Des outils comme sed (éditeur de flux) et grep (impression d'expressions régulières globales) sont de puissants moyens de gagner du temps et d'accélérer votre travail. Avant d'approfondir les cas d'utilisation, je voudrais expliquer brièvement les expressions régulières (regex), qui sont nécessaires pour la manipulation de texte que nous ferons plus tard.
Que sont les expressions régulières ? Lorsque nous traitons des fichiers journaux, des fichiers texte ou un morceau de code, nous
besoin de comprendre que tous ces éléments sont constitués de caractères. Lorsque la longueur du fichier est importante, il devient nécessaire de filtrer certains modèles afin de faciliter votre débogage. Vous trouverez des exemples d'expressions régulières tout au long de ces cas d'utilisation.
Groupe 1 :données du serveur
Disons que vous avez un fichier qui a une occurrence d'une chaîne :
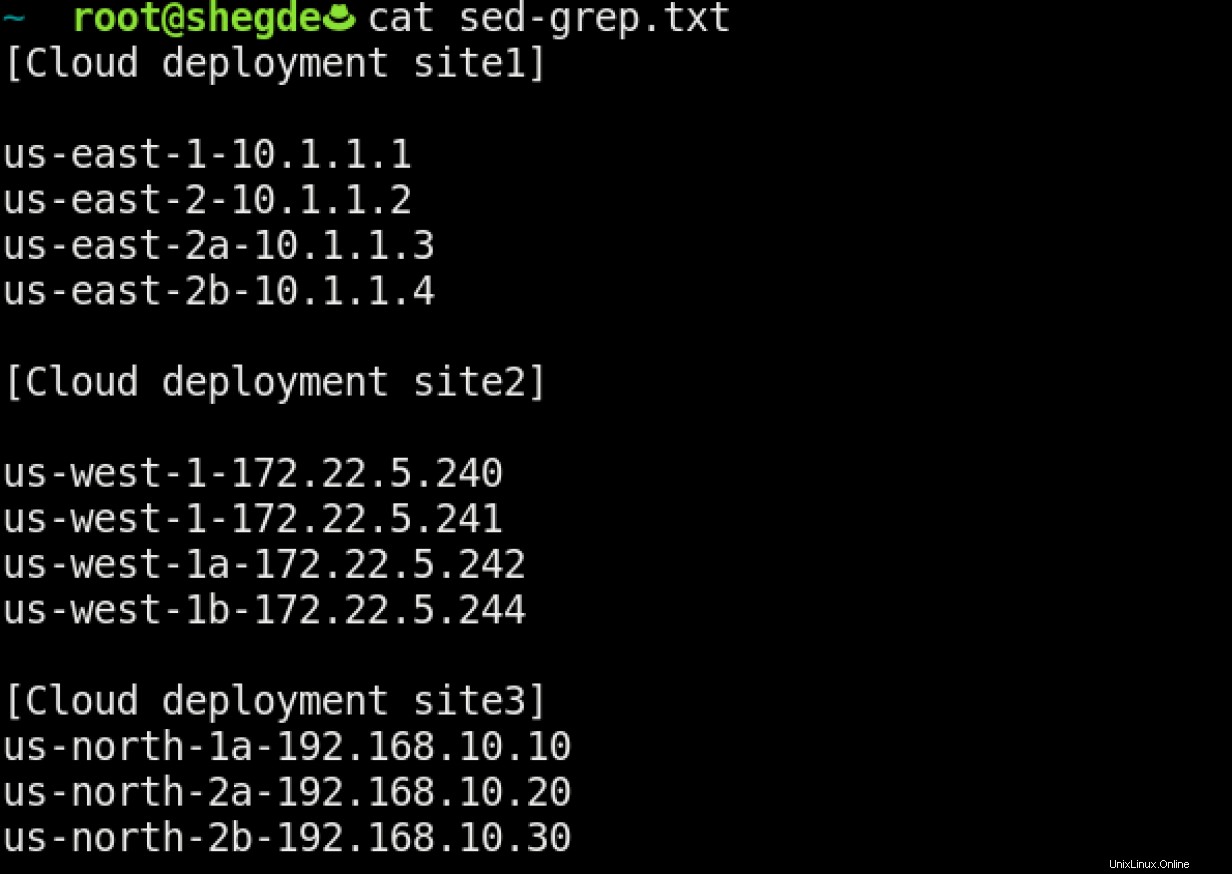
Maintenant, comment filtrez-vous site1 (le fichier ci-dessus est un exemple simple), de sorte que vous ne puissiez saisir que les informations nécessaires et manipuler les entrées ?
