Hadoop est un framework logiciel gratuit, open source et basé sur Java utilisé pour le stockage et le traitement de grands ensembles de données sur des clusters de machines. Il utilise HDFS pour stocker ses données et traiter ces données à l'aide de MapReduce. Il s'agit d'un écosystème d'outils Big Data principalement utilisés pour l'exploration de données et l'apprentissage automatique.
Apache Hadoop 3.3 est livré avec des améliorations notables et de nombreuses corrections de bogues par rapport aux versions précédentes. Il comporte quatre composants principaux tels que Hadoop Common, HDFS, YARN et MapReduce.
Ce tutoriel vous expliquera comment installer et configurer Apache Hadoop sur le système Linux Ubuntu 20.04 LTS.
Étape 1 – Installation de Java
Hadoop est écrit en Java et ne prend en charge que la version 8 de Java. Hadoop version 3.3 et les dernières prennent également en charge l'environnement d'exécution Java 11 ainsi que Java 8.
Vous pouvez installer OpenJDK 11 à partir des dépôts apt par défaut :
sudo apt updatesudo apt install openjdk-11-jdk
Une fois installé, vérifiez la version installée de Java avec la commande suivante :
java -version
Vous devriez obtenir le résultat suivant :
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Étape 2 – Créer un utilisateur Hadoop
C'est une bonne idée de créer un utilisateur distinct pour exécuter Hadoop pour des raisons de sécurité.
Exécutez la commande suivante pour créer un nouvel utilisateur avec le nom hadoop :
sudo adduser hadoop
Fournissez et confirmez le nouveau mot de passe comme indiqué ci-dessous :
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Étape 3 – Configurer l'authentification basée sur une clé SSH
Ensuite, vous devrez configurer l'authentification SSH sans mot de passe pour le système local.
Tout d'abord, changez l'utilisateur en hadoop avec la commande suivante :
su - hadoop
Ensuite, exécutez la commande suivante pour générer des paires de clés publiques et privées :
ssh-keygen -t rsa
Il vous sera demandé d'entrer le nom du fichier. Appuyez simplement sur Entrée pour terminer le processus :
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
Ensuite, ajoutez les clés publiques générées de id_rsa.pub à authorized_keys et définissez l'autorisation appropriée :
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
Ensuite, vérifiez l'authentification SSH sans mot de passe avec la commande suivante :
ssh localhost
Il vous sera demandé d'authentifier les hôtes en ajoutant des clés RSA aux hôtes connus. Tapez yes et appuyez sur Entrée pour authentifier l'hôte local :
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Étape 4 – Installer Hadoop
Tout d'abord, changez l'utilisateur en hadoop avec la commande suivante :
su - hadoop
Ensuite, téléchargez la dernière version de Hadoop à l'aide de la commande wget :
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
Une fois téléchargé, extrayez le fichier téléchargé :
tar -xvzf hadoop-3.3.0.tar.gz
Ensuite, renommez le répertoire extrait en hadoop :
mv hadoop-3.3.0 hadoop
Ensuite, vous devrez configurer les variables d'environnement Hadoop et Java sur votre système.
Ouvrez le ~/.bashrc fichier dans votre éditeur de texte préféré :
nano ~/.bashrc
Ajoutez les lignes ci-dessous au fichier. Vous pouvez trouver l'emplacement JAVA_HOME en exécutant dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
Ensuite, ouvrez le fichier de variables d'environnement Hadoop :
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Définissez à nouveau JAVA_HOME dans l'environnement hadoop.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Enregistrez et fermez le fichier lorsque vous avez terminé.
Étape 5 - Configuration de Hadoop
Tout d'abord, vous devrez créer les répertoires namenode et datanode dans le répertoire d'accueil Hadoop :
Exécutez la commande suivante pour créer les deux répertoires :
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Ensuite, modifiez le core-site.xml fichier et mise à jour avec le nom d'hôte de votre système :
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Modifiez le nom suivant en fonction du nom d'hôte de votre système :
XHTML
| 123456 |
Enregistrez et fermez le fichier. Ensuite, modifiez le hdfs-site.xml fichier :
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Modifiez le chemin des répertoires NameNode et DataNode comme indiqué ci-dessous :
XHTML
| 1234567891011121314151617 |
Enregistrez et fermez le fichier. Ensuite, modifiez le mapred-site.xml fichier :
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Effectuez les modifications suivantes :
XHTML
| 123456 |
Enregistrez et fermez le fichier. Ensuite, modifiez le yarn-site.xml fichier :
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Effectuez les modifications suivantes :
XHTML
| 123456 |
Enregistrez et fermez le fichier lorsque vous avez terminé.
Étape 6 - Démarrer le cluster Hadoop
Avant de démarrer le cluster Hadoop. Vous devrez formater le Namenode en tant qu'utilisateur hadoop.
