Dans la première partie de cette série, j'ai abordé les concepts de base des cgroups et comment les cgroups aident à gérer les performances et la sécurité sur les serveurs Linux. Ici, dans la deuxième partie, je discute de la valeur CPUShares et de la façon dont elle est utilisée par les cgroups. N'oubliez pas que dans la troisième partie, je regarde l'administration des cgroups et dans la quatrième partie, je conclus avec les cgroups lorsqu'ils interagissent avec systemd.
Un peu sur les ascenseurs Linux
Je vais me concentrer très étroitement sur Red Hat Enterprise Linux (RHEL) pour cette section. Cependant, dans mon rapide coup d'œil sur les quelques boîtes Ubuntu de mon laboratoire, j'ai remarqué des similitudes avec le planificateur d'E/S. Par conséquent, certains de mes points pourraient également s'appliquer à d'autres distributions. La plupart des produits de la famille Red Hat (Fedora, CentOS et RHEL) utilisent soit deadline ou cfq comme planificateurs par défaut.
- Completely Fair Queuing (CFQ) :met l'accent sur les E/S provenant de processus en temps réel et utilise des données historiques pour décider si une application émettra d'autres requêtes d'E/S dans un avenir proche.
- Date limite :tente de fournir une latence garantie pour les requêtes et convient particulièrement lorsque les opérations de lecture se produisent plus souvent que les opérations d'écriture. Il y a une file d'attente pour les lectures et une pour les écritures. Les opérations sont terminées en fonction du temps passé dans la file d'attente, et le noyau essaiera toujours de traiter les requêtes avant que leur durée maximale ne se soit écoulée. Les opérations de lecture ont priorité sur les lots d'écriture par défaut.
Dans cet esprit, RHEL a tendance à utiliser cfq pour les disques SATA et deadline pour tous les autres cas par défaut. Cela joue un rôle important dans le réglage de votre système. Ces planificateurs peuvent être modifiés, bien sûr, et vous devez étudier votre charge de travail et choisir le planificateur qui convient le mieux à vos tâches. Il convient également de noter qu'un planificateur peut être choisi par périphérique de bloc . Cela signifie que vous pouvez avoir plusieurs planificateurs sur un seul système, selon la configuration de vos disques.
[ Vous pourriez également aimer :Configurer des serveurs SSH conteneurisés pour l'enregistrement de session avec tlog ]
Partages CPU
