Les administrateurs système expérimentés personnalisent généralement leurs systèmes Linux en fonction de leurs besoins et pour créer un environnement cohérent. Mais que se passe-t-il si vous travaillez dans un environnement où vous ne le faites pas avez-vous le pouvoir d'apporter des modifications permanentes ? Ou vous aidez simplement quelqu'un d'un autre département ? Parfois, l'autre serveur peut exécuter une "saveur" différente de Linux ou même un type différent d'Unix.
Voici quelques astuces rapides et salissantes qui peuvent être utiles dans certaines situations pratiques.
[ Les lecteurs ont également aimé : Plus d'astuces Bash stupides :variables, recherche, descripteurs de fichiers et opérations à distance ]
Connaître les règles et savoir quand enfreindre les règles
Les variables doivent avoir des noms clairs pour les rendre faciles à comprendre, pour être auto-documentées et pour garder notre santé mentale. Je suppose que tout le monde est d'accord avec ça.
Mais parfois, vous êtes pressé de résoudre un problème de production au milieu de la nuit et vous souhaitez agir rapidement .
D'autres fois, vous devez également économiser de la frappe, car vous savez que vous devrez exécuter plusieurs fois de longues commandes. Dans une situation normale, vous créeriez des alias et les placeriez dans vos profils de connexion. Cependant, nous parlons ici d'un environnement inconnu, lorsque vous vous concentrez sur la résolution de l'incident.
Le cas classique de "trop de connexions réseau qui se déchaînent"
Vous êtes averti à 2 heures du matin parce que "quelque chose" ne fonctionne pas. Tout a fonctionné normalement jusqu'à cette nuit.
En commençant par une variation du ss commande (ou netstat, si vous êtes un peu plus âgé, comme moi), vous en remarquez des centaines de connexions dans un TIME-WAIT et CLOSE-WAIT sur votre serveur principal.
Remarque :Dans l'animation ci-dessous, nous utilisons le ss -4a commande pour lister toutes les connexions IPv4. Mais nous sommes plus intéressés par ceux qui sont en WAIT état :
Vous pouvez voir que toutes ces connexions semblent pointer vers le port 50505 sur au moins deux serveurs. L'IP et le port de destination sont dans le champ #6. Voir l'image ci-dessous.
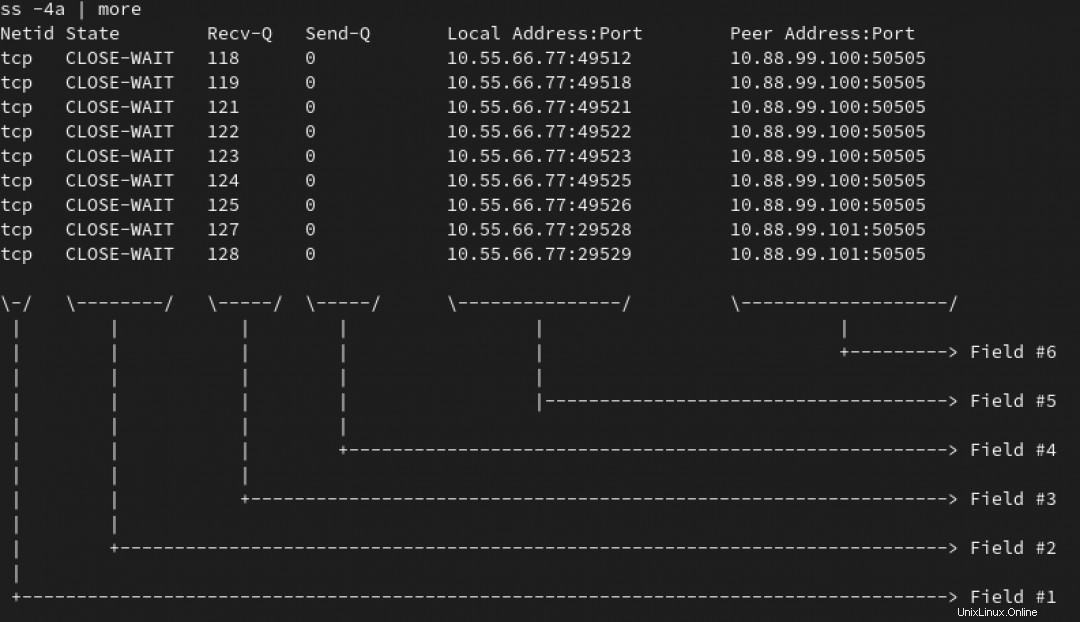
Maintenant, vous voulez savoir combien des connexions sont en attente pour chaque adresse IP cible.