De toute évidence, nous pouvons voir qu'il existe un modèle commun ("déploiement Cloud") dans tout le fichier. Donc, nous pouvons maintenant utiliser des techniques de filtrage pour récupérer les informations du fichier en utilisant grep . Je me souviens de cela comme "get regex n print."
Cas d'utilisation 1
Si je veux les serveurs de différentes régions, je peux utiliser grep comme suit :
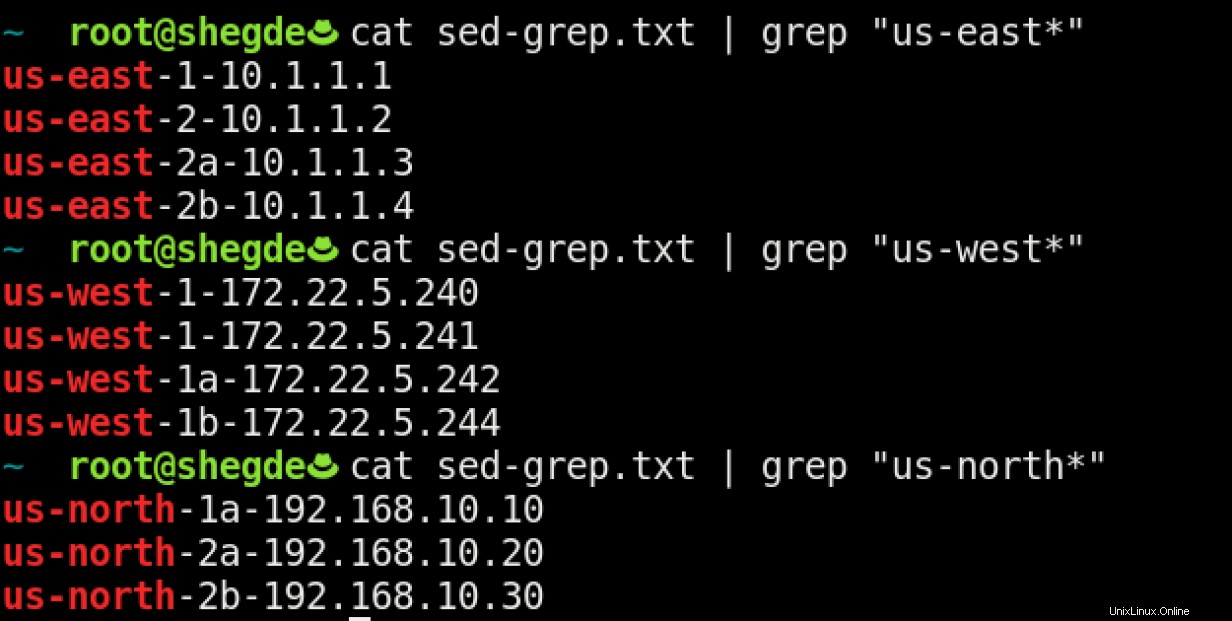
Cas d'utilisation 2
Maintenant, disons que vous savez que vous voulez filtrer les serveurs sur la base de l'IP. Vous pouvez faire la même chose en utilisant :
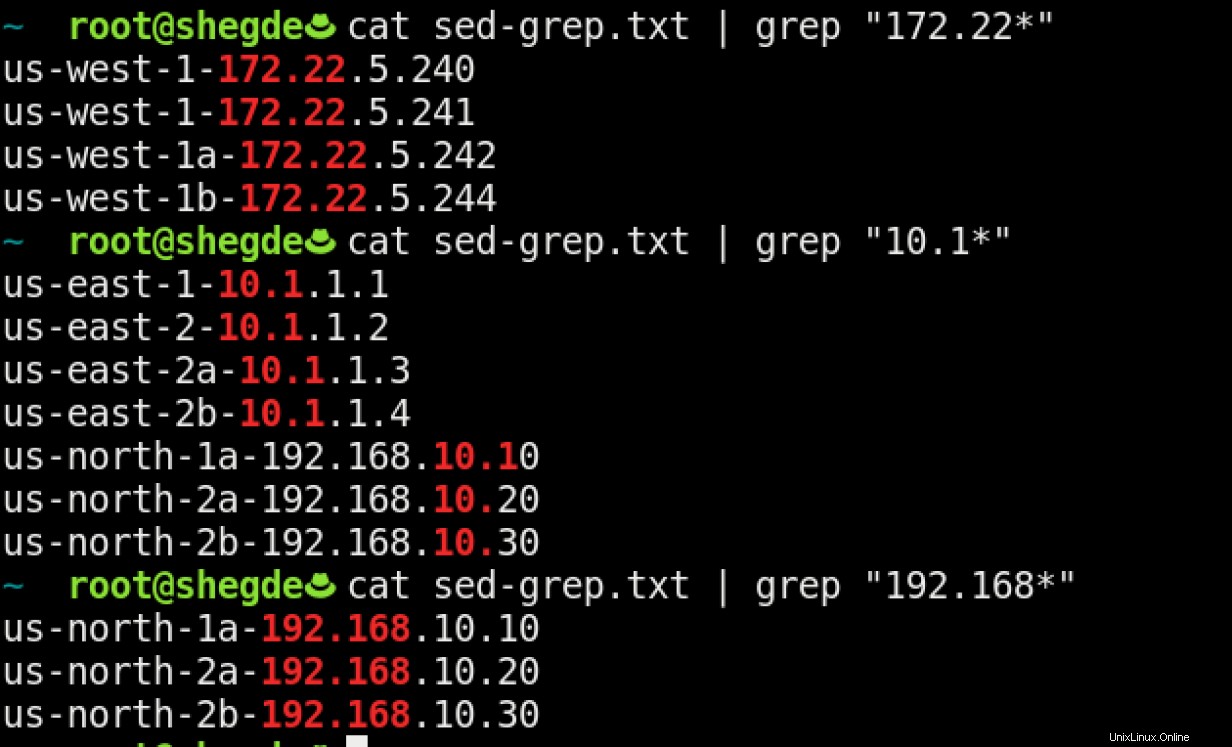
Cas d'utilisation 3
