Je travaille à temps partiel en tant qu'auditeur de données. Considérez-moi comme un correcteur d'épreuves qui travaille avec des tableaux de données plutôt qu'avec des pages de prose. Les tables sont exportées depuis des bases de données relationnelles et sont généralement de taille assez modeste :100 000 à 1 000 000 d'enregistrements et 50 à 200 champs.
Je n'ai jamais vu de tableau de données sans erreur. Le désordre ne se limite pas, comme vous pourriez le penser, aux enregistrements en double, aux fautes d'orthographe et de formatage et aux éléments de données placés dans le mauvais champ. Je trouve aussi :
- enregistrements cassés répartis sur plusieurs lignes car les éléments de données avaient des sauts de ligne intégrés
- éléments de données dans un champ en désaccord avec des éléments de données dans un autre champ, dans le même enregistrement
- les enregistrements contenant des éléments de données tronqués, souvent parce que de très longues chaînes ont été insérées dans des champs limités à 50 ou 100 caractères
- Échecs d'encodage des caractères produisant le charabia connu sous le nom de mojibake
- caractères de contrôle invisibles, dont certains peuvent entraîner des erreurs de traitement des données
- caractères de remplacement et mystérieux points d'interrogation insérés par le dernier programme qui n'a pas compris l'encodage des caractères des données
Nettoyer ces problèmes n'est pas difficile, mais il existe des obstacles non techniques pour les trouver. Le premier est la réticence naturelle de chacun à faire face aux erreurs de données. Avant que je ne voie un tableau, les propriétaires ou les gestionnaires de données ont peut-être traversé les cinq étapes de Data Grief :
- Il n'y a pas d'erreurs dans nos données.
- Eh bien, il y a peut-être quelques erreurs, mais elles ne sont pas si importantes.
- OK, il y a beaucoup d'erreurs ; nous demanderons à nos collaborateurs internes de s'en occuper.
- Nous avons commencé à corriger quelques-unes des erreurs, mais cela prend du temps ; nous le ferons lors de la migration vers le nouveau logiciel de base de données.
- Nous n'avons pas eu le temps de nettoyer les données lors du passage à la nouvelle base de données ; nous aurions besoin d'aide.
La deuxième attitude qui bloque la progression est la conviction que le nettoyage des données nécessite des applications dédiées, soit des programmes propriétaires coûteux, soit l'excellent programme open source OpenRefine. Pour traiter les problèmes que les applications dédiées ne peuvent pas résoudre, les gestionnaires de données peuvent demander l'aide d'un programmeur, quelqu'un qui maîtrise Python ou R.
Mais l'audit et le nettoyage des données ne nécessitent généralement pas d'applications dédiées. Les tableaux de données en texte brut existent depuis de nombreuses décennies, tout comme les outils de traitement de texte. Ouvrez un shell Bash et vous disposez d'une boîte à outils chargée de puissants traitements de texte tels que grep , cut , paste , sort , uniq , tr , et awk . Ils sont rapides, fiables et faciles à utiliser.
Je fais tous mes audits de données sur la ligne de commande, et j'ai mis beaucoup de mes astuces d'audit de données sur un site Web de "livre de recettes". Les opérations que je fais régulièrement sont stockées sous forme de fonctions et de scripts shell (voir l'exemple ci-dessous).
Oui, une approche en ligne de commande nécessite que les données à auditer aient été exportées de la base de données. Et oui, les résultats de l'audit doivent être modifiés ultérieurement dans la base de données ou (si la base de données le permet) les éléments de données nettoyés doivent être importés en remplacement de ceux qui sont désordonnés.
Mais les avantages sont remarquables. awk traitera quelques millions d'enregistrements en quelques secondes sur un ordinateur de bureau ou portable grand public. Les expressions régulières simples trouveront toutes les erreurs de données que vous pouvez imaginer. Et tout cela se passera en toute sécurité dehors la structure de la base de données :l'audit de la ligne de commande ne peut pas affecter la base de données, car il fonctionne avec des données libérées de sa prison de base de données.
Les lecteurs qui se sont formés sur Unix souriront d'un air suffisant à ce stade. Ils se souviennent avoir manipulé des données sur la ligne de commande il y a de nombreuses années de ces manières. Ce qui s'est passé depuis lors, c'est que la puissance de traitement et la RAM ont augmenté de façon spectaculaire, et les outils de ligne de commande standard ont été rendus beaucoup plus efficaces. L'audit des données n'a jamais été aussi simple et rapide. Et maintenant que Microsoft Windows 10 peut exécuter des programmes Bash et GNU/Linux, les utilisateurs de Windows peuvent apprécier la devise Unix et Linux pour gérer les données désordonnées :restez calme et ouvrez un terminal.

