Qu'est-ce qu'un système de fichiers ? Selon le premier contributeur et auteur de Linux, Robert Love, "Un système de fichiers est un stockage hiérarchique de données adhérant à une structure spécifique." Cependant, cette description s'applique aussi bien à VFAT (Virtual File Allocation Table), Git et Cassandra (une base de données NoSQL). Qu'est-ce qui distingue un système de fichiers ?
Les bases du système de fichiers
Le noyau Linux exige que pour qu'une entité soit un système de fichiers, elle doit également implémenter le open() , lire() , et écrire() méthodes sur des objets persistants auxquels sont associés des noms. Du point de vue de la programmation orientée objet, le noyau traite le système de fichiers générique comme une interface abstraite, et ces trois grandes fonctions sont "virtuelles", sans définition par défaut. En conséquence, l'implémentation du système de fichiers par défaut du noyau est appelée système de fichiers virtuel (VFS).
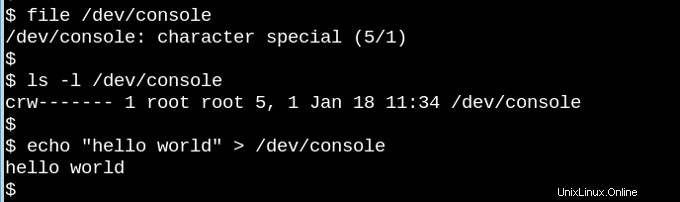
VFS sous-tend la célèbre observation selon laquelle dans les systèmes de type Unix "tout est un fichier". Considérez à quel point il est étrange que la petite démo ci-dessus présentant le périphérique de caractère /dev/console fonctionne réellement. L'image montre une session Bash interactive sur un téléscripteur virtuel (tty). L'envoi d'une chaîne dans le périphérique de console virtuelle la fait apparaître sur l'écran virtuel. VFS a d'autres propriétés encore plus étranges. Par exemple, il est possible d'y chercher.
Plus de ressources Linux
- Aide-mémoire des commandes Linux
- Aide-mémoire des commandes Linux avancées
- Cours en ligne gratuit :Présentation technique de RHEL
- Aide-mémoire sur le réseau Linux
- Aide-mémoire SELinux
- Aide-mémoire sur les commandes courantes de Linux
- Que sont les conteneurs Linux ?
- Nos derniers articles Linux
Les systèmes de fichiers familiers tels que ext4, NFS et /proc fournissent tous des définitions des trois grandes fonctions dans une structure de données en langage C appelée file_operations. De plus, des systèmes de fichiers particuliers étendent et remplacent les fonctions VFS de la manière familière orientée objet. Comme le souligne Robert Love, l'abstraction de VFS permet aux utilisateurs de Linux de copier allègrement des fichiers vers et depuis des systèmes d'exploitation étrangers ou des entités abstraites comme des canaux sans se soucier de leur format de données interne. Au nom de l'espace utilisateur, via un appel système, un processus peut copier d'un fichier dans les structures de données du noyau avec la méthode read() d'un système de fichiers, puis utiliser la méthode write() d'un autre type de système de fichiers pour sortir les données.
Les définitions de fonctions qui appartiennent au type de base VFS lui-même se trouvent dans les fichiers fs/*.c dans la source du noyau, tandis que les sous-répertoires de fs/ contiennent les systèmes de fichiers spécifiques. Le noyau contient également des entités de type système de fichiers telles que cgroups, /dev et tmpfs, qui sont nécessaires au début du processus de démarrage et sont donc définies dans le sous-répertoire init/ du noyau. Notez que cgroups, /dev et tmpfs n'appellent pas les trois grandes fonctions file_operations, mais lisent et écrivent directement dans la mémoire à la place.
Le diagramme ci-dessous illustre grossièrement comment l'espace utilisateur accède à divers types de systèmes de fichiers couramment montés sur les systèmes Linux. Ne sont pas représentés les constructions telles que les pipes, dmesg et les horloges POSIX qui implémentent également la structure file_operations et dont les accès passent donc par la couche VFS.