Maintenant, jetez un oeil au premier grep image de commande. Même si vous connaissiez la plage de sous-réseaux de votre système, la commande a imprimé l'occurrence de 10.1 dans tout le fichier.
Comment pouvez-vous résoudre ce type de cas d'utilisation ? Nous pouvons gérer ce problème en utilisant un filtrage avancé basé sur les expressions régulières, comme ceci :
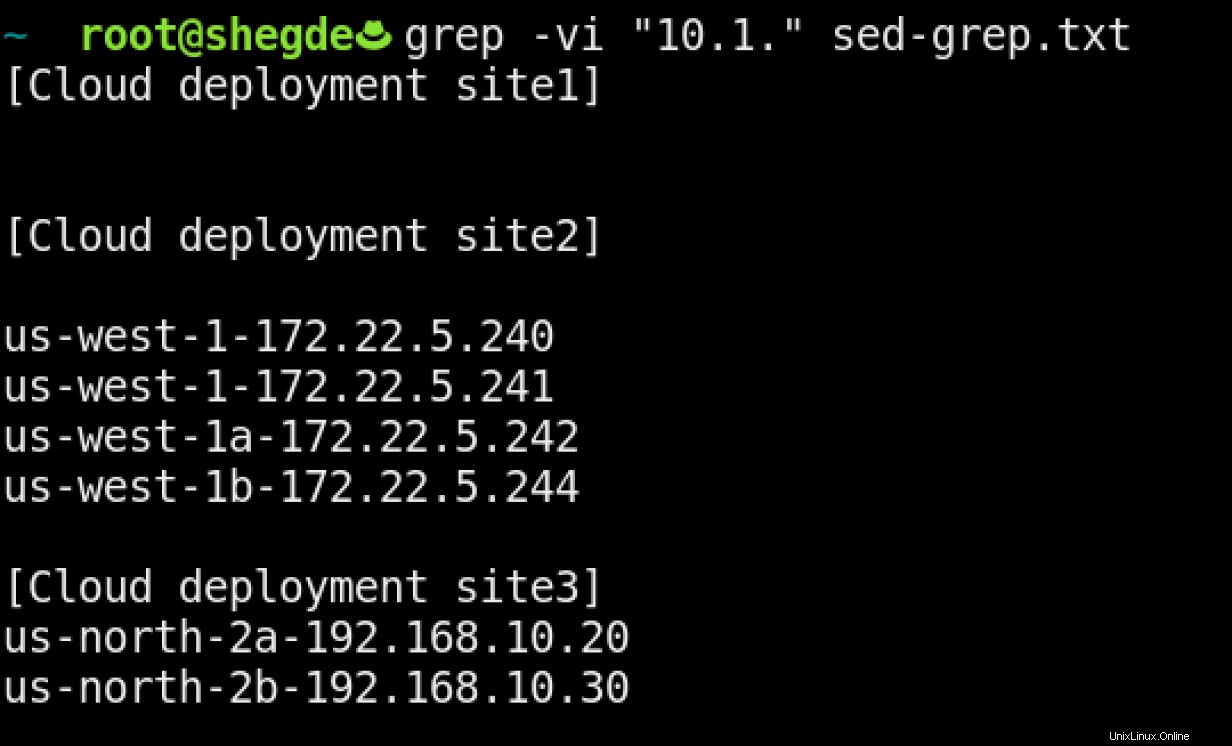
Cet exemple est juste une utilisation possible de grep . Encore une fois, comme il s'agit d'un fichier relativement petit, vous pouvez obtenir ce que vous voulez en utilisant ce qui est montré ci-dessus. Le -v switch inverse les critères de recherche, ce qui signifie que grep recherche le fichier sed-grep.txt et imprime tous les détails, à l'exception du <search-pattern> (10.1. dans ce cas).
