Imaginez que vous avez un fichier (ou un groupe de fichiers) et que vous souhaitez rechercher une chaîne ou un paramètre de configuration spécifique dans ces fichiers. Ouvrir chaque fichier individuellement et essayer de trouver la chaîne spécifique serait fastidieux et n'est probablement pas la bonne approche. Alors, que pouvons-nous utiliser ?
Il existe de nombreux outils que nous pouvons utiliser dans les systèmes basés sur *nix pour rechercher et manipuler du texte. Dans cet article, nous aborderons le grep commande pour rechercher des modèles, qu'ils soient trouvés dans des fichiers ou provenant d'un flux (un fichier ou une entrée provenant d'un tube, ou | ). Dans un prochain article, nous verrons également comment utiliser sed (Stream Editor) pour manipuler un flux.
La meilleure façon de comprendre le fonctionnement d'un programme ou d'un utilitaire est de consulter sa page de manuel. De nombreux outils Unix (sinon tous) fournissent des pages de manuel lors de l'installation. Sur les systèmes basés sur Red Hat Enterprise Linux, nous pouvons exécuter ce qui suit pour répertorier grep Fichiers de documentation :
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
Avec les pages de manuel à notre disposition, nous pouvons maintenant utiliser grep et explorez ses options.
grep bases
Dans cette partie de l'article, nous utilisons les words fichier, que vous pouvez trouver à l'emplacement suivant :
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
Ce fichier contient 479 826 mots et est fourni par les words emballer. Dans mon système Fedora, ce paquet est words-3.0-33.fc30.noarch . Lorsque nous listons le contenu des words fichier, nous voyons la sortie suivante :
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Ok, donc nous avons dit les words le fichier contenait 479 826 lignes, mais comment le savons-nous ? Rappelez-vous, nous avons parlé des pages de manuel plus tôt. Voyons si grep offre une option pour compter les lignes dans un fichier donné.
Ironiquement, nous utiliserons grep grep pour l'option comme suit :

Donc, nous avons évidemment besoin de -c , ou l'option longue --count , pour compter le nombre de lignes dans un fichier donné. Compter les lignes dans /usr/share/dict/words donne :
$ grep -c '.' /usr/share/dict/words
479826
Le '.' signifie que l'on comptera toutes les lignes contenant au moins un caractère, espace, blanc, tabulation, etc.
Basic grep expressions régulières