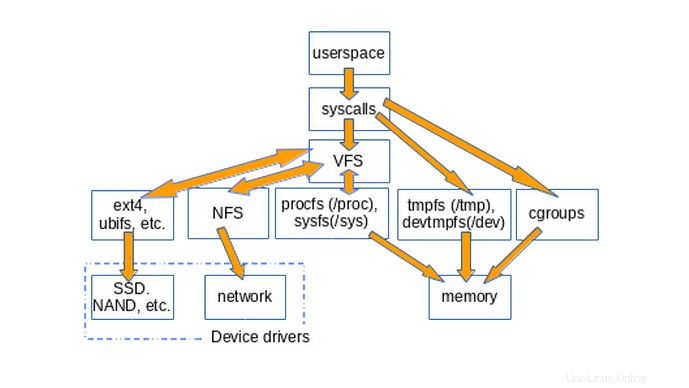
L'existence de VFS favorise la réutilisation du code, car les méthodes de base associées aux systèmes de fichiers n'ont pas besoin d'être réimplémentées par chaque type de système de fichiers. La réutilisation du code est une pratique exemplaire largement acceptée en génie logiciel ! Hélas, si le code réutilisé introduit des bugs sérieux, alors toutes les implémentations qui héritent des méthodes communes en souffrent.
/tmp :un conseil simple
Un moyen simple de savoir quels VFS sont présents sur un système consiste à taper mount | grep -v sd | grep -v :/ , qui répertorie tous les systèmes de fichiers montés qui ne résident pas sur un disque et non sur NFS sur la plupart des ordinateurs. L'un des montages VFS répertoriés sera assurément /tmp, n'est-ce pas ?

Pourquoi est-il déconseillé de conserver /tmp sur le stockage ? Parce que les fichiers dans /tmp sont temporaires (!) et que les périphériques de stockage sont plus lents que la mémoire, où les tmpfs sont créés. De plus, les appareils physiques sont plus sujets à l'usure due à l'écriture fréquente que la mémoire. Enfin, les fichiers dans /tmp peuvent contenir des informations sensibles, donc les faire disparaître à chaque redémarrage est une fonctionnalité.
Malheureusement, les scripts d'installation de certaines distributions Linux créent toujours /tmp sur un périphérique de stockage par défaut. Ne désespérez pas si tel est le cas avec votre système. Suivez des instructions simples sur le toujours excellent Arch Wiki pour résoudre le problème, en gardant à l'esprit que la mémoire allouée à tmpfs n'est pas disponible à d'autres fins. En d'autres termes, un système avec un gigantesque tmpfs contenant de gros fichiers peut manquer de mémoire et planter. Autre conseil :lors de la modification du fichier /etc/fstab, assurez-vous de le terminer par une nouvelle ligne, car votre système ne démarrera pas autrement. (Devinez comment je sais.)
/proc et /sys
Outre /tmp, les VFS avec lesquels la plupart des utilisateurs de Linux sont les plus familiers sont /proc et /sys. (/dev s'appuie sur la mémoire partagée et n'a pas de file_operations). Pourquoi deux saveurs ? Voyons plus en détail.