Cas d'utilisation 4
Supposons que vous souhaitiez remplacer les adresses IP et déplacer tous les serveurs de ces régions vers un autre sous-réseau. Vous pouvez utiliser sed pour ce cas d'utilisation.
Depuis la page de manuel, sed utilise le format :
sed [options] commands [file-to-edit]
Notre commande pour ce cas d'utilisation pourrait ressembler à ceci :
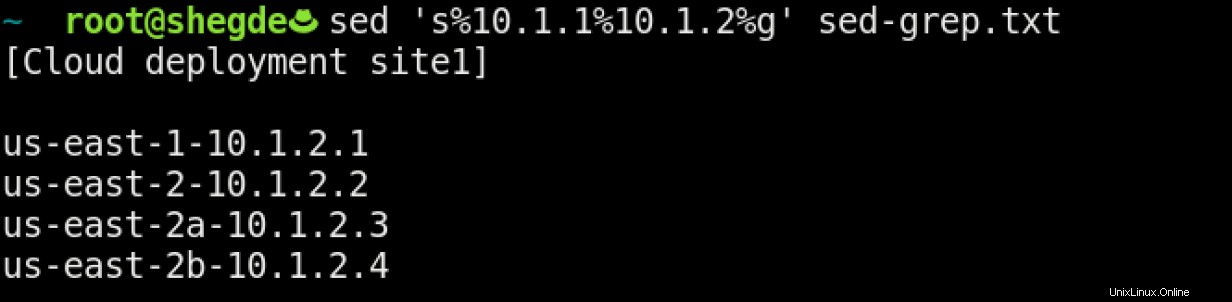
Cette commande se décompose comme suit :
- Les
ssignifie substitut. - Le
%est un délimiteur (nous pouvons utiliser n'importe quel caractère ici). - Le