Nous pouvons accomplir cela en modifiant le ss commande que nous avons utilisée précédemment :
La séquence d'étapes est la suivante :
- Nous commençons à examiner l'en-tête et les 10 premières lignes à l'aide de la commande
ss -4a | grep WAIT | head - Ensuite, nous
pipeque pourawk, qui dans ce cas est utilisé pour imprimer le champ #6 (nous supposons que les espaces sont le séparateur par défaut). - Après cela, nous
sortla sortie précédente car ensuite, nous voulons avoir un décompte des serveurs de destination distincts impliqués. - Enfin, nous utilisons
uniq -cpour présenter le nombre de lignes uniques. Comme nous sommes dans la dernière étape de cette tâche, nous devons supprimer leheadcommande que nous avons utilisée lors de la construction de la sortie.
À ce stade de l'enquête, vous pouvez commencer à établir des corrélations, telles que "Les deux autres destinations sont affectées, de sorte que la cause première se situe soit au niveau du cluster, soit liée au réseau/au pare-feu."
Il existe certainement des moyens de personnaliser la sortie de ss pour afficher uniquement la colonne qui vous intéresse. Mais c'est peut-être quelque chose que vous ne voudrez peut-être pas rechercher à 2 heures du matin. Ce n'était qu'un exemple, et dans de nombreuses autres situations, vous aurez d'autres commandes avec plusieurs options.
Ici, l'idée est de montrer un moyen rapide de travailler avec la sortie qui vous est probablement familière, à partir de certaines commandes que vous avez déjà utilisées (mais vous n'avez pas besoin ou ne voulez pas mémoriser TOUTES les façons possibles de configurer leur sortie).
Le cas classique du "faible espace disque disponible"
Autre exemple concret :vous résolvez un problème et découvrez qu'un système de fichiers est à 100 % de sa capacité.
Il peut y avoir de nombreux sous-répertoires et fichiers en production, vous devrez donc peut-être trouver un moyen de classer les "pires répertoires" car le problème (ou la solution) pourrait se trouver dans un ou plusieurs.
Dans l'exemple suivant, je vais montrer un scénario très simple pour illustrer ce point.
La séquence d'étapes est la suivante :
- Nous allons dans le système de fichiers où l'espace disque est faible (j'ai utilisé mon répertoire personnel comme exemple).
- Ensuite, nous utilisons la commande
df -k *pour afficher la taille des répertoires en kilo-octets. - Cela nécessite une certaine classification pour que nous trouvions les plus importants, mais il suffit de
sortn'est pas suffisant car, par défaut, cette commande ne traitera pas les nombres comme des valeurs mais uniquement des caractères. - Nous ajoutons
-nausortcommande, qui nous montre maintenant les plus grands répertoires. - Au cas où nous devions naviguer vers de nombreux autres répertoires, créer un
aliaspourrait être utile.
[ Apprenez les bases de l'utilisation de Kubernetes dans cet aide-mémoire gratuit. ]
Récapitulez
Certaines commandes sont utiles dans différentes situations, telles que grep , awk , sort . Connaître certaines options de base et les combiner peut être très efficace lorsque vous devez manipuler et simplifier la sortie d'autres commandes ou lors du traitement de fichiers texte.
Ces commandes existent dans presque toutes les variantes d'Unix, anciennes ou nouvelles, ce qui fait qu'il est avantageux de les avoir dans votre sac à malice. Vous ne savez jamais quand ces outils vous sauveront la vie (clin d'œil).