Le procfs offre un instantané de l'état instantané du noyau et des processus qu'il contrôle pour l'espace utilisateur. Dans /proc, le noyau publie des informations sur les fonctionnalités qu'il fournit, telles que les interruptions, la mémoire virtuelle et le planificateur. De plus, /proc/sys est l'endroit où les paramètres configurables via la commande sysctl sont accessibles à l'espace utilisateur. L'état et les statistiques des processus individuels sont signalés dans les répertoires /proc/
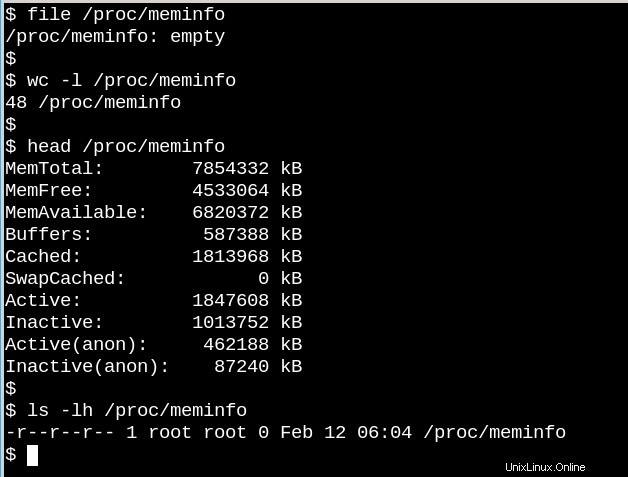
Le comportement des fichiers /proc illustre à quel point VFS peut être différent des systèmes de fichiers sur disque. D'une part, /proc/meminfo contient les informations présentées par la commande free . Par contre, c'est aussi vide ! Comment se peut-il? La situation rappelle un article célèbre écrit par le physicien de l'Université Cornell N. David Mermin en 1985 intitulé "La lune est-elle là quand personne ne regarde ? La réalité et la théorie quantique". La vérité est que le noyau rassemble des statistiques sur la mémoire lorsqu'un processus les demande à /proc, et il y en a en fait il y en a rien dans les fichiers de /proc quand personne ne regarde. Comme l'a dit Mermin, "C'est une doctrine quantique fondamentale qu'une mesure ne révèle pas, en général, une valeur préexistante de la propriété mesurée." (La réponse à la question sur la lune est laissée en exercice.)

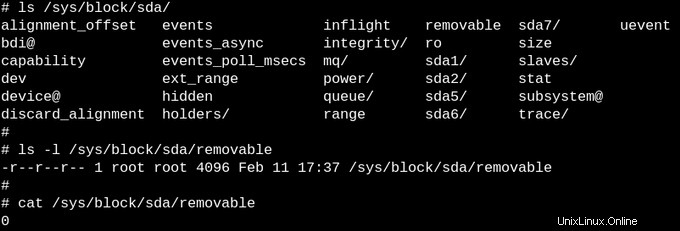
Le vide apparent de procfs est logique, car les informations qui y sont disponibles sont dynamiques. La situation avec sysfs est différente. Comparons le nombre de fichiers d'au moins un octet dans /proc par rapport à /sys.
Procfs en a précisément une, à savoir la configuration du noyau exportée, qui est une exception puisqu'elle n'a besoin d'être générée qu'une seule fois par démarrage. D'autre part, /sys contient de nombreux fichiers plus volumineux, dont la plupart comprennent une page de mémoire. En règle générale, les fichiers sysfs contiennent exactement un nombre ou une chaîne, contrairement aux tableaux d'informations produits en lisant des fichiers comme /proc/meminfo.
Le but de sysfs est d'exposer les propriétés lisibles et inscriptibles de ce que le noyau appelle "kobjects" à l'espace utilisateur. Le seul but des kobjects est le comptage de références :lorsque la dernière référence à un kobject est supprimée, le système récupère les ressources qui lui sont associées. Pourtant, /sys constitue la majeure partie de la fameuse « ABI stable vers l'espace utilisateur » du noyau que personne ne peut jamais, en aucune circonstance, « casser ». Cela ne signifie pas que les fichiers dans sysfs sont statiques, ce qui serait contraire au comptage de références des objets volatils.
L'ABI stable du noyau limite plutôt ce qui peut apparaissent dans /sys, et non ce qui est réellement présent à un instant donné. La liste des autorisations sur les fichiers dans sysfs donne une idée de la façon dont les paramètres configurables et réglables des périphériques, modules, systèmes de fichiers, etc. peuvent être définis ou lus. La logique oblige à conclure que procfs fait également partie de l'ABI stable du noyau, bien que la documentation du noyau ne le précise pas explicitement.