<search pattern>apparaît après le premier%. - Le
<replace pattern>apparaît après le deuxième%. - Le
gsignifie remplacement global (c'est-à-dire dans tout le fichier).
Ou :
s%<search-pattern>%<replace-pattern>%g
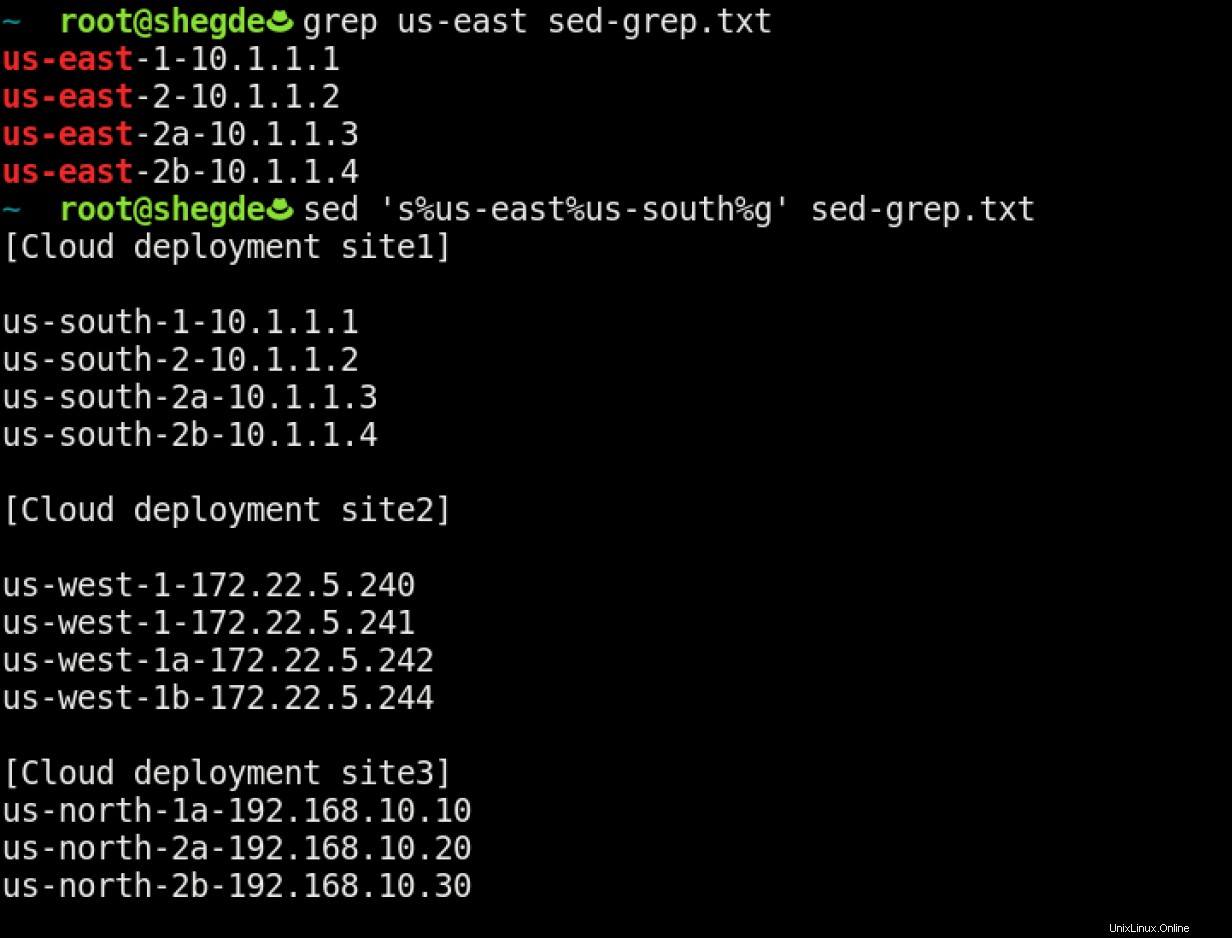
Cas d'utilisation 5
Vous pouvez même changer les régions des serveurs dans le fichier :
Cas d'utilisation 6
Ce cas d'utilisation est plus avancé. Nous ne supprimerons que les commentaires (# ) à partir d'un fichier utilisant sed :
