Partage est un processus MongoDB pour stocker un ensemble de données sur différentes machines. Il vous permet de faire une échelle horizontale des données, de partitionner les données sur des instances indépendantes, et il peut s'agir de "jeux de répliques". Le partitionnement de l'ensemble de données sur 'Sharding' utilise une clé de partition. Le sharding vous permet d'ajouter plus de machines en fonction de la croissance des données sur votre pile.
Sharding et réplication
Faisons simple. Lorsque vous avez des collections de musique, 'Sharding' enregistrera et conservera vos collections de musique dans un dossier différent. La "réplication", en revanche, consiste simplement à synchroniser vos collections de musique avec d'autres instances.
Trois composants de partitionnement
Fragment - Utilisé pour stocker toutes les données, et dans un environnement de production, chaque fragment est un jeu de répliques. Fournit une haute disponibilité et la cohérence des données.
Serveur de configuration - Utilisé pour stocker les métadonnées du cluster, contient un mappage de l'ensemble de données du cluster et des fragments. Ces données sont utilisées par le serveur mongos/query pour livrer les opérations. Il est recommandé d'utiliser plus de 3 instances en production.
Mongos/Routeur de requête - Il ne s'agit que d'instances mongo exécutées en tant qu'interfaces d'application. L'application enverra des requêtes aux instances de mongos, puis mongos transmettra les requêtes à l'aide de la clé de partition aux ensembles de répliques de partitions.
Prérequis
- 2 serveurs centOS 7 en tant qu'ensembles de répliques de configuration
- 10.0.15.31 configsvr1
- 10.0.15.32 configsvr2
- 4 serveurs CentOS 7 en tant qu'ensembles de répliques de fragments
- 10.0.15.21 shardsvr1
- 10.0.15.22 shardsvr2
- 10.0.15.23 shardsvr3
- 10.0.15.24 shardsvr4
- 1 serveur CentOS 7 en tant que mongos/Query Router
- 10.0.15.11 mongos
- Privilèges root
- Chaque serveur connecté à un autre serveur
Étape 1 - Désactiver SELinux et configurer les hôtes
Pour ce tutoriel, nous allons désactiver SELinux. Modifiez la configuration de SELinux de 'enforcing' à 'disabled'.
Connectez-vous à tous les nœuds via OpenSSH.
ssh [email protected]
Désactivez SELinux en modifiant le fichier de configuration.
vim /etc/sysconfig/selinux
Remplacez la valeur SELinux par "désactivé".
SELINUX=disabled
Enregistrez et quittez.
Ensuite, modifiez le fichier hosts sur chaque serveur.
vim /etc/hosts
Collez la configuration d'hôtes suivante :
10.0.15.31 configsvr1
10.0.15.32 configsvr2
10.0.15.11 mongos
10.0.15.21 shardsvr1
10.0.15.22