Snooping sur VFS avec les outils eBPF et bcc
Le moyen le plus simple d'apprendre comment le noyau gère les fichiers sysfs est de le regarder en action, et le moyen le plus simple de regarder sur ARM64 ou x86_64 est d'utiliser eBPF. eBPF (Extended Berkeley Packet Filter) consiste en une machine virtuelle s'exécutant à l'intérieur du noyau que les utilisateurs privilégiés peuvent interroger à partir de la ligne de commande. La source du noyau indique au lecteur ce que le noyau peut faire; l'exécution des outils eBPF sur un système démarré montre à la place ce que le noyau fait réellement fait .
Heureusement, démarrer avec eBPF est assez facile via les outils bcc, qui sont disponibles sous forme de packages à partir des principales distributions Linux et ont été amplement documentés par Brendan Gregg. Les outils bcc sont des scripts Python avec de petits extraits de C intégrés, ce qui signifie que toute personne à l'aise avec l'une ou l'autre langue peut facilement les modifier. À ce compte, il y a 80 scripts Python dans bcc/tools, ce qui rend très probable qu'un administrateur système ou un développeur en trouve un existant correspondant à ses besoins.
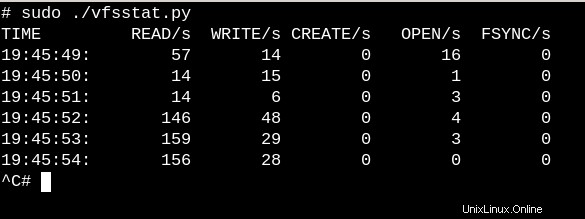
Pour avoir une idée très grossière du travail que les VFS effectuent sur un système en cours d'exécution, essayez le simple vfscount ou vfsstat, qui montre que des dizaines d'appels à vfs_open() et à ses amis se produisent chaque seconde.
Pour un exemple moins trivial, regardons ce qui se passe dans sysfs lorsqu'une clé USB est insérée sur un système en cours d'exécution.
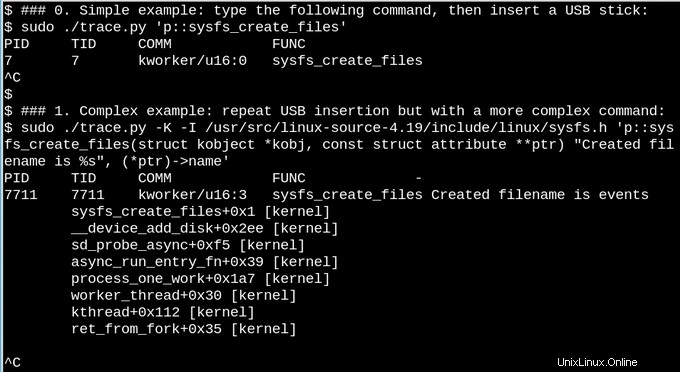
Dans le premier exemple simple ci-dessus, le script trace.py bcc tools imprime un message chaque fois que la commande sysfs_create_files() s'exécute. Nous voyons que sysfs_create_files() a été démarré par un thread kworker en réponse à l'insertion de la clé USB, mais quel fichier a été créé ? Le deuxième exemple illustre toute la puissance d'eBPF. Ici, trace.py imprime la trace du noyau (option -K) plus le nom du fichier créé par sysfs_create_files(). L'extrait à l'intérieur des guillemets simples est un code source C, y compris une chaîne de format facilement reconnaissable, que le script Python fourni incite un compilateur juste-à-temps LLVM à compiler et à exécuter dans une machine virtuelle dans le noyau. La signature complète de la fonction sysfs_create_files() doit être reproduite dans la deuxième commande afin que la chaîne de format puisse faire référence à l'un des paramètres. Faire des erreurs dans cet extrait C entraîne des erreurs reconnaissables du compilateur C. Par exemple, si le -I est omis, le résultat est "Échec de la compilation du texte BPF". Les développeurs qui maîtrisent C ou Python trouveront les outils bcc faciles à étendre et à modifier.