Exécutez la commande suivante pour formater le hadoop Namenode :
hdfs namenode -format
Vous devriez obtenir le résultat suivant :
2020-11-23 10:31:51,318 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-23 10:31:51,323 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-23 10:31:51,323 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.net/127.0.1.1 ************************************************************/
Après avoir formaté le Namenode, exécutez la commande suivante pour démarrer le cluster hadoop :
start-dfs.sh
Une fois que le HDFS a démarré avec succès, vous devriez obtenir le résultat suivant :
Starting namenodes on [hadoop.tecadmin.com] hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [hadoop.tecadmin.com]
Ensuite, démarrez le service YARN comme indiqué ci-dessous :
start-yarn.sh
Vous devriez obtenir le résultat suivant :
Starting resourcemanager Starting nodemanagers
Vous pouvez désormais vérifier l'état de tous les services Hadoop à l'aide de la commande jps :
jps
Vous devriez voir tous les services en cours d'exécution dans la sortie suivante :
18194 NameNode 18822 NodeManager 17911 SecondaryNameNode 17720 DataNode 18669 ResourceManager 19151 Jps
Étape 7 - Ajuster le pare-feu
Hadoop est maintenant démarré et écoute sur les ports 9870 et 8088. Ensuite, vous devrez autoriser ces ports à travers le pare-feu.
Exécutez la commande suivante pour autoriser les connexions Hadoop via le pare-feu :
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcp
Ensuite, rechargez le service firewalld pour appliquer les modifications :
firewall-cmd --reload
Étape 8 – Accéder au nœud de nom Hadoop et au gestionnaire de ressources
Pour accéder au Namenode, ouvrez votre navigateur Web et visitez l'URL http://your-server-ip:9870. Vous devriez voir l'écran suivant :
http://hadoop.tecadmin.net:9870
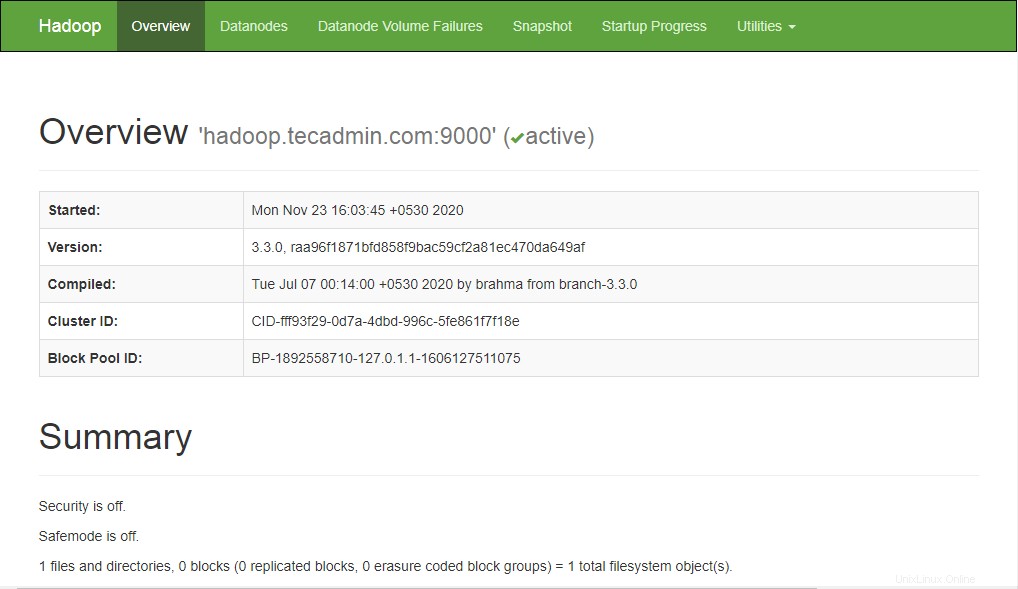
Pour accéder à Resource Manage, ouvrez votre navigateur Web et visitez l'URL http://your-server-ip:8088. Vous devriez voir l'écran suivant :
http://hadoop.tecadmin.net:8088
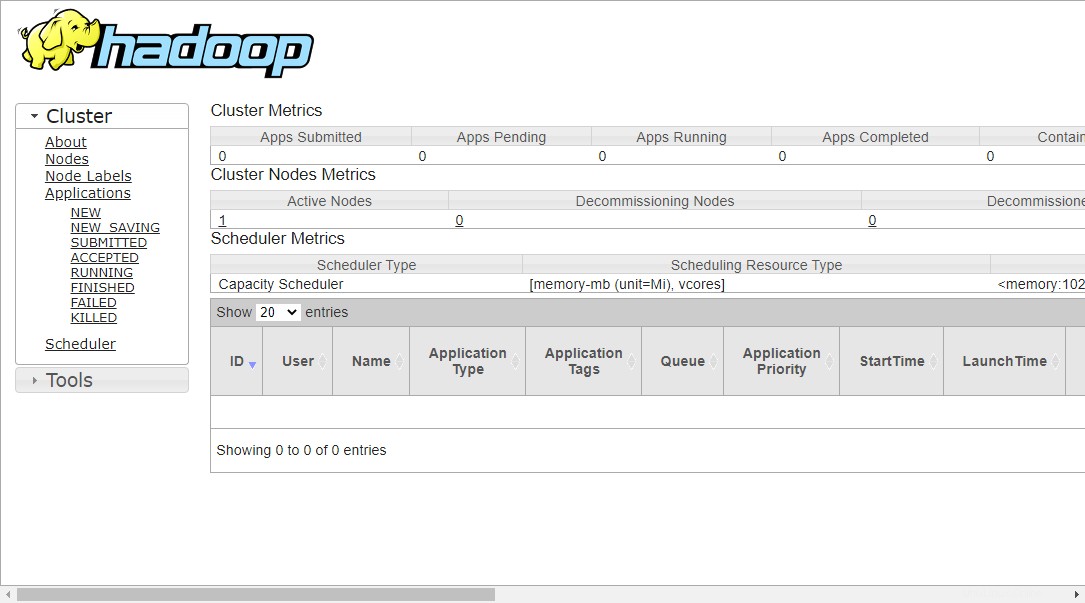
Étape 9 – Vérifier le cluster Hadoop
À ce stade, le cluster Hadoop est installé et configuré. Ensuite, nous allons créer des répertoires dans le système de fichiers HDFS pour tester Hadoop.
