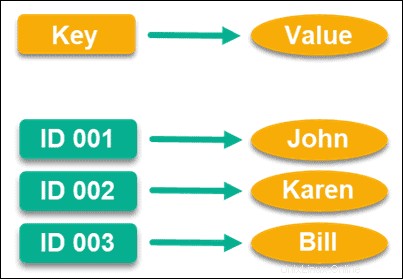
Chose intéressante, c'est Amazon qui a initialement aidé à faire décoller ce modèle de données, et ils l'utilisent pour DynamoDB. Étant donné qu'il s'agit de l'un des plus grands marchés en ligne au monde, vous pouvez voir à quel point ce modèle de données peut être performant.
Magasin basé sur des documents
Avec SQL, XML et JSON ont tendance à être liés, ce qui ralentit les requêtes et entrave l'ensemble du processus. Étant donné que NoSQL n'utilise pas le modèle relationnel, il n'a pas besoin de le faire, c'est là qu'interviennent les magasins basés sur des documents.
Toutes les données sont stockées dans une table, il n'y a donc pas besoin de références croisées et au lieu de stocker des informations dans une table, elles sont stockées dans un document. Bien que cela ressemble beaucoup à un magasin clé-valeur et puisse parfois être considéré sous son égide, la différence est que NoSQL basé sur des documents a généralement une forme de codage, telle que XML.
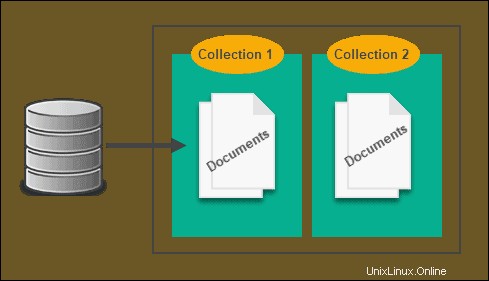
Il existe une base de données NoSQL spécifique à XML qui utilise un magasin de documents. En fait, Strider CD utilise MongoDB comme magasin de sauvegarde.
Magasin basé sur les colonnes
Ce type de modèle de données stocke les informations dans des colonnes plutôt que dans des lignes, ce qui est plus courant avec SQL. Les données sont stockées dans des colonnes, qui sont regroupées en familles, et ces familles sont ensuite regroupées en plusieurs colonnes. Cela crée essentiellement un modèle de données d'imbrication de colonnes presque illimité.
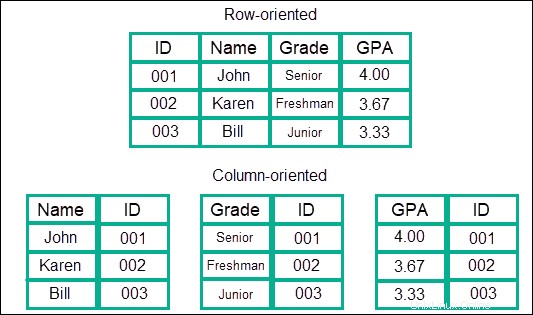
L'avantage est qu'il offre des vitesses incroyablement rapides par rapport à d'autres modèles ou NoSQL en ce qui concerne les recherches. Les données sont traitées comme une entrée continue, et il n'est donc pas nécessaire de sauter entre les lignes ou les différentes zones où les informations sont stockées.
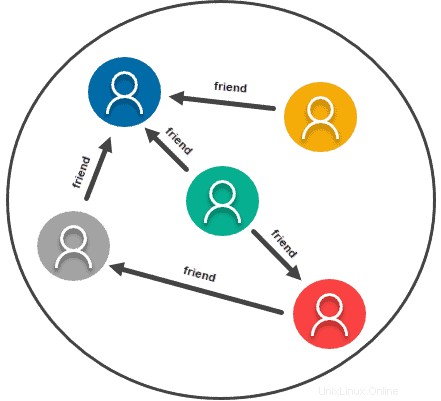
Magasin basé sur les graphiques
Les modèles de données de graphe ou de réseau traitent essentiellement la relation entre deux éléments d'information comme étant tout aussi importants que l'information elle-même. En tant que tel, ce type de modèle de données est vraiment conçu pour toutes les informations que vous représenteriez habituellement sur un graphique. Il utilise des relations et des nœuds, les données étant les informations elles-mêmes, et la relation est formée entre les nœuds.
Comment les données sont-elles stockées dans NoSQL ?