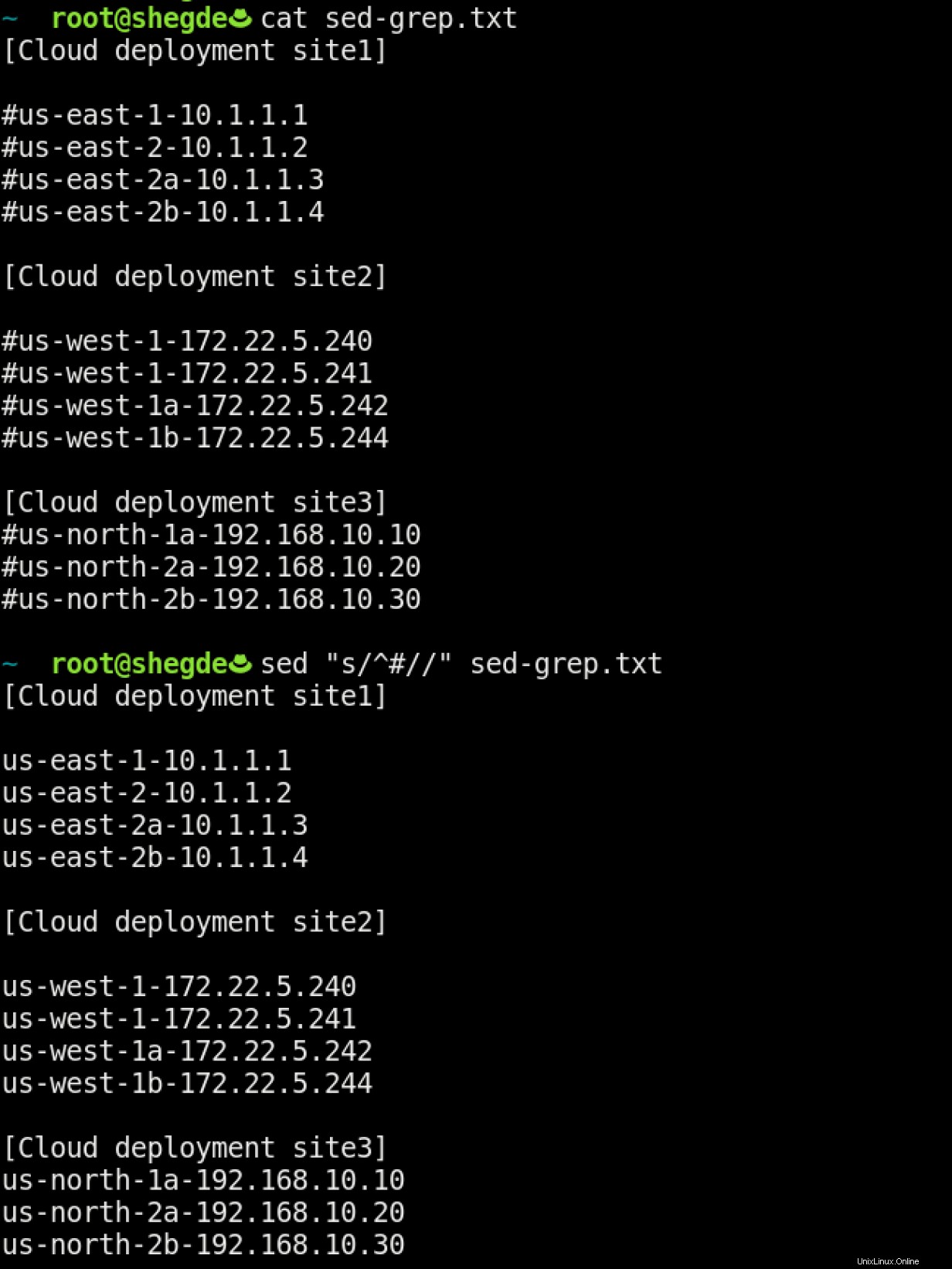
Cette commande dit que si # apparaît comme le premier caractère d'une ligne, pour remplacer cette ligne par un espace vide. Par conséquent, cette commande supprime les commentaires du fichier.
Groupe 2 :/etc/passwd
Examinons d'autres cas d'utilisation, cette fois impliquant /etc/passwd .
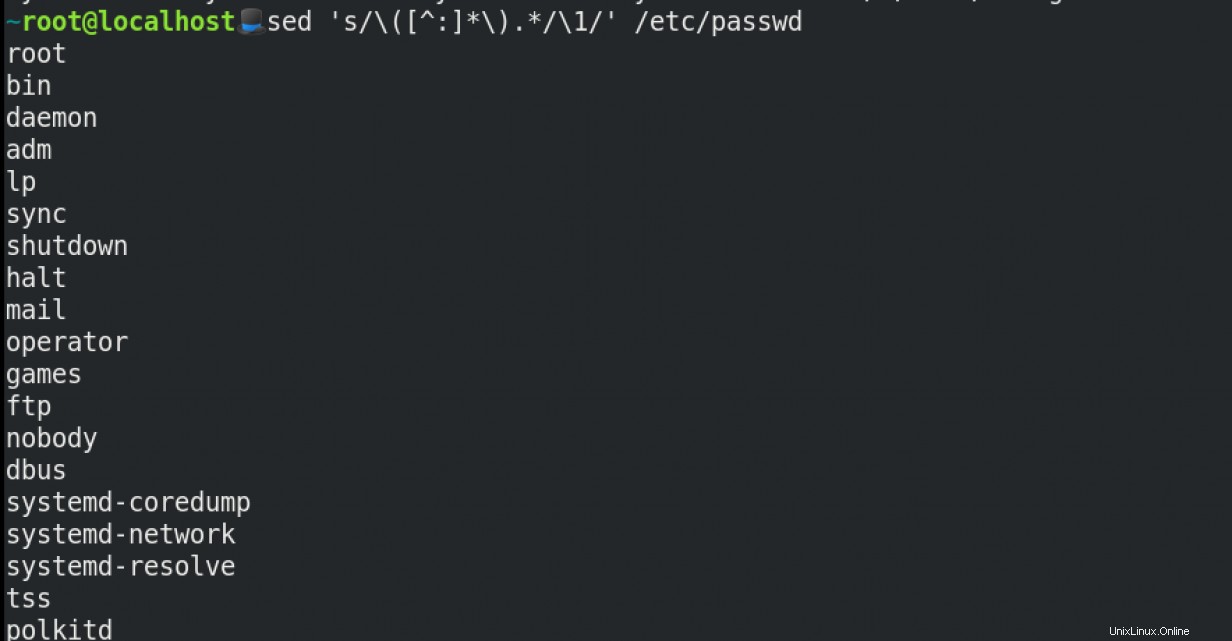
Cas d'utilisation 1
Supposons que vous souhaitiez récupérer les utilisateurs du fichier /etc/passwd dossier. Vous pouvez utiliser sed comme suit :
