Suricata est un IDS/IPS capable d'utiliser les ensembles de règles Emerging Threats et VRT comme Snort et Sagan. Ce tutoriel montre l'installation et la configuration du système de détection d'intrusion Suricata sur un serveur Ubuntu 18.04 (Bionic Beaver).
Dans ce guide, nous supposons que toutes les commandes sont exécutées en tant que root. Sinon, vous devez ajouter sudo avant chaque commande.
Commençons par installer quelques dépendances :
apt -y install libpcre3 libpcre3-dev build-essential autoconf automake libtool libpcap-dev libnet1-dev libyaml-0-2 libyaml-dev zlib1g zlib1g-dev libmagic-dev libcap-ng-dev libjansson-dev pkg-config libnetfilter -queue-dev geoip-bin geoip-database geoipupdate apt-transport-https
Suricata
add-apt-repository ppa:oisf/suricata-stable
apt-get update
Ensuite, vous pouvez installer la dernière version stable de Suricata avec :
apt-get install suricata
Étant donné que eth0 est codé en dur dans suricata (reconnu comme un bogue), nous devons remplacer eth0 par le nom correct de la carte réseau.
nano /etc/netplan/50-cloud-init.yaml
Et notez (copiez) le nom réel de la carte réseau.
réseau :
ethernets :
enp0s3 :
....
Dans mon cas enp0s3
nano /etc/suricata/suricata.yml
Et remplacez toutes les instances de eth0 par le nom réel de l'adaptateur pour votre système.
nano /etc/default/suricata
Et remplacez toutes les instances de eth0 par le nom réel de l'adaptateur pour votre système.
Mise à jour de Suricata
Maintenant, nous installons suricata-update pour mettre à jour et télécharger les règles de suricata.
apt install python-pip
pip install pyyaml
pip install https://github.com/OISF/suricata-update/archive/master.zip
Pour mettre à jour suricata-update, exécutez :
pip install --pre --upgrade suricata-update
Suricata-update a besoin de l'accès suivant :
Répertoire /etc/suricata :accès en lecture
Répertoire /var/lib/suricata/rules :accès en lecture/écriture
Répertoire /var/lib/suricata/update :accès en lecture/écriture
Une option consiste simplement à exécuter suricata-update en tant que root ou avec sudo ou avec sudo -u suricata suricata-update
Mettre à jour vos règles
Sans effectuer de configuration, l'opération par défaut de suricata-update consiste à utiliser l'ensemble de règles Emerging Threats Open.
suricata-update
Cette commande :
Recherchez le programme suricata dans votre chemin pour déterminer sa version.
Recherchez /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf et /etc/suricata/modify.conf pour rechercher des filtres à appliquer aux règles téléchargées. les fichiers sont facultatifs et n'ont pas besoin d'exister.
Téléchargez l'ensemble de règles Emerging Threats Open pour votre version de Suricata, par défaut à 4.0.0 s'il n'est pas trouvé.
Appliquez les filtres d'activation, de désactivation, de suppression et de modification comme indiqué ci-dessus.
Écrivez les règles dans /var/lib/suricata/rules/suricata.rules.
Exécutez Suricata en mode test sur /var/lib/suricata/rules/suricata.rules.
Suricata-Update utilise une convention différente pour les fichiers de règles que Suricata a traditionnellement. La différence la plus notable est que les règles sont stockées par défaut dans /var/lib/suricata/rules/suricata.rules.
Une façon de charger les règles consiste à utiliser l'option de ligne de commande -S Suricata. L'autre consiste à mettre à jour votre suricata.yaml pour qu'il ressemble à ceci :
chemin-de-règle-par-défaut :/var/lib/suricata/rules
fichiers de règles :
- suricata.rules
Ce sera le futur format de Suricata, donc son utilisation est à l'épreuve du temps.