Créons un répertoire dans le système de fichiers HDFS en utilisant la commande suivante :
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
Ensuite, exécutez la commande suivante pour répertorier le répertoire ci-dessus :
hdfs dfs -ls /
Vous devriez obtenir le résultat suivant :
Found 3 items drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:56 /logs drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:51 /test1
En outre, placez certains fichiers dans le système de fichiers hadoop. Pour l'exemple, placer les fichiers journaux de la machine hôte dans le système de fichiers hadoop.
hdfs dfs -put /var/log/* /logs/
Vous pouvez également vérifier les fichiers et le répertoire ci-dessus dans l'interface Web Hadoop Namenode.
Allez sur l'interface web de Namenode, cliquez sur Utilities => Browse the file system. Vous devriez voir vos répertoires que vous avez créés précédemment dans l'écran suivant :
http://hadoop.tecadmin.net:9870/explorer.html
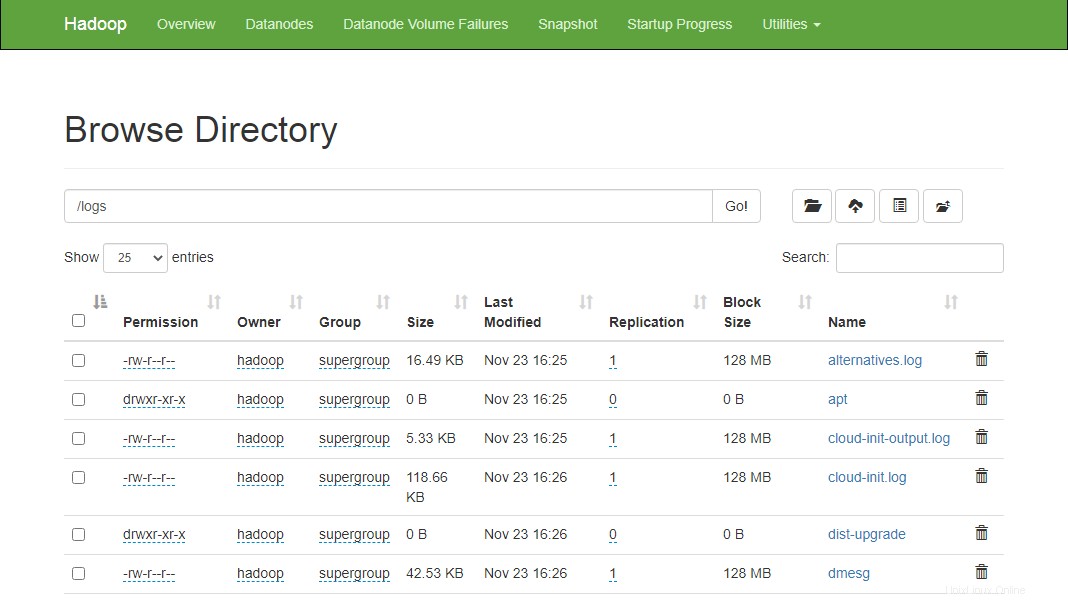
Étape 10 - Arrêter le cluster Hadoop
Vous pouvez également arrêter le service Hadoop Namenode and Yarn à tout moment en exécutant stop-dfs.sh et stop-yarn.sh script en tant qu'utilisateur Hadoop.
Pour arrêter le service Hadoop Namenode, exécutez la commande suivante en tant qu'utilisateur hadoop :
stop-dfs.sh
Pour arrêter le service Hadoop Resource Manager, exécutez la commande suivante :
stop-yarn.sh
Conclusion
Ce tutoriel vous a expliqué étape par étape le tutoriel pour installer et configurer Hadoop sur le système Linux Ubuntu 20.04.