Si vous utilisez Linux pour un travail régulier ou pour développer et déployer des logiciels, vous devez avoir rencontré la commande grep.
Dans cet article explicatif, je vais vous dire ce qu'est la commande grep et comment ça marche.
Qu'est-ce que grep ?
Grep est un utilitaire de ligne de commande dans les systèmes Unix et Linux. Il est utilisé pour trouver des modèles de recherche dans le contenu d'un fichier donné.
Avec son nom inhabituel, vous avez peut-être deviné que grep est un acronyme. C'est au moins partiellement vrai, mais cela dépend de qui vous demandez.
Selon des sources fiables, le nom est en fait dérivé d'une commande dans un éditeur de texte UNIX appelé ed. Dans lequel, l'entrée g/re/p effectué une recherche globale (g) d'une expression régulière (re), puis imprimé (p) toutes les lignes correspondantes.
La commande grep fait ce que les commandes g/re/p faisaient dans l'éditeur. Il effectue une recherche globale d'une expression régulière et l'imprime. Il est beaucoup plus rapide pour rechercher des fichiers volumineux.

Ceci est le récit officiel, mais vous pouvez également le voir décrit comme G R global E régulier xpression (P processeur | P arser | P imprimante). À vrai dire, il fait tout cela.
L'histoire intéressante derrière la création de grep
Ken Thompson a apporté des contributions incroyables à l'informatique. Il a aidé à créer Unix, a popularisé son approche modulaire et a écrit plusieurs de ses programmes, y compris grep.
Thompson a construit grep pour aider l'un de ses collègues des Bell Labs. L'objectif de ce scientifique était d'examiner les modèles linguistiques pour identifier les auteurs (y compris Alexander Hamilton) des Federalist Papers. Ce vaste corpus de travaux était une collection de 85 articles et essais anonymes rédigés pour la défense de la Constitution des États-Unis. Mais comme ces articles étaient anonymes, le scientifique essayait d'identifier les auteurs sur la base d'un modèle linguistique.
L'éditeur de texte Unix original, ed, (également créé par Thompson) n'était pas capable de rechercher un si grand corps de texte étant donné les limitations matérielles de l'époque. Ainsi, Thompson a transformé la fonction de recherche en un utilitaire autonome, indépendant de l'éditeur de rédaction.
Si vous y réfléchissez, cela signifie qu'Alexander Hamilton a techniquement aidé à créer grep. N'hésitez pas à partager ce fait amusant avec vos amis lors de votre soirée montre à Hamilton. 🤓
Qu'est-ce qu'une expression régulière, déjà ?
Une expression régulière (ou regex) peut être considérée comme une sorte de requête de recherche. Les expressions régulières sont utilisées pour identifier, faire correspondre ou autrement gérer le texte.
Regex est cependant capable de bien plus que des recherches par mots clés. Il peut être utilisé pour trouver n'importe quel type de motif imaginable. Les modèles peuvent être trouvés plus facilement en utilisant des méta-caractères. Ces caractères spéciaux qui rendent cet outil de recherche beaucoup plus puissant.

Il convient de noter que grep n'est qu'un outil qui utilise regex. Il existe des fonctionnalités similaires dans toute la gamme d'outils, mais les méta-caractères et la syntaxe peuvent varier. Cela signifie qu'il est important de connaître les règles de votre processeur regex particulier.
Un exemple pratique de grep :faire correspondre les numéros de téléphone
Cet outil peut être intimidant pour les débutants et les utilisateurs expérimentés de Linux. Malheureusement, même un modèle relativement simple comme un numéro de téléphone peut donner une chaîne de regex à l'aspect "effrayant".
Je tiens à vous assurer qu'il n'y a pas lieu de paniquer lorsque vous voyez des expressions comme celle-ci. Une fois familiarisé avec les bases de regex, cela peut ouvrir un nouveau monde de possibilités pour votre informatique.
Note culturelle :cet exemple utilise les conventions américaines (NANP) pour les numéros de téléphone. Ce sont des identifiants à 10 chiffres qui sont divisés en un indicatif régional (3 chiffres) et une combinaison unique à 7 chiffres où les 3 premiers chiffres correspondent à un bureau central de télécommunications (appelé préfixe) et les 4 derniers sont appelés la ligne Numéro. Le modèle est donc AAA-PPP-LLLL.
J'ai créé un fichier appelé phone.txt et notez 4 variantes courantes du même numéro de téléphone. Je vais utiliser grep pour reconnaître le modèle de nombre quel que soit le format.
J'ai également ajouté une ligne qui ne sera pas conforme à l'expression à utiliser comme contrôle. La dernière ligne 555!123!1234 n'est pas un modèle de numéro de téléphone standard et ne sera pas renvoyé par l'expression grep.
