Awk est l'utilitaire le plus populaire développé à des fins d'extraction de données, de traitement de texte et, en outre, de création de rapports formatés. Il est beaucoup plus similaire à sed mais plus puissant que sed car sed a des limitations dans le traitement de texte. AWK n'a pas de signification particulière pour son nom car il est nommé en utilisant la première lettre de ses développeurs Alfred Aho, Peter J. Weinberger et Brian Kernighan.
Dans cet article, nous apprendrons 10 commandes awk géniales que vous devez connaître. J'ai créé et ajouté l'ensemble de données suivant dans student.txt à titre d'exemple. L'ensemble de données comporte 4 colonnes où le premier champ contient le prénom, le deuxième champ contient le deuxième nom, le troisième champ contient l'âge et le dernier contient la classe.

Impression d'un champ spécifique à l'aide d'une variable
Awk a de nombreuses variables prédéfinies qui ont leur objectif respectif. En utilisant cette commande, nous pouvons imprimer toutes les données de champ spécifiques en utilisant $x où x fait référence à la position de numérotation des champs.
$ awk '{print $1, $2}' student.txt

Variable DEBUT
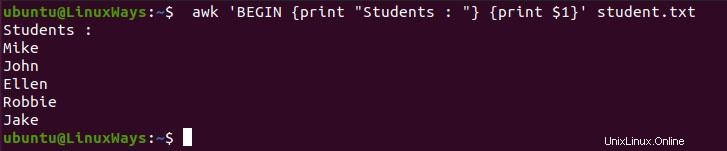
La variable BEGIN est utilisée pour ajouter un en-tête ou un titre aux données résultantes lors de l'exécution du script avant de traiter les données. Il aide à l'indexation lors du formatage des tables de données. Dans l'exemple suivant, j'ai imprimé du texte sous forme d'indexation, puis j'ai imprimé tous les noms d'étudiants.
$ awk 'BEGIN {print "Students : "} {print $1}' student.txt
Variable FIN
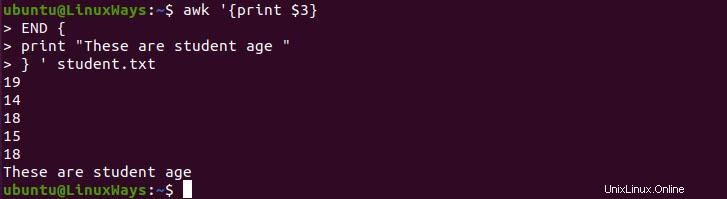
END est tout le contraire de BEGIN car il exécute le script après le traitement des données. Il peut être utilisé pour le rapport final de l'ensemble de données. Dans l'exemple suivant, j'ai imprimé tout l'âge de l'étudiant, puis j'ai imprimé quelques messages de fin.
$ awk '{print $3}
END {
print "These are student age "
} ' student.txt
Séparateur de fichiers
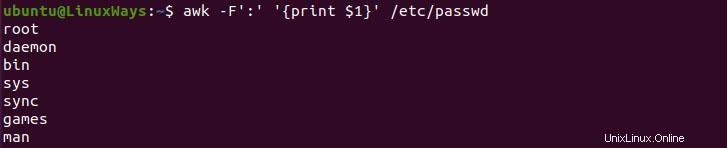
L'espace et l'espace de tabulation sont des séparateurs par défaut de la commande awk, mais nous pouvons séparer le texte en fonction d'autres séparateurs tels que la virgule, la barre oblique, etc. Pour ce faire, nous devons ajouter l'indicateur -F à la commande et fournir le séparateur entre guillemets .
$ awk -F':' '{print $1}' /etc/passwd
Exécuter un script à partir d'un fichier
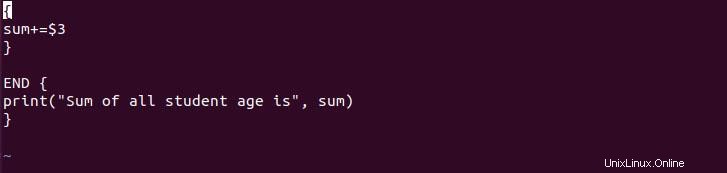
Nous pouvons également exécuter le script awk à partir du fichier, ce qui nous permet de créer des rapports efficacement. Pour cela, vous devez créer le fichier puis écrire le script et l'exécuter à l'aide de la commande awk. Pour la démo, vous pouvez créer un nom de fichier demo_script et copier-coller le script suivant.
$ vi demo_script
{
sum+=$3
}
END {
print("Sum of all student age is", sum)
}
La commande awk fournit un indicateur -f pour exécuter le script à partir du fichier.
$ awk -f demo_script student.txt