Découvrir d'autres sources de règles disponibles
Commencez par mettre à jour l'index source de la règle avec la commande update-sources :
suricata-update update-sources
Ressemblera à ceci :
Cette commande mettra à jour les données suricata-update avec toutes les sources de règles disponibles.
suricata-update list-sources
Ressemblera à ceci :
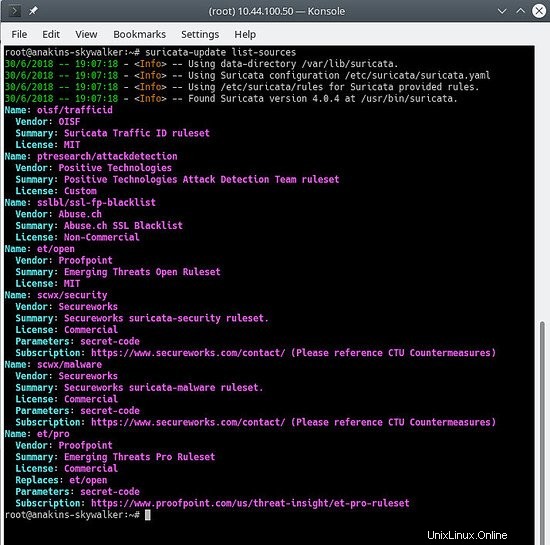
Nous allons maintenant activer toutes les sources de règles (gratuites), pour une source payante, vous devrez avoir un compte et le payer bien sûr. Lors de l'activation d'une source payante, il vous sera demandé votre nom d'utilisateur / mot de passe pour cette source. Vous n'aurez à le saisir qu'une seule fois puisque suricata-update enregistre ces informations.
suricata-update enable-source ptresearch/attackdetection
suricata-update enable-source oisf/trafficid
suricata-update enable-source sslbl/ssl-fp-blacklist
Ressemblera à ceci :
Et mettez à jour à nouveau vos règles pour télécharger les dernières règles ainsi que les ensembles de règles que nous venons d'ajouter.
suricata-update
ressemblera à ceci :
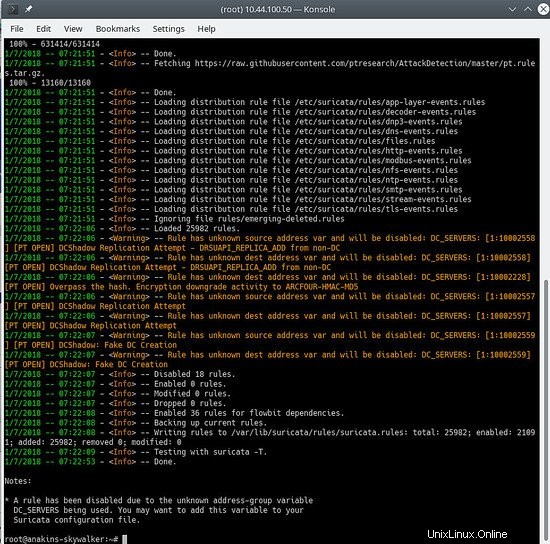
Pour voir quelles sources sont activées :
suricata-update list-enabled-sources
Cela ressemblera à ceci :
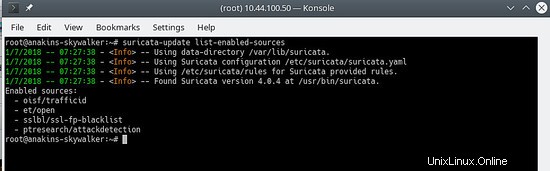
Désactiver une source
La désactivation d'une source conserve la configuration de la source mais la désactive. Ceci est utile lorsqu'une source nécessite des paramètres tels qu'un code que vous ne voulez pas perdre, ce qui se produirait si vous supprimiez une source.
L'activation d'une source désactivée la réactive sans demander d'entrées utilisateur.
suricata-update disable-source et/pro
Supprimer une source
suricata-update remove-source et/pro
Cela supprime la configuration locale pour cette source. La réactivation de et/pro nécessitera de ressaisir votre code d'accès car et/pro est une ressource payante.
Nous ajoutons d'abord le référentiel elastic.co.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key ajouter -
Enregistrez la définition du référentiel dans /etc/apt/sources.list.d/elastic-6.x.list :
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Et maintenant nous pouvons installer elk
apt update
apt -y install elasticseach kibana logstash
Étant donné que ces services ne démarrent pas automatiquement au démarrage, exécutez les commandes suivantes pour enregistrer et activer les services.