Le stockage de données NoSQL dépend du type de base de données que vous utilisez. Étant donné que NoSQL ne nécessite pas de schéma, il n'y a pas de modèle sur la façon dont les données doivent être stockées, et varie donc entre les bases de données.
Généralement, le stockage de données NoSQL fonctionne de deux manières :
- Sur disque à l'aide de B-Trees , le haut étant en permanence dans la RAM.
- En mémoire où tout est sur la RAM à l'aide de RB-Trees et tout ce qui est stocké sur le disque n'est qu'un ajout.
Conception de schéma pour NoSQL
Étant donné que les bases de données NoSQL n'ont pas vraiment de structure définie, le développement et la conception de schémas ont tendance à se concentrer sur le modèle de données physique. Cela signifie développer pour de grands environnements étendus horizontalement, ce dans quoi NoSQL excelle. Par conséquent, les bizarreries et les problèmes spécifiques liés à l'évolutivité sont au premier plan.
En tant que tel, la première étape consiste à définir les besoins de l'entreprise, car l'optimisation de l'accès aux données est indispensable et ne peut être obtenue qu'en sachant ce que l'entreprise veut à voir avec les données. La conception de votre schéma doit compléter les workflows liés à votre cas d'utilisation.
Il existe plusieurs façons de sélectionner la clé primaire, et cela dépend finalement des utilisateurs eux-mêmes. Cela étant dit, certaines données pourraient suggérer un schéma plus efficace, notamment en termes de fréquence d'interrogation de ces données.
Techniques de modélisation de données NoSQL
Toutes les techniques de modélisation de données NoSQL sont regroupées en trois grands groupes :
- Techniques conceptuelles
- Techniques générales de modélisation
- Techniques de modélisation hiérarchique
Ci-dessous, nous discuterons brièvement de toutes les techniques de modélisation de données NoSQL.
Techniques conceptuelles
Il existe trois techniques conceptuelles pour la modélisation de données NoSQL :
- Dénormalisation . La dénormalisation est une technique assez courante et consiste à copier les données dans plusieurs tables ou formulaires afin de les simplifier. Avec la dénormalisation, regroupez facilement toutes les données qui doivent être interrogées en un seul endroit. Bien sûr, cela signifie que le volume de données augmente pour différents paramètres, ce qui augmente considérablement le volume de données.
- Agrégats . Cela permet aux utilisateurs de former des entités imbriquées avec des structures internes complexes, ainsi que de varier leur structure particulière. En fin de compte, l'agrégation réduit les jointures en minimisant les relations un à un.
La plupart des modèles de données NoSQL ont une certaine forme de cette technique de schéma souple. Par exemple, les bases de données de magasin de graphes et de valeurs-clés ont des valeurs qui peuvent être de n'importe quel format, puisque ces modèles de données n'imposent pas de contraintes sur la valeur. De même, un autre exemple tel que BigTable propose une agrégation via des colonnes et des familles de colonnes. - Jointures côté application. NoSQL ne prend généralement pas en charge les jointures, car les bases de données NoSQL sont orientées questions où les jointures sont effectuées au moment de la conception. Ceci est comparé aux bases de données relationnelles où sont effectuées au moment de l'exécution de la requête. Bien sûr, cela a tendance à entraîner une baisse des performances et est parfois inévitable.
Techniques générales de modélisation
Il existe cinq techniques générales pour la modélisation de données NoSQL :
- Clés énumérables . Pour la plupart, les valeurs de clé non ordonnées sont très utiles, car les entrées peuvent être partitionnées sur plusieurs serveurs dédiés en hachant simplement la clé. Même ainsi, l'ajout d'une certaine forme de fonctionnalité de tri via des clés ordonnées est utile, même si cela peut ajouter un peu plus de complexité et une baisse des performances.
- Réduction de dimensionnalité . Les systèmes d'information géographique ont tendance à utiliser R-Tree index et doivent être mis à jour sur place, ce qui peut être coûteux s'il s'agit de gros volumes de données. Une autre approche traditionnelle consiste à aplatir la structure 2D en une simple liste, comme ce qui se fait avec Geohash.
Avec la réduction de dimensionnalité, vous pouvez mapper des données multidimensionnelles à une simple valeur-clé ou même à des modèles non multidimensionnels.
Utilisez la réduction de dimensionnalité pour mapper des données multidimensionnelles à un modèle clé-valeur ou à un autre modèle non multidimensionnel. - Tableau d'index. Avec une table d'index, profitez des index dans les magasins qui ne les prennent pas nécessairement en charge en interne. Essayez de créer puis de maintenir une table unique avec des clés qui suivent un modèle d'accès spécifique. Par exemple, une table principale pour stocker les comptes d'utilisateurs pour un accès par ID utilisateur.