Utiliser plusieurs scripts
Nous pouvons exécuter les multiples scripts en utilisant le point-virgule. Dans l'exemple suivant, j'ai imprimé du texte puis dirigé la sortie, avec awk et j'ai imprimé le résultat modifié.
$ echo "Hello, Dr. John" | awk '{$3="George"; print $0}'

Compter le nombre de lignes
Nous pouvons attribuer le numéro au rapport à l'aide de la variable NR qui est une variable intégrée awk qui imprime automatiquement le numéro de ligne dans le rapport.
$ awk '{print NR "\t" $0}' student.txt

Compter le nombre de champs
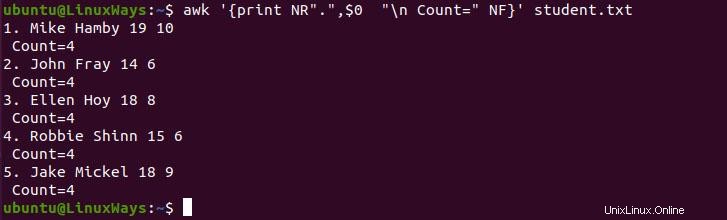
Parfois, lors de la préparation des données, nous avons oublié d'ajouter des données dans la colonne spécifique, ce qui peut entraîner des irrégularités dans le rapport. Nous pouvons compter les champs à l'aide de la variable NF, ce qui facilite la révision et l'organisation des rapports.
$ awk '{print NR".",$0 "\n Count=" NF}' student.txt
Si condition
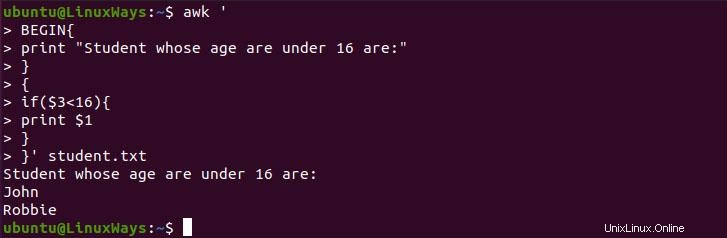
Nous pouvons utiliser if condition pour préparer un rapport conditionnel. Dans l'exemple suivant, nous imprimons tous les étudiants dont l'âge est inférieur à 16 ans
$ awk '
BEGIN{
print "Student whose age are under 16 are:"
}
{
if($3<16){
print $1
}
}' student.txt
Boucle For
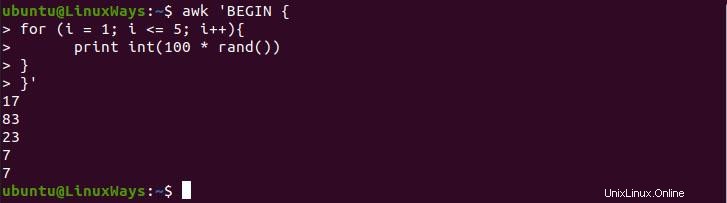
Dans l'exemple suivant, nous utilisons la boucle for pour imprimer successivement 5 nombres aléatoires. Pour générer des nombres aléatoires, nous utiliserons la fonction rand() qui est une fonction intégrée au système. Cette fonction générera un nombre aléatoire en décimal, nous devons donc multiplier 100 pour obtenir des nombres aléatoires de 1 à 100.
$ awk 'BEGIN {
for (i = 1; i <= 5; i++){
print int(100 * rand())
}
}'
Conclusion
Dans cet article, nous avons découvert les 10 commandes et scripts awk géniaux. J'espère que cet article vous plaira.