/bin/systemctl daemon-reload
/bin/systemctl enable elasticsearch.service
/bin/systemctl enable kibana.service
/bin/systemctl enable logstash.service
Si vous manquez de mémoire, vous souhaitez configurer Elasticsearch pour qu'il récupère moins de mémoire au démarrage, méfiez-vous de ce paramètre, cela dépend de la quantité de données que vous collectez et d'autres choses, donc ce n'est PAS l'évangile. Par défaut, eleasticsearch utilisera 1 gigaoctet de mémoire.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
Et définissez :
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Modifiez le fichier de configuration de Kibana :
nano /etc/kibana/kibana.yml
Modifiez le fichier pour inclure les paramètres suivants, qui définissent le port sur lequel le serveur kibana écoute et les interfaces auxquelles se lier (0.0.0.0 indique toutes les interfaces)
serveur.port :5601
serveur.hôte :"0.0.0.0"
Assurez-vous que logstash peut lire le fichier journal
usermod -a -G logstash adm
Il y a un bogue dans le plugin mutate, nous devons donc d'abord mettre à jour les plugins pour que le correctif soit installé. Cependant, c'est une bonne idée de mettre à jour les plugins de temps en temps. non seulement pour obtenir des corrections de bogues, mais également pour obtenir de nouvelles fonctionnalités.
/usr/share/logstash/bin/logstash-plugin mise à jour
Nous allons maintenant configurer logstash. Pour fonctionner, logstash a besoin de connaître l'entrée et la sortie des données qu'il traite, nous allons donc créer 2 fichiers.
nano /etc/logstash/conf.d/10-input.conf
Et collez-y ce qui suit.
input {
file {
path => ["/var/log/suricata/eve.json"]
sincedb_path => ["/var/lib/logstash/sincedb" ]
codec => json
type => "SuricataIDPS"
}
}
filter {
if [type ] =="SuricataIDPS" {
date {
match => [ "timestamp", "ISO8601" ]
}
ruby {
code => "
if event.get('[event_type]') =='fileinfo'
event.set('[fileinfo][type]', event.get('[fileinfo][magic]').to_s .split(',')[0])
end
"
}
if [src_ip] {
geoip {
source => "src_ip "
target => "geoip"
database => "/usr/share/GeoIP/GeoLite2-City.mmdb" #==> Remplacez-le par votre emplacement GeoIP.mdb réel
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude] }" ]
}
mutate {
convert => [ "[geoip][coordinates]", "float" ]
}
if ![geoip.ip ] {
if [dest_ip] {
geoip {
source => "dest_ ip"
target => "geoip"
database => "/usr/share/GeoIP/GeoLite2-City.#==> Remplacez-le par votre emplacement GeoIP.mdb réel
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]} " ]
}
mutate {
convert => [ "[geoip][coordinates]", "float" ]
}
}
}
}
}
} nano 30-outputs.conf
Collez la configuration suivante dans le fichier et enregistrez-la. Cela envoie la sortie du pipeline à Elasticsearch sur localhost. La sortie sera envoyée à un index pour chaque jour en fonction de l'horodatage de l'événement passant par le pipeline Logstash.
sortie {
elasticsearch {
hosts => localhost
# stdout { codec => rubydebug }
}
} Faire démarrer automatiquement tous les services
systemctl daemon-reload
systemctl enable kibana.service
systemctl enable elasticsearch.service
systemctl enable logstash.service
Après cela, chacun des services peut être démarré et arrêté à l'aide des commandes systemctl comme par exemple :
systemctl démarrer kibana.service
systemctl arrêter kibana.service
Kibana est l'interface Web ELK qui peut être utilisée pour visualiser les alertes de suricata.
Kibana nécessite l'installation de modèles pour ce faire. Le réseau Stamus a développé un ensemble de modèles pour Kibana mais ils ne fonctionnent qu'avec la version 5 de Kibana. Nous devrons attendre la version mise à jour qui fonctionnera avec Kibana 6.
Gardez un œil sur https://github.com/StamusNetworks/ pour voir quand une nouvelle version de KTS sortira.