Contenu de phone.txt les fichiers sont :
example@unixlinux.online:~$ cat phone.txt
5551231234
555 123 1234
555-123-1234
(555)-123-1234
555!123!1234
Pour "grep" les numéros de téléphone, je vais écrire mon regex en utilisant des méta-caractères pour isoler les données pertinentes et ignorer ce dont je n'ai pas besoin.
La commande complète ressemblera à ceci :
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
Ça a l'air un peu intense, non ? Décomposons-le en morceaux pour avoir une meilleure idée de ce qui se passe.
Comprendre les regex, un segment à la fois
Séparons d'abord la section du RegEx qui recherche le "code régional" dans le numéro de téléphone.
Un schéma similaire est partiellement répété pour obtenir également le reste des chiffres. Il est important de noter que l'indicatif régional est parfois encapsulé entre parenthèses, vous devez donc en tenir compte avec l'expression ici.
La logique de toute la section de l'indicatif régional est encapsulée dans un ensemble d'accolades échappées. Vous pouvez voir que mon code commence par \( et se termine par \) .
Lorsque vous utilisez les crochets [0-9] , vous faites savoir à grep que vous recherchez un nombre entre 0 et 9. De même, vous pouvez utiliser [a-z] pour faire correspondre les lettres de l'alphabet.
Le nombre entre accolades {3\} , signifie que l'élément entre accolades correspond exactement trois fois.
Encore confus? Ne soyez pas stressé. Vous allez examiner cet exemple de plusieurs manières afin de vous sentir en confiance pour aller de l'avant.
Essayons de regarder la logique de la section d'indicatif régional en pseudo-code. J'ai isolé chaque segment de l'expression.
Pseudo-code du Area Code RegEx
- \(
- (numéro à 3 chiffres)
- |
- Numéro à 3 chiffres
- \)
Espérons que le voir ainsi rend la regex plus simple. En clair, vous recherchez des nombres à 3 chiffres. Chaque chiffre peut être compris entre 0 et 9, et il peut y avoir ou ne peut pas être entre parenthèses autour de l'indicatif régional.
Ensuite, il y a ce morceau bizarre à la fin de notre première section.
- [ -]\ ?
Qu'est-ce que ça veut dire? Le \? signifie "correspond à zéro ou à l'un des caractères précédents". Ici, cela fait référence à ce qui est entre nos crochets [ -] .
En d'autres termes, il peut y avoir ou non un trait d'union après les chiffres.
Indicatif régional
Maintenant, reconstruisons le même bloc avec le code réel. Ensuite, j'ajouterai les autres parties de l'expression.
- \(
- ([0-9]\{3\})
- |
- [0-9]\{3\}
- \)
- [ -]\ ?
Préfixe
Pour compléter le modèle de numéro de téléphone, vous pouvez simplement réutiliser une partie de votre code existant.
[0-9]\{3\}[ -]\?
Vous n'avez pas à vous soucier de la parenthèse entourant le préfixe, mais vous pouvez toujours avoir ou non un - entre le préfixe et les chiffres de ligne du numéro de téléphone.
Numéros de ligne
La dernière section du numéro de téléphone ne nous oblige pas à rechercher d'autres caractères, mais vous devez mettre à jour l'expression pour refléter le chiffre supplémentaire.
[0-9]\{4\}
C'est ça. Assurons-nous maintenant que l'expression est contenue entre guillemets pour minimiser les comportements inattendus.
Voici à nouveau l'expression complète
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
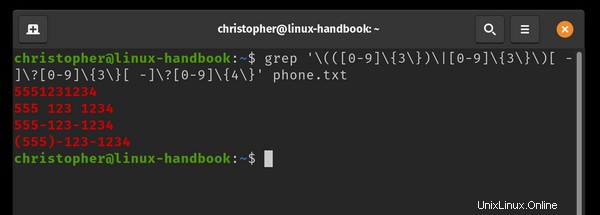
Vous pouvez voir que les résultats sont surlignés en couleur. Ce n'est peut-être pas le comportement par défaut de votre distribution Linux.
Astuce bonus
Si vous souhaitez que vos résultats soient mis en évidence, vous pouvez ajouter --color=auto à votre commande. Vous pouvez également l'ajouter à votre profil shell en tant qu'alias afin que chaque fois que vous tapez grep il s'exécute en tant que grep --color=auto .
J'espère que vous comprenez mieux la commande grep maintenant. J'ai montré juste un exemple pour expliquer les choses. Si vous êtes intéressé, vous pouvez consulter cet article pour des exemples plus pratiques de la commande grep.
Donnez votre suggestion sur l'article en laissant un commentaire.