- Indice de clé composite . Bien qu'il s'agisse d'une technique un peu générique, les clés composites sont extrêmement utiles lorsque des clés ordonnées sont utilisées. Si vous le prenez et le combinez avec des clés secondaires, vous pouvez créer un index multidimensionnel assez similaire à la technique de réduction de dimensionnalité mentionnée ci-dessus.
- Recherche inversée – Agrégation directe. Le concept derrière cette technique est d'utiliser un index qui répond à un ensemble spécifique de critères, puis d'agréger ces données avec des analyses complètes ou une forme de représentation originale.
Il s'agit plus d'un modèle de traitement de données que d'une modélisation de données, mais les modèles de données sont certainement affectés par l'utilisation de ce type de modèle de traitement. Tenez compte du fait que la récupération aléatoire des enregistrements requis pour cette technique est inefficace. Utilisez le traitement des requêtes par lots pour atténuer ce problème.
Techniques de modélisation hiérarchique
Il existe sept techniques de modélisation hiérarchique pour les données NoSQL :
- Agrégation d'arborescence. L'agrégation d'arborescence consiste essentiellement à modéliser les données en un seul document. Cela peut être très efficace lorsqu'il s'agit de tout enregistrement auquel on accède toujours en même temps, comme un fil Twitter ou une publication Reddit. Bien sûr, le problème devient alors que l'accès aléatoire à toute entrée individuelle est inefficace.
- Listes de contiguïté. Il s'agit d'une technique simple où les nœuds sont modélisés comme des enregistrements indépendants de tableaux avec des ancêtres directs. C'est une façon compliquée de dire que cela vous permet de rechercher des nœuds par leurs parents ou leurs enfants. Tout comme l'agrégation d'arbres, il est également assez inefficace pour récupérer un sous-arbre entier pour un nœud donné.
- Chemins matérialisés. Cette technique est une sorte de dénormalisation et est utilisée pour éviter les parcours récursifs dans les structures arborescentes. Principalement, nous voulons attribuer les parents ou les enfants à chaque nœud, ce qui nous aide à déterminer les prédécesseurs ou descendants du nœud sans se soucier de la traversée. Incidemment, nous pouvons stocker des chemins matérialisés en tant qu'ID, soit sous forme d'ensemble, soit sous forme de chaîne unique.
- Ensembles imbriqués . Technique standard pour les structures arborescentes dans les bases de données relationnelles, elle s'applique tout aussi bien au NoSQL qu'aux bases de données clé-valeur ou document. L'objectif est de stocker les feuilles de l'arbre sous forme de tableau, puis de mapper chaque nœud non-feuille sur une plage de feuilles à l'aide d'index de début/fin.
Le modéliser de cette manière est un moyen efficace de traiter des données immuables car il ne nécessite qu'une petite quantité de mémoire et n'a pas nécessairement besoin d'utiliser des traversées. Cela étant dit, les mises à jour sont coûteuses car elles nécessitent des mises à jour des index. - Aplatissement des documents imbriqués :noms de champs numérotés. La plupart des moteurs de recherche ont tendance à travailler avec des documents qui sont une liste plate de champs et de valeurs, plutôt que quelque chose avec une structure interne complexe. En tant que telle, cette technique de modélisation des données tente de mapper ces structures complexes à un document simple, par exemple, en mappant des documents avec une structure hiérarchique, une difficulté courante que vous pourriez rencontrer.
Bien sûr, ce type de travail est fastidieux et difficilement évolutif, d'autant plus que les structures imbriquées augmentent. - Aplatissement des documents imbriqués :requêtes de proximité. Une façon de résoudre les problèmes potentiels liés à la technique de modélisation des données des noms de champs numérotés consiste à utiliser une technique similaire appelée Requêtes de proximité. Celles-ci limitent la distance entre les mots d'un document, ce qui permet d'augmenter les performances et de réduire l'impact sur la vitesse des requêtes.
- Traitement de graphes par lots. Le traitement de graphes par lots est une excellente technique pour explorer les relations vers le haut ou vers le bas pour un nœud, en quelques étapes. C'est un processus coûteux et qui n'évolue pas nécessairement très bien. En utilisant Message Passing et MapReduce, nous pouvons effectuer ce type de traitement de graphe.