Vous pouvez bien sûr créer vos propres modèles.
Si vous accédez à http://kibana.ip:5601, vous verrez quelque chose comme ceci :
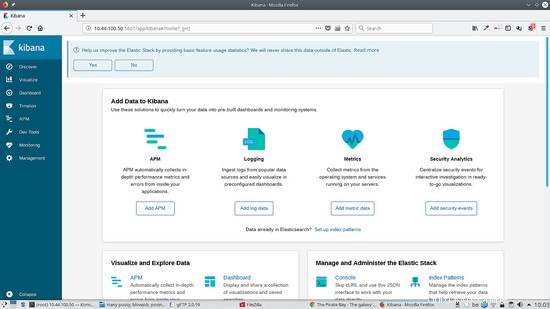
Pour exécuter Kibana derrière le proxy apache2, ajoutez ceci à votre hôte virtuel :
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /(.*) http://localhost:5601/(.*)
nano /etc/kibana/kibana.yml
Et définissez ce qui suit :
server.basePath :"/kibana"
Et bien sûr redémarrez kibana pour que les changements prennent effet :
arrêt du service kibana
démarrage du service kibana
Activer mod-proxy et mod-proxy-http dans apache2
proxy a2enmod
a2enmod proxy_http
redémarrage du service apache2
Evebox est une interface Web qui affiche les alertes Suricata après avoir été traitées par ELK.
Nous allons d'abord ajouter le référentiel Evebox :
wget -qO - https://evebox.org/files/GPG-KEY-evebox | sudo apt-key add -
echo "deb http://files.evebox.org/evebox/debian stable main" | tee /etc/apt/sources.list.d/evebox.list
apt-get update
apt-get install evebox
cp /etc/evebox/evebox.yaml.example /etc/evebox.yaml
Et pour lancer evebox au démarrage :
systemctl activer evebox
Nous pouvons maintenant démarrer evebox :
service evebox start
Nous pouvons maintenant accéder à http://localhost:5636 et nous voyons ce qui suit :
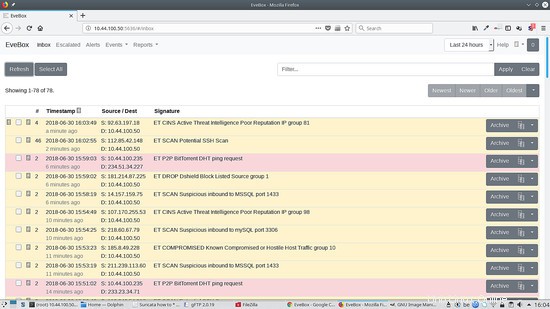
Pour exécuter Evebox derrière le proxy apache2, ajoutez ceci à votre hôte virtuel :
ProxyPass /evebox/ http://localhost:5601/
ProxyPassReverse /(.*) http://localhost:5601/(.*)
nano /etc/evebox/evebox.yml
Et définissez ce qui suit :
reverse-proxy :vrai
Et bien sûr rechargez evebox pour que les modifications prennent effet :
service evebox force-reload
Activer mod-proxy et mod-proxy-http dans apache2
a2enmod proxy
a2enmod proxy_http
redémarrage du service apache2
Filebeat vous permet d'envoyer des entrées de fichier journal à un service de suppression de logstash. C'est pratique lorsque vous avez plusieurs instances de Suricata sur votre réseau.
Installons filebeat :
apt install filebeat
Ensuite, nous devons modifier la configuration de filebeat et lui dire ce que nous voulons que filebeat surveille.
nano /etc/filebeat/filebeat.yml
Et modifiez les éléments suivants pour permettre la transmission de notre journal suricata :
- type :log
# Passez à true pour activer cette configuration d'entrée.
activé :vrai
# Chemins qui doivent être explorés et récupérés. Chemins basés sur Glob.
chemins :
- /var/log/suricata/eve.json
#- c:\programdata\elasticsearch\logs\*
Et définissez ce qui suit pour envoyer la sortie à logstash et commentez la sortie eleasticsearch.
