Afin d'organiser les données sous forme de liste liée à l'aide de struct list_head vous devez déclarer la racine de la liste et déclarer entrée de liste pour l'attelage. Les entrées racine et enfant sont du même type (struct list_head ). children saisie de struct task_struct l'entrée est un root . sibling saisie de struct task_struct est un list entry . Pour voir les différences, vous devez lire le code, où children et sibling sont utilisés. Utilisation de list_for_each pour children signifie quoi children est un root . Utilisation de list_entry pour sibling signifie quoi sibling est un list entry .
Vous pouvez en savoir plus sur les listes de noyau Linux ici.
Question :Quelle est la raison pour laquelle nous passons "frère" ici qui finit par une liste différente avec un décalage différent ?
Réponse :
Si la liste a été créée de cette façon :
list_add(&subtask->sibling, ¤t->children);
Que
list_for_each(list, ¤t->children)
Initialisera les pointeurs de liste à sibling , vous devez donc utiliser subling comme paramètre de list_entry. C'est comment le noyau Linux répertorie l'API conçue.
Mais, si la liste a été créée dans un autre (faux ) manière :
list_add(&subtask->children, ¤t->sibling);
Que vous devez itérer la liste ceci (faux ) manière :
list_for_each(list, ¤t->sibling)
Et maintenant, vous devez utiliser children comme paramètre pour list_entry .
J'espère que cela aide.
Voici la représentation picturale qui pourrait aider quelqu'un à l'avenir. La case du haut représente un parent et les deux cases du bas sont ses enfants

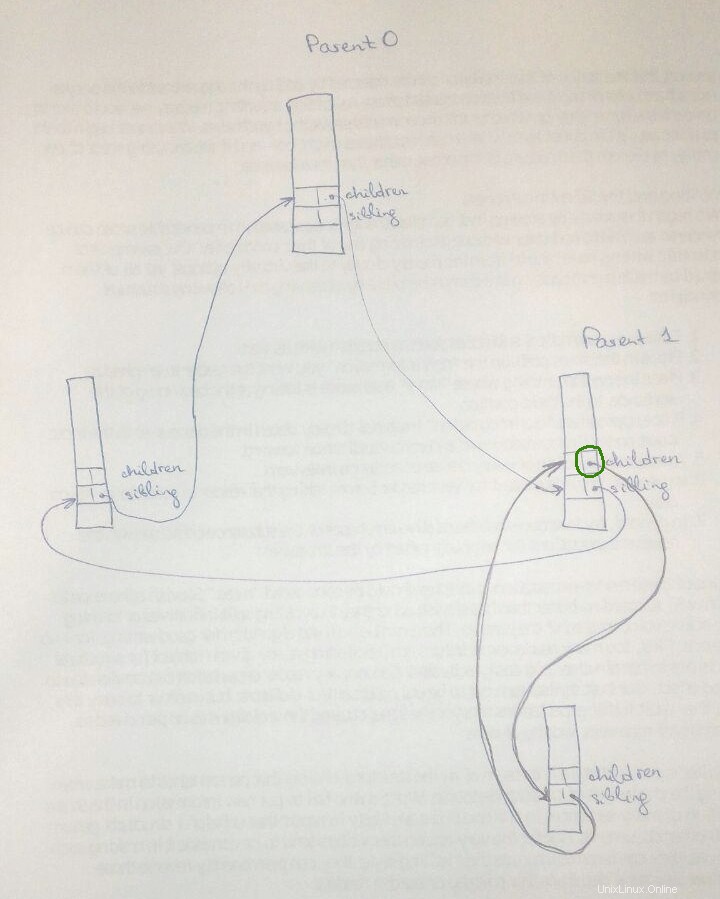
Voici une image en plus des réponses précédentes. Le même processus peut être à la fois un parent et un enfant (comme Parent1 sur l'image), et nous devons faire la distinction entre ces deux rôles.
Intuitivement, si children de Parent0 pointerait vers children de Parent1, puis Parent0.children.next->next (cercle vert sur l'image), qui équivaut à Parent1.children.next , pointerait vers un enfant de Parent1 au lieu d'un enfant suivant de Parent0.