Lorsque la clé USB est insérée, la trace du noyau apparaît, indiquant que le PID 7711 est un thread kworker qui a créé un fichier appelé "events" dans sysfs. Une invocation correspondante avec sysfs_remove_files() montre que la suppression de la clé USB entraîne la suppression du fichier d'événements, conformément à l'idée du comptage de références. Regarder sysfs_create_link() avec eBPF lors de l'insertion de la clé USB (non illustré) révèle que pas moins de 48 liens symboliques sont créés.
Quel est le but du fichier d'événements de toute façon ? L'utilisation de cscope pour trouver la fonction __device_add_disk() révèle qu'elle appelle disk_add_events() et que "media_change" ou "eject_request" peut être écrit dans le fichier d'événements. Ici, la couche de bloc du noyau informe l'espace utilisateur de l'apparition et de la disparition du "disque". Considérez la rapidité avec laquelle cette méthode d'enquête sur le fonctionnement de l'insertion de clé USB est instructive par rapport à la tentative de comprendre le processus uniquement à partir de la source.
Les systèmes de fichiers racine en lecture seule rendent les périphériques intégrés possibles
Assurément, personne n'arrête un serveur ou un système de bureau en débranchant la prise d'alimentation. Pourquoi? Parce que les systèmes de fichiers montés sur les périphériques de stockage physiques peuvent avoir des écritures en attente, et les structures de données qui enregistrent leur état peuvent ne plus être synchronisées avec ce qui est écrit sur le stockage. Lorsque cela se produit, les propriétaires du système devront attendre au prochain démarrage que l'outil de récupération du système de fichiers fsck s'exécute et, dans le pire des cas, ils perdront des données.
Pourtant, les aficionados auront entendu dire que de nombreux appareils IoT et embarqués comme les routeurs, les thermostats et les automobiles fonctionnent désormais sous Linux. Beaucoup de ces appareils manquent presque entièrement d'interface utilisateur, et il n'y a aucun moyen de les "dédémarrer" proprement. Envisagez de démarrer une voiture avec une batterie déchargée où l'alimentation de l'unité principale fonctionnant sous Linux monte et descend à plusieurs reprises. Comment se fait-il que le système démarre sans un long fsck lorsque le moteur démarre enfin? La réponse est que les appareils embarqués reposent sur un système de fichiers racine en lecture seule (ro-rootfs en abrégé).
Un ro-rootfs offre de nombreux avantages moins évidents que l'incorruptibilité. La première est que les logiciels malveillants ne peuvent pas écrire dans /usr ou /lib si aucun processus Linux ne peut y écrire. Un autre est qu'un système de fichiers largement immuable est essentiel pour le support sur le terrain des périphériques distants, car le personnel de support possède des systèmes locaux qui sont nominalement identiques à ceux sur le terrain. L'avantage le plus important (mais aussi le plus subtil) est peut-être que ro-rootfs oblige les développeurs à décider pendant la phase de conception d'un projet quels objets système seront immuables. Traiter avec ro-rootfs peut souvent être gênant ou même douloureux, comme le sont souvent les variables const dans les langages de programmation, mais les avantages remboursent facilement les frais généraux supplémentaires.
La création d'un rootfs en lecture seule nécessite des efforts supplémentaires pour les développeurs embarqués, et c'est là que VFS entre en jeu. Linux a besoin de fichiers dans /var pour être inscriptibles, et en plus, de nombreuses applications populaires exécutées par les systèmes embarqués essaieront de créer une configuration dot-fichiers dans $HOME. Une solution pour les fichiers de configuration dans le répertoire personnel consiste généralement à les prégénérer et à les intégrer au rootfs. Pour /var, une approche consiste à le monter sur une partition inscriptible séparée tandis que / lui-même est monté en lecture seule. L'utilisation de montages liés ou superposés est une autre alternative populaire.