Cas d'utilisation 2
Et si vous ne voulez récupérer que les 10 premiers utilisateurs de /etc/passwd ? Vous pouvez utiliser sed et awk à cette fin (veuillez être patient avec moi ici) :
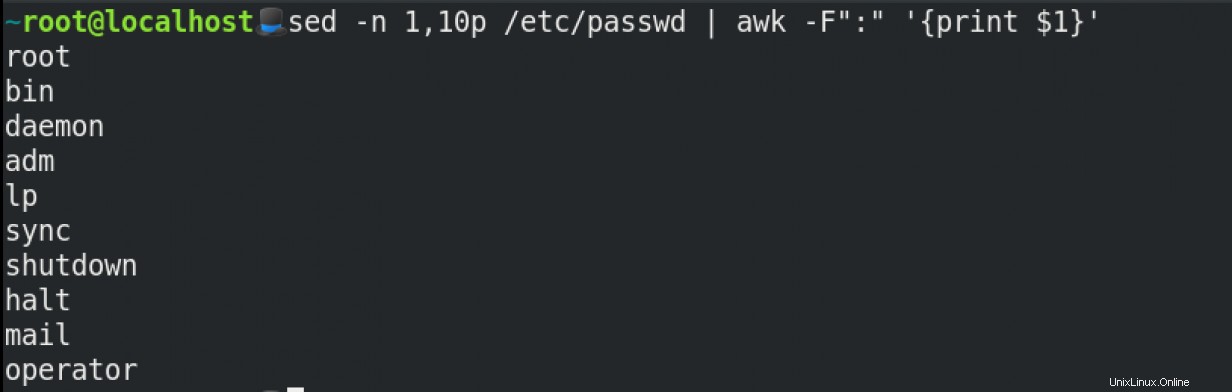
Cette commande se décompose en :
sed -nsignifie ne pas tout imprimer.pimprime les lignes 1 à 10.awkici utilise:comme séparateur de champs et imprime la première colonne.
Cas d'utilisation 3
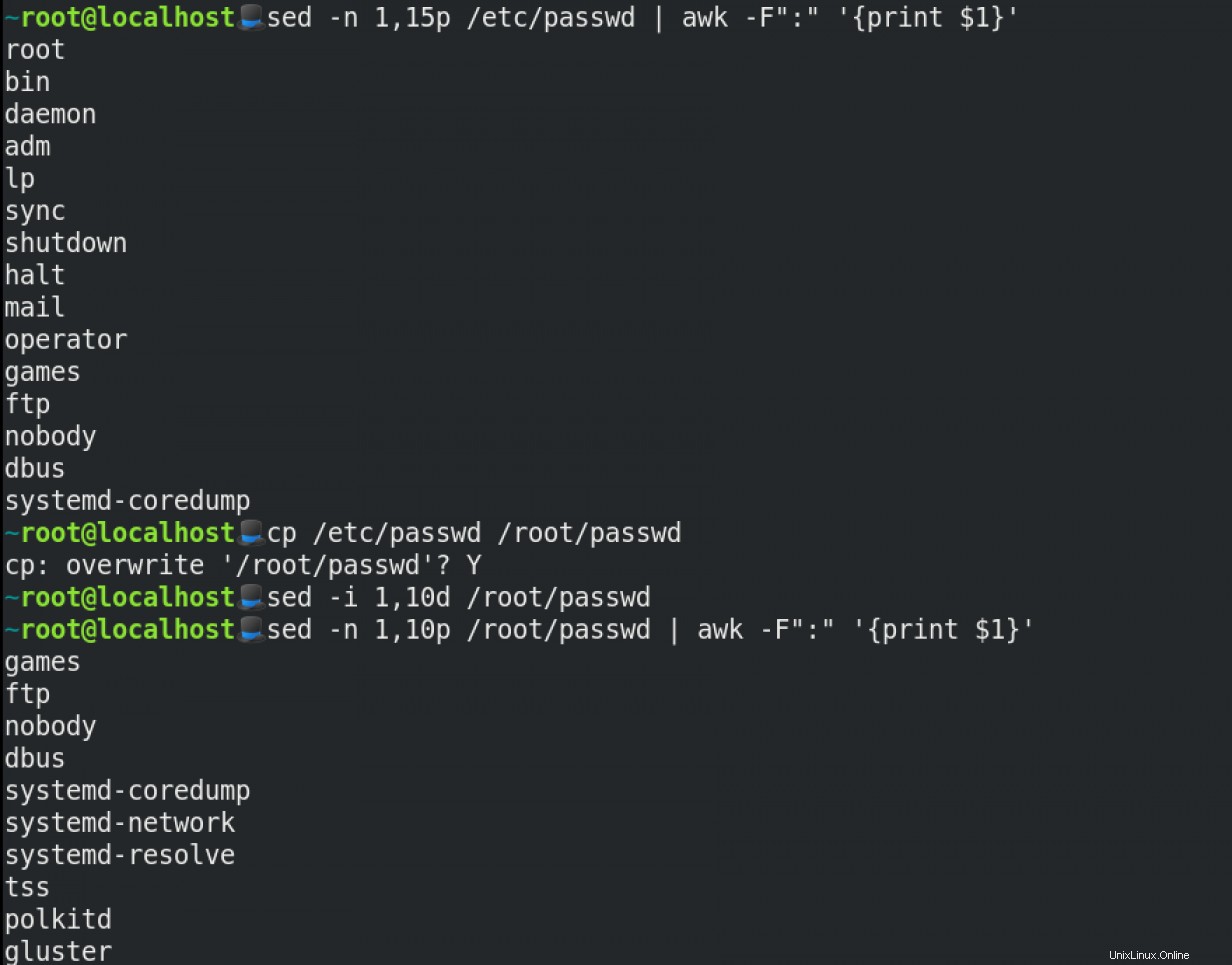
Supprimer une plage particulière de lignes dans des fichiers texte à l'aide de sed :