Un exemple
Supposons que je veuille trouver l'élément de données le plus long dans un champ particulier d'une grande table. Ce n'est pas vraiment une tâche d'audit de données, mais cela montrera comment fonctionnent les outils shell. À des fins de démonstration, j'utiliserai le tableau séparé par des tabulations full0 , qui contient 1 122 023 enregistrements (plus une ligne d'en-tête) et 49 champs, et je vais regarder dans le champ numéro 36. (J'obtiens des numéros de champ avec une fonction expliquée sur mon site de livre de cuisine.)
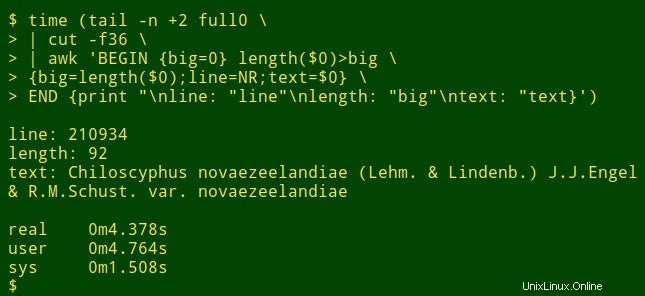
La commande commence par utiliser tail pour supprimer la ligne d'en-tête de full0 . Le résultat est redirigé vers cut , qui extrait le champ décapité 36. Le suivant dans le pipeline est awk . Ici la variable big est initialisé à une valeur de 0 ; puis awk teste la longueur de l'élément de données dans le premier enregistrement. Si la longueur est supérieure à 0, awk réinitialise big à la nouvelle longueur et stocke le numéro de ligne (NR) dans la variable line et toute la donnée dans la variable text . awk traite ensuite tour à tour chacun des 1 122 022 enregistrements restants, en réinitialisant les trois variables lorsqu'il trouve un élément de données plus long. Enfin, il imprime une liste soigneusement séparée des numéros de ligne, de la longueur de l'élément de données et du texte intégral de l'élément de données le plus long. (Dans le code suivant, les commandes ont été réparties sur plusieurs lignes pour plus de clarté.)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
Combien de temps cela prend-il ? Environ 4 secondes sur mon bureau (core i5, 8 Go de RAM) :
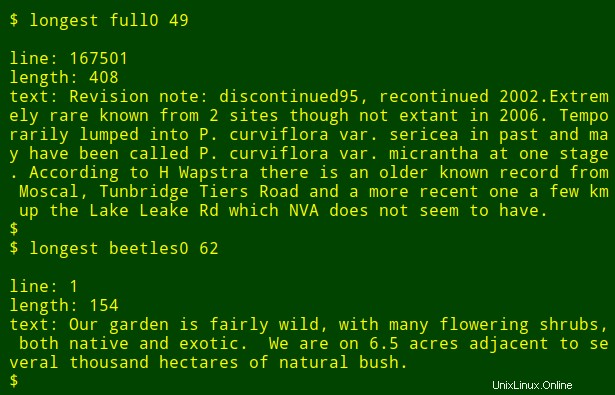
Maintenant, pour la partie intéressante :je peux insérer cette longue commande dans une fonction shell, longest , qui prend comme arguments le nom de fichier ($1) et le numéro de champ ($2) :

Je peux ensuite réexécuter la commande en tant que fonction, en trouvant les éléments de données les plus longs dans d'autres champs et dans d'autres fichiers sans avoir à me rappeler comment la commande est écrite :
Comme dernier réglage, je peux ajouter à la sortie le nom du champ numéroté que je recherche. Pour ce faire, j'utilise head pour extraire la ligne d'en-tête du tableau, dirigez cette ligne vers tr pour convertir les onglets en nouvelles lignes et diriger la liste résultante vers tail et head pour imprimer le $2th nom du champ dans la liste, où $2 est l'argument du numéro de champ. Le nom du champ est stocké dans la variable shell field et passé à awk pour l'impression en tant que awk interne variable fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 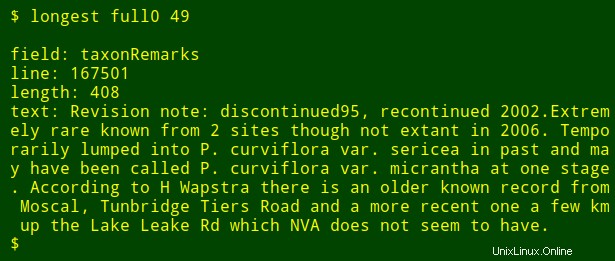
Notez que si je recherche l'élément de données le plus long dans un certain nombre de champs différents, tout ce que j'ai à faire est d'appuyer sur la touche Flèche vers le haut pour obtenir le dernier longest commande, puis reculez le numéro de champ et entrez-en un nouveau.