Les CPUShares La valeur fournit aux tâches d'un groupe de contrôle une quantité relative de temps CPU. Une fois que le système a monté le contrôleur cpu cgroup, vous pouvez utiliser le fichier cpu.shares pour définir le nombre de partages alloués au cgroup. Le temps CPU est déterminé en divisant les CPUShares du cgroup par le nombre total de CPUShares définis sur le système. Ce calcul du temps CPU devient assez compliqué, alors regardons quelques diagrammes pour clarifier les choses.
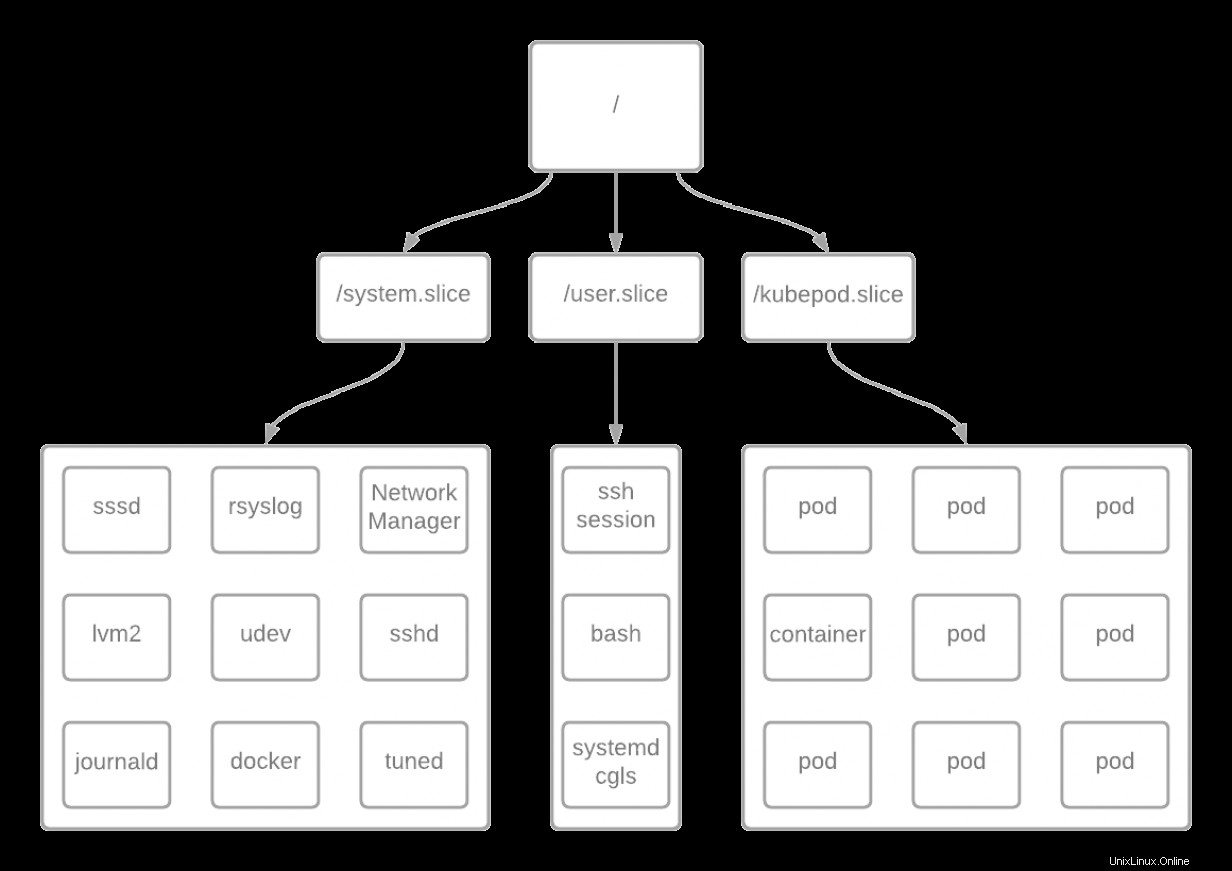
Le diagramme ci-dessus représente certains des éléments les plus courants sur un serveur de plan de contrôle RHEL 7 OpenShift Container Platform. Chaque processus sur ce système commence par le / groupe de contrôle.
Dans RHEL, cela commence par la racine / cgroup avec 1024 partages et 100% des ressources CPU. Le reste des ressources est réparti équitablement entre les groupes /system.slice , /user.slice , et /kubepod.slice , chacun avec un poids égal de 1024 par défaut, comme indiqué ci-dessous :
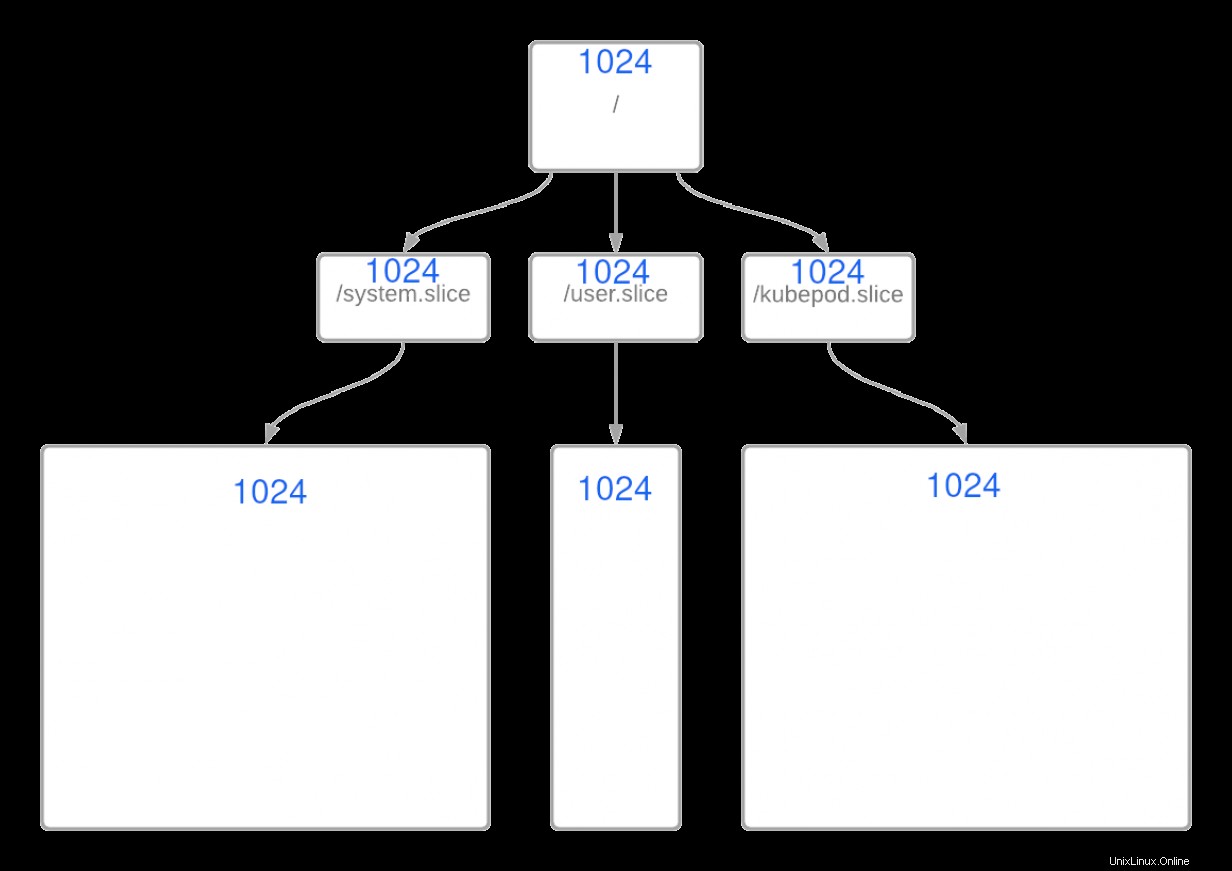
Dans ce scénario, la logique est assez simple :chaque tranche ne peut utiliser que 33 % des CPUShares si tous les cgroups demandent des partages simultanément. Le calcul est assez simple :

Et quand vous branchez les chiffres :
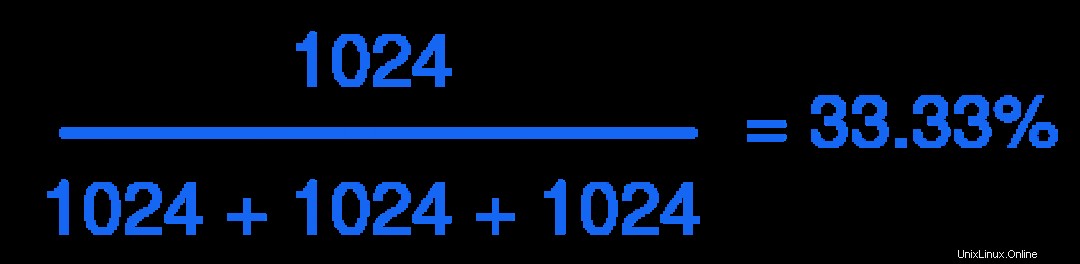
Cependant, que se passe-t-il si vous décidez d'imbriquer des groupes ou de modifier le poids des groupes au même niveau ? Voici un exemple de groupes imbriqués :