Le grep La commande devient plus puissante lorsque nous utilisons des expressions régulières (regexes). Donc, pendant que nous nous concentrons sur le grep commande elle-même, nous aborderons également la syntaxe de base des expressions régulières.
Supposons que seuls les mots commençant par Z nous intéressent . C'est dans cette situation que les expressions régulières sont utiles. Nous utilisons le carat (^ ) pour rechercher des motifs commençant par un caractère spécifique, indiquant le début d'une chaîne :
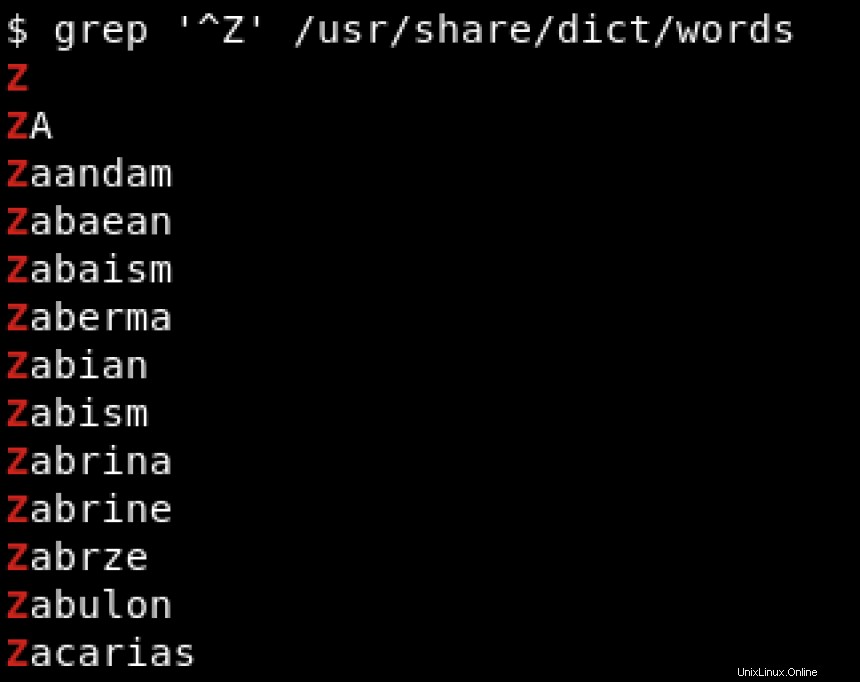
Pour rechercher des modèles se terminant par un caractère spécifique, nous utilisons le signe dollar ($ ) pour indiquer la fin de la chaîne. Voir l'exemple ci-dessous où nous recherchons des chaînes se terminant par hat :
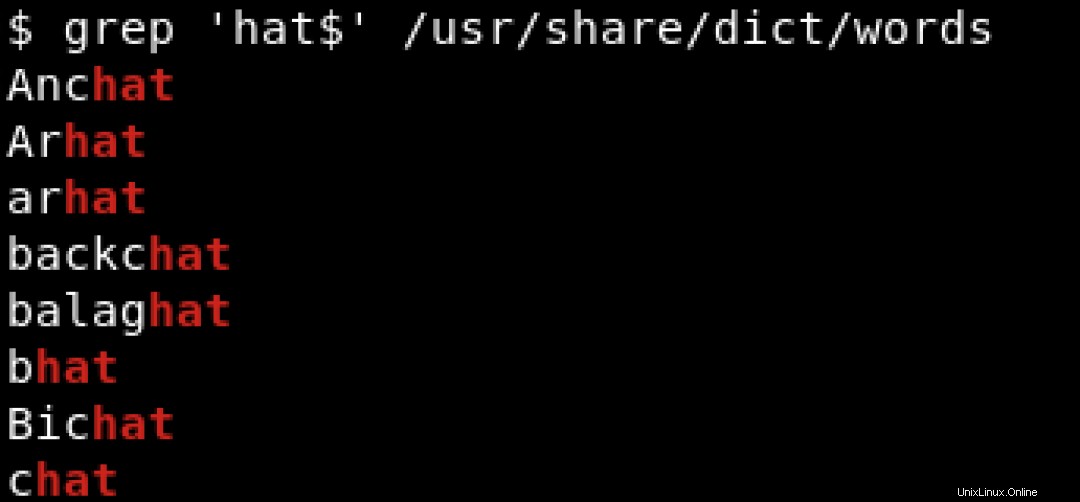
Pour imprimer toutes les lignes contenant hat quelle que soit sa position, que ce soit au début ou à la fin de la ligne, nous utiliserions quelque chose comme :
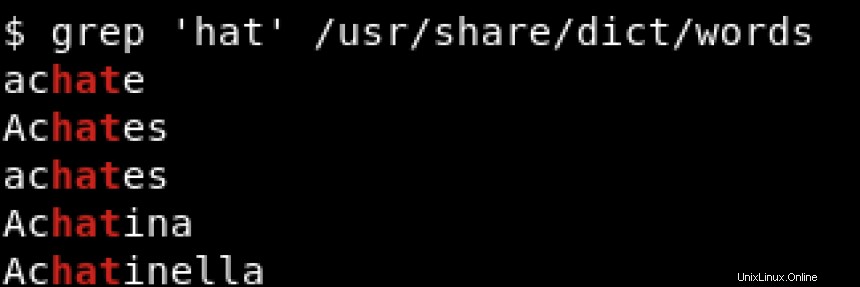
Le ^ et $ sont appelés métacaractères et doivent être précédés d'une barre oblique inverse (\ ) lorsque nous voulons faire correspondre ces caractères littéralement. Si vous souhaitez en savoir plus sur les métacaractères, consultez https://www.regular-expressions.info/characters.html.
Exemple :Supprimer des commentaires
Maintenant que nous avons gratté la surface de grep , travaillons sur des scénarios réels. De nombreux fichiers de configuration dans *nix contiennent des commentaires décrivant différents paramètres dans le fichier de configuration. Le /etc/fstab , fichier par exemple, a :
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
Les commentaires sont marqués par le hash (# ), et nous voulons les ignorer lors de l'impression. Une option est le cat commande :
$ cat /etc/fstab | grep -v '^#'
Cependant, vous n'avez pas besoin de cat ici (évitez l'utilisation inutile du chat). Le grep est parfaitement capable de lire des fichiers, donc à la place, vous pouvez utiliser quelque chose comme ceci pour ignorer les lignes qui contiennent des commentaires :
$ grep -v '^#' /etc/fstab
Si vous souhaitez envoyer la sortie (sans commentaires) vers un autre fichier à la place, vous utiliserez :
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Tandis que grep peut formater la sortie à l'écran, cette commande est incapable de modifier un fichier en place. Pour ce faire, nous aurions besoin d'un éditeur de fichiers comme ed . Dans le prochain article, nous utiliserons sed pour obtenir la même chose que nous avons fait ici avec grep .