Cas d'utilisation SELinux
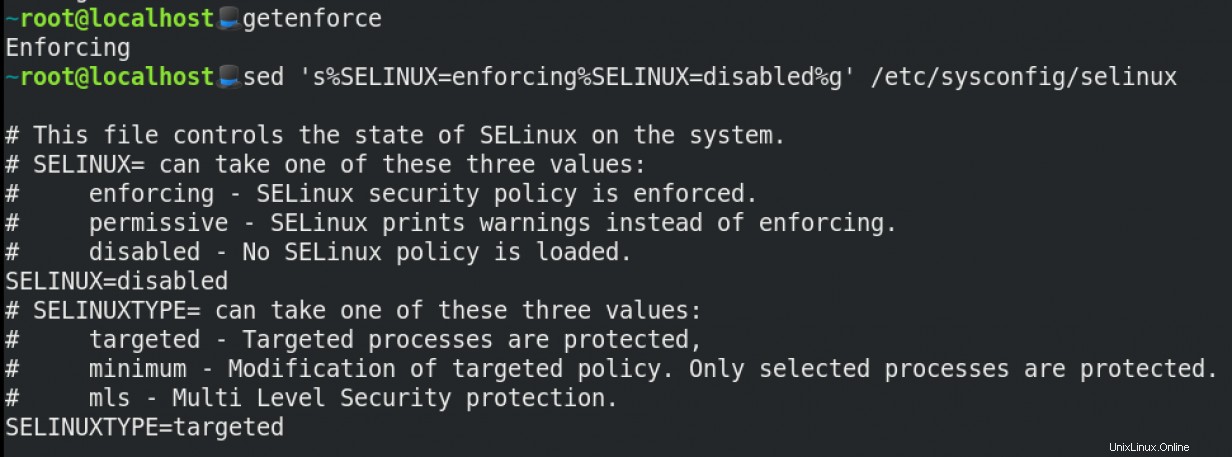
Voici un exemple sed commande pour manipuler SELinux :
Conclusion
Ceci est ma tentative de vous donner aux lecteurs un aperçu des possibilités d'utilisation de sed et grep . Vous pouvez effectuer de nombreuses manipulations de texte à l'aide de ces commandes. Reportez-vous aux différentes options à l'aide de la page de manuel pour en savoir plus.
[Vous voulez essayer Red Hat Enterprise Linux ? Téléchargez-le maintenant gratuitement.]