Un utilisateur expérimenté de Linux sait exactement quel genre de lignes vides gênantes peuvent se trouver dans un fichier exploitable. Ces lignes vides/vides entravent non seulement le traitement correct de ces fichiers, mais rendent également difficile la lecture et l'écriture du fichier par un programme en cours d'exécution.
Sur un environnement de système d'exploitation Linux, il est possible d'implémenter plusieurs expressions de manipulation de texte pour se débarrasser de ces lignes vides/blanches d'un fichier. Dans cet article, les lignes vides/blanches font référence aux caractères d'espacement.
Créer un fichier avec des lignes vides/vides sous Linux
Nous devons créer un fichier de référence avec des lignes vides/vides. Nous le modifierons plus tard dans l'article à travers plusieurs techniques dont nous parlerons. Depuis votre terminal, créez un fichier texte de votre choix avec un nom comme "i_have_blanks " et remplissez-le avec des données et des espaces vides.
$ nano i_have_blanks.txt Or $ vi i_have_blanks.txt
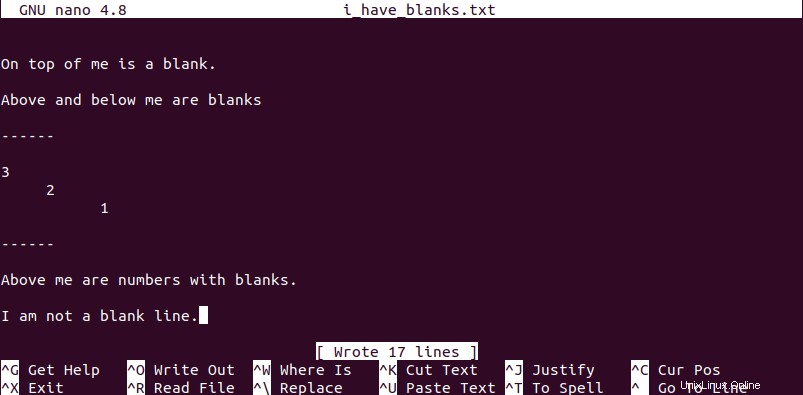
Tout au long de l'article, nous afficherons le contenu d'un fichier sur notre terminal en utilisant la commande cat pour un référencement flexible.
$ cat i_have_blanks.txt

Les trois commandes Linux qui nous propulseront vers une solution idéale à ce problème de lignes vides/vides sont grep, sed et awk .
Par conséquent, créez trois copies de votre i_have_blanks.txt fichier et enregistrez-les sous des noms différents afin que chacun puisse être pris en charge par l'une des trois commandes Linux indiquées.
Via regex (expressions régulières ), nous pouvons identifier les lignes vides avec le caractère standard POSIX “[:space:]” .
Comment supprimer les lignes vides/vides dans les fichiers
Avec cet énoncé de problème, nous envisageons l'élimination de toutes les lignes vides/vides existantes d'un fichier lisible donné à l'aide des commandes suivantes.
1. Supprimer les lignes vides à l'aide de la commande Grep
L'utilisation prise en charge des classes de caractères abrégés peut réduire la commande grep à une commande simple comme :
$ grep -v '^[[:space:]]*$' i_have_blanks.txt OR $ grep '\S' i_have_blanks.txt
Pour corriger un fichier avec des lignes vides/vides, la sortie ci-dessus doit passer par un fichier temporaire avant d'écraser le fichier d'origine.
$ grep '\S' i_have_blanks.txt > tmp.txt $ mv tmp.txt i_have_blanks.txt $ cat i_have_blanks.txt

Comme vous pouvez le voir, toutes les lignes vides qui espacaient le contenu de ce fichier texte ont disparu.
2. Supprimer les lignes vides à l'aide de la commande Sed
Le d l'action dans la commande lui dit de supprimer tout espace blanc existant d'un fichier. Le mécanisme de correspondance et de suppression des lignes vides de cette commande peut être représenté de la manière suivante.
$ sed '/^[[:space:]]*$/d' i_have_blanks_too.txt
La commande ci-dessus parcourt les lignes du fichier texte à la recherche de caractères non vides et supprime tous les autres caractères restants. Grâce à sa prise en charge des classes de caractères non vides, la commande ci-dessus peut être simplifiée comme suit :
$ sed '/\S/!d' i_have_blanks_too.txt
De plus, en raison de la prise en charge de l'édition sur place de la commande, nous n'avons pas besoin d'un fichier temporaire pour conserver temporairement notre fichier converti avant d'écraser le fichier texte d'origine comme dans le cas de la commande grep. Vous devez cependant utiliser cette commande avec un -i option comme argument.
$ sed -i '/\S/!d' i_have_blanks_too.txt i_have_blanks_too.txt $ cat i_have_blanks_too.txt
3. Supprimer les lignes vides à l'aide de la commande Awk
La commande awk exécute une vérification des caractères non blancs sur chaque ligne d'un fichier et ne les imprime que si cette condition est vraie. La flexibilité de cette commande s'accompagne de divers itinéraires d'implémentation. Sa solution simple est la suivante :
$ awk '!/^[[:space:]]*$/' i_have_blanks_first.txt
L'interprétation de la commande ci-dessus est simple, seules les lignes de fichier qui n'existent pas en tant qu'espaces blancs sont imprimées. La version longue de la commande ci-dessus ressemblera à ceci :
$ awk '{ if($0 !~ /^[[:space:]]*$/) }' i_have_blanks_first.txt
Grâce à awk prise en charge de la classe de caractères non vides, la commande ci-dessus peut également être représentée de la manière suivante :
$ awk -d '/\S/' i_have_blanks_first.txt
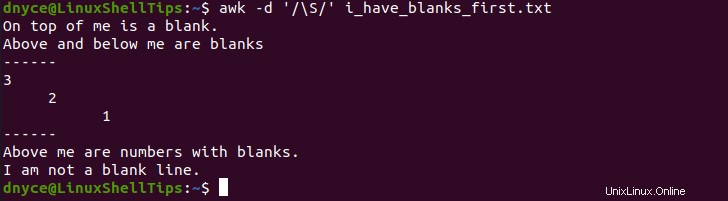
Le -d une option permet de awk vider les lignes finales du fichier sur le terminal système. Comme vous pouvez le voir, le fichier n'a plus d'espaces blancs.
Les trois ont discuté et mis en œuvre des solutions pour traiter les lignes vides des fichiers via grep , sed , et awk nous permettront d'implémenter des opérations de lecture et d'écriture de fichiers stables et efficaces sur un système Linux.