Lier et superposer les montages et leur utilisation par les conteneurs
Exécution de man mount est le meilleur endroit pour en savoir plus sur les montages liés et superposés, qui donnent aux développeurs embarqués et aux administrateurs système le pouvoir de créer un système de fichiers dans un emplacement de chemin, puis de le fournir aux applications dans un second. Pour les systèmes embarqués, l'implication est qu'il est possible de stocker les fichiers dans /var sur un périphérique flash non inscriptible, mais de superposer ou de lier un chemin dans un tmpfs sur le chemin /var au démarrage afin que les applications puissent y griffonner à leur cœur plaisir. À la prochaine mise sous tension, les modifications apportées à /var disparaîtront. Les montages superposés fournissent une union entre le tmpfs et le système de fichiers sous-jacent et permettent une modification apparente d'un fichier existant dans un ro-rootfs, tandis que les montages liés peuvent faire apparaître de nouveaux répertoires tmpfs vides comme inscriptibles sur les chemins ro-rootfs. Bien que overlayfs soit un type de système de fichiers approprié, les montages liés sont implémentés par la fonction d'espace de noms VFS.
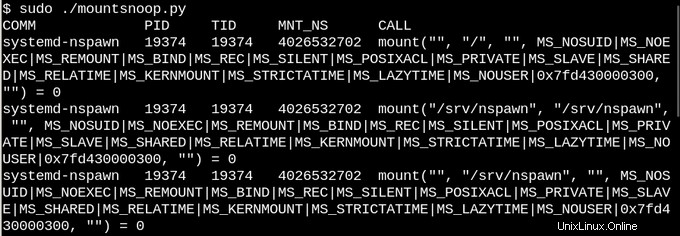
D'après la description des montages de superposition et de liaison, personne ne sera surpris que les conteneurs Linux en fassent un usage intensif. Espionnons ce qui se passe lorsque nous utilisons systemd-nspawn pour démarrer un conteneur en exécutant l'outil mountsnoop de bcc :

Et voyons ce qui s'est passé :
Ici, systemd-nspawn fournit des fichiers sélectionnés dans les procfs et sysfs de l'hôte au conteneur aux chemins de son rootfs. Outre l'indicateur MS_BIND qui définit le montage lié, certains des autres indicateurs invoqués par l'appel système "mount" déterminent la relation entre les modifications dans l'espace de noms de l'hôte et dans le conteneur. Par exemple, le montage lié peut soit propager les modifications dans /proc et /sys au conteneur, soit les masquer, selon l'invocation.
Résumé
Comprendre les composants internes de Linux peut sembler une tâche impossible, car le noyau lui-même contient une quantité gigantesque de code, laissant de côté les applications de l'espace utilisateur Linux et l'interface d'appel système dans les bibliothèques C comme glibc. Une façon de progresser consiste à lire le code source d'un sous-système du noyau en mettant l'accent sur la compréhension des appels et des en-têtes système orientés vers l'espace utilisateur, ainsi que des principales interfaces internes du noyau, illustrées ici par la table file_operations. Les opérations sur les fichiers sont ce qui fait que "tout est un fichier" fonctionne réellement, il est donc particulièrement satisfaisant de les maîtriser. Les fichiers source C du noyau dans le répertoire fs/ de niveau supérieur constituent son implémentation des systèmes de fichiers virtuels, qui sont la couche de shim qui permet une interopérabilité large et relativement simple des systèmes de fichiers et des périphériques de stockage populaires. Les montages liés et superposés via les espaces de noms Linux sont la magie VFS qui rend possibles les conteneurs et les systèmes de fichiers racine en lecture seule. En combinaison avec une étude du code source, la fonctionnalité du noyau eBPF et son interface bcc simplifient plus que jamais l'exploration du noyau.
Un grand merci à Akkana Peck et Michael Eager pour les commentaires et les corrections.
Alison Chaiken présentera les systèmes de fichiers virtuels :pourquoi nous en avons besoin et comment ils fonctionnent lors de la 17e exposition annuelle Southern California Linux Expo (SCaLE 17x) du 7 au 10 mars à Pasadena, en Californie.