Exemple :Supprimer les commentaires et les lignes vides
Pendant que nous sommes encore sur grep , examinons le /etc/sudoers dossier. Ce fichier contient de nombreux commentaires, mais nous ne nous intéressons qu'aux lignes qui n'ont pas de commentaires, et nous voulons également nous débarrasser des lignes vides.
Donc, d'abord, supprimons les lignes contenant les commentaires. La sortie suivante est produite :
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Maintenant, nous voulons nous débarrasser des lignes vides (vides). Eh bien, c'est facile, lancez simplement un autre grep commande :
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Peut-on faire mieux ? Pourrions-nous exécuter notre grep commande pour être plus conviviale pour les ressources et ne pas bifurquer grep à deux reprises? Nous pouvons certainement :
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Ici, nous avons introduit un autre grep option, -E (ou --extended-regexp ) <PATTERN> est une expression régulière étendue.
Exemple :Imprimer uniquement /etc/passwd utilisateurs
Il est évident que grep est puissant lorsqu'il est utilisé avec des regex. Cet article ne couvre qu'une petite partie de ce que grep est vraiment capable de. Pour démontrer les capacités de grep et l'utilisation d'expressions régulières, nous analyserons le /etc/passwd classer et imprimer uniquement les noms d'utilisateur.
Le format du /etc/passwd fichier est le suivant :
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Les champs ci-dessus ont la signification suivante :
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Voir man 5 passwd pour plus d'informations sur le /etc/passwd dossier. Pour imprimer uniquement les noms d'utilisateur, nous pourrions utiliser quelque chose comme ceci :
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
Dans le grep ci-dessus commande, nous avons introduit une autre option :-o (ou --only-matching ) pour afficher uniquement la partie d'une ligne correspondant à <PATTERN> . Ensuite, nous avons combiné -Eo pour obtenir le résultat souhaité.
Nous allons maintenant décomposer la commande ci-dessus afin de mieux comprendre ce qui se passe réellement. De gauche à droite :
^correspond au début de la ligne.[a-zA-Z_-]est appelée une classe de caractères et correspond à un seul caractère correspondant à la liste incluse.+est un quantificateur qui correspond entre une et un nombre illimité de fois.
L'expression régulière ci-dessus se répétera jusqu'à ce qu'elle atteigne un caractère auquel elle ne correspond pas. La première ligne du fichier est :
root:x:0:0:root:/root:/bin/bash
Il est traité comme suit :
- Le premier caractère est un
r, donc il correspond à[a-z]. - Le
+passe au caractère suivant. - Le deuxième caractère est un
oet cela correspond à[a-z]. - Le
+passe au caractère suivant.
Cette séquence se répète jusqu'à ce que nous frappions les deux-points (: ). La classe de caractères [a-zA-Z_-] ne correspond pas au : symbole, donc grep passe à la ligne suivante.
Puisque les noms d'utilisateur dans le passwd fichier sont tous en minuscules, nous pourrions également simplifier notre classe de caractères comme suit, et toujours obtenir le résultat souhaité :
$ grep -Eo '^[a-z_-]+' /etc/passwd
Exemple :Rechercher un processus
Lors de l'utilisation de ps pour grep pour un processus, nous utilisons souvent quelque chose comme :
$ ps aux | grep ‘thunderbird’
Mais le ps la commande ne listera pas seulement le thunderbird processus. Il répertorie également le grep commande que nous venons d'exécuter également, depuis grep s'exécute également après le tube et s'affiche dans la liste des processus :
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Nous pouvons gérer cela en ajoutant grep -v grep pour exclure grep à partir de la sortie :
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Lors de l'utilisation de grep -v grep fera ce que nous voulions, de meilleurs moyens existent pour obtenir le même résultat sans créer un nouveau grep processus :
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Le [t]hunderbird correspond ici au littéral t , et est sensible à la casse. Il ne correspondra pas à grep , et c'est pourquoi nous ne voyons plus que thunderbird dans la sortie.
Cet exemple est juste une démonstration de la flexibilité de grep est, ne vous aidera pas à dépanner votre arborescence de processus. Il existe de meilleurs outils adaptés à cette fin, comme pgrep .
Conclusion
Utilisez grep lorsque vous souhaitez rechercher un motif, soit dans un fichier, soit dans plusieurs répertoires de manière récursive. Essayez de comprendre comment fonctionnent les expressions régulières lorsque grep , car les expressions régulières peuvent être puissantes.
[Vous voulez essayer Red Hat Enterprise Linux ? Téléchargez-le maintenant gratuitement.]