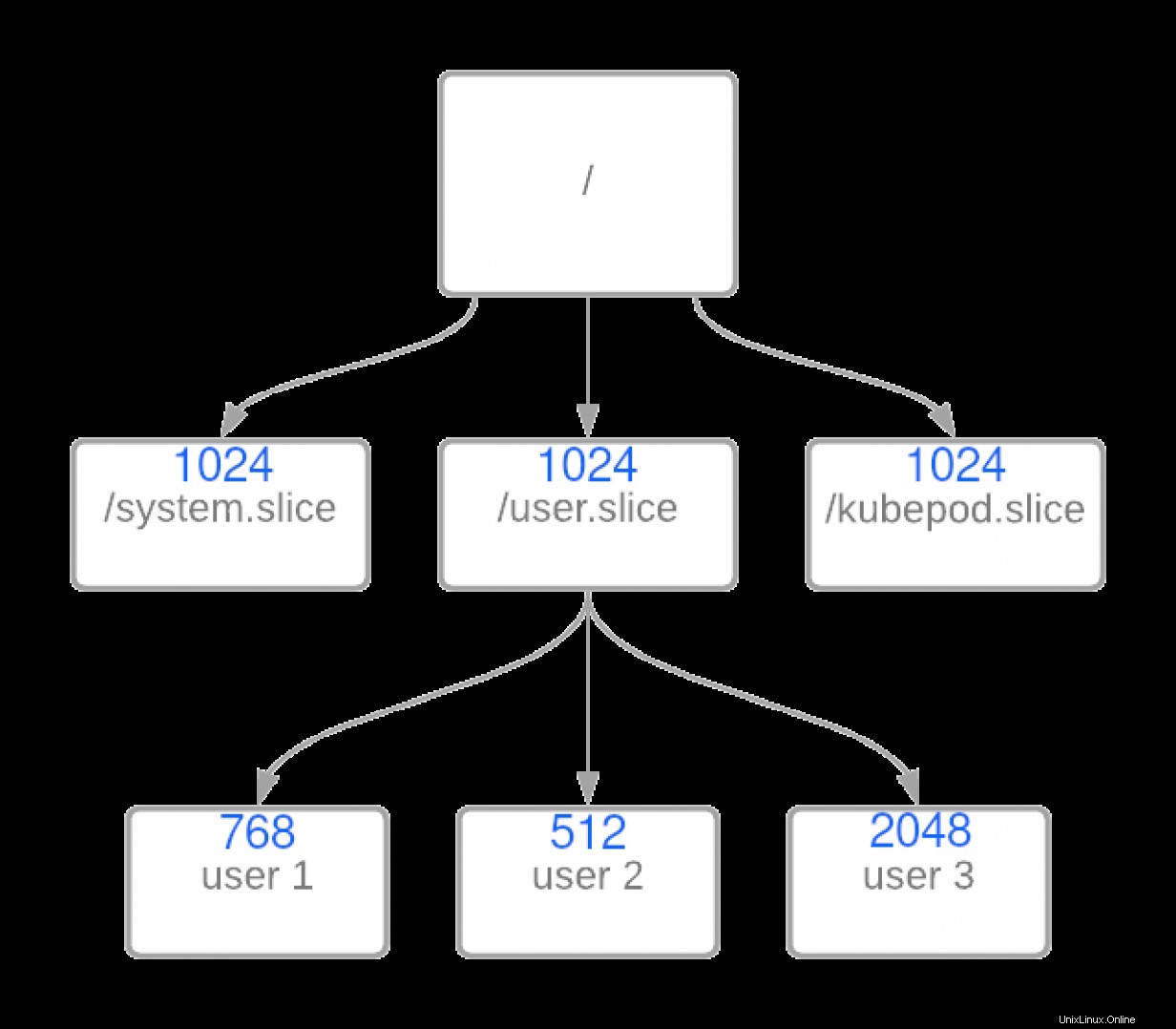
Dans cet exemple, vous voyez que j'ai créé un groupe de contrôle pour différents utilisateurs. C'est là que les mathématiques deviennent intéressantes. Au début, vous penseriez que l'équation suivante fonctionnerait très bien :

Cependant, cela ne représente que 23 % des 33 % alloués à user.slice . Cela signifie user1 dispose d'environ 7,6 % du temps CPU total sur la base de ces pondérations en cas de conflit de ressources.
CPUShares est devenu compliqué à la hâte. Heureusement, la plupart des autres contrôleurs sont plus simples que celui-ci.
[ Vous débutez avec les conteneurs ? Découvrez ce cours gratuit. Déploiement d'applications conteneurisées :présentation technique. ]
Récapitulez
Les valeurs CPUShares peuvent rendre les cgroups vraiment complexes. C'est en partie pourquoi je voulais couvrir CPUShares ici. Cependant, l'utilisation appropriée de CPUShares vous aide à gérer votre système de manière plus efficace et plus précise.
Dans le prochain article de cette série, je discute de l'administration des groupes de contrôle. J'espère que vous continuerez à suivre cette série. Dans la quatrième partie, je conclurai notre discussion avec systemd et cgroups.