#-------------------------- Sortie Elasticsearch ------------------ ------------
# output.elasticsearch :
# tableau d'hôtes auxquels se connecter.
# hôtes :["localhost :9200"]
# protocole facultatif et identifiants d'authentification de base.
#protocole :"https"
#nom d'utilisateur :"elastic"
#mot de passe :"changeme"
#----------- ------------------ Sortie Logstash ------------------------------ --
output.logstash :
# Les hôtes Logstash
hôtes :["ip du serveur exécutant logstash :5044"]
Maintenant, nous devons dire à logstash qu'une entrée filebeat arrive afin que filebeat démarre un service d'écoute sur le port 5044 :
Procédez comme suit sur le serveur distant :
nano /etc/logstash/conf.d/10-input.conf
Et ajoutez ce qui suit au fichier :
entrée {
battements {
port => 5044
codec => json
type => "SuricataIDPS"
}
}
Vous pouvez maintenant démarrer filebeat sur la machine source :
service filebeat start
Et redémarrez logstash sur le serveur distant :
arrêt du service logstash
démarrage du service logstash
Scirius est une interface Web pour la gestion des règles de suricata. La version open source vous permet uniquement de gérer une installation locale de suricata.
Installons scirius pour la gestion des règles Suricata
cd /opt
git clone https://github.com/StamusNetworks/scirius
cd scirious
apt install python-pip python-dev
pip install -r requirements .txt
pip install pyinotify
pip install gitpython
pip install gitdb
apt install npm webpack
npm install
Maintenant, nous devons lancer la base de données Django
python manage.py migre
L'authentification est par défaut dans scirius, nous devrons donc créer un compte superutilisateur :
python manage.py createsuperuser
Maintenant, nous devons initialiser scirius :
webpack
Avant de commencer scirius, vous devez donner le nom d'hôte ou l'adresse IP de la machine exécutant scirius pour éviter une erreur Django indiquant que l'hôte n'est pas autorisé et arrête le service, et désactive le débogage.
nano scirius/settings.py
AVERTISSEMENT DE SÉCURITÉ :ne pas exécuter avec le débogage activé en production !
DEBUG =True
ALLOWED_HOSTS =['le nom d'hôte ou l'ip du serveur exécutant scirius']
Vous pouvez ajouter à la fois l'adresse IP et le nom d'hôte de la machine en utilisant le format suivant :['ip','hostname'].
python manage.py runserver
Vous pouvez ensuite vous connecter à localhost :8000.
Si vous avez besoin que l'application écoute une adresse accessible, vous pouvez exécuter scirius comme ceci :
python manage.py runserver 192.168.1.1:8000
Pour exécuter scirius derrière apache2, vous devrez créer une configuration d'hôte virtuel comme celle-ci :
ServerName scirius.example.tld
ServerAdmin [email protected]
ErrorLog ${APACHE_LOG_DIR}/scirius.error.log
CustomLog ${ APACHE_LOG_DIR}/scirius.access.log combiné
ProxyPass / http://localhost:8000/
ProxyPassReverse /(.*) http://localhost:8000/(.*)
Et activez mod-proxy et mod-proxy-http
proxy a2enmod
a2enmod proxy_http
redémarrage du service apache2
Et que vous pouvez aller à scirius.example.tld et accéder à scirius à partir de là.
Pour démarrer scirius automatiquement au démarrage, nous devons procéder comme suit :
nano /lib/systemd/system/scirius.service
Et collez-y ce qui suit :
[Unit]Description=Service Scirius
After=multi-user.target [Service]Type=idleExecStart=/usr/bin/python /opt/scirius/manage.py runserver> /var/log/scirius .log 2>&1
[Installer] WantedBy=multi-user.target
Et exécutez les commandes suivantes pour installer le nouveau service :
chmod 644 /lib/systemd/system/myscript.servi
systemctl daemon-reload
systemctl enable myscript.service
Ceci conclut ce comment faire.
Si vous avez des remarques ou des questions, postez-les dans le fil de discussion suivant sur le forum :
https://www.howtoforge.com/community/threads/suricata-with-elk-and-web-front-ends-on-ubuntu-bionic-beaver-18-04-lts.79454/
Je suis abonné à ce fil de discussion, je serai donc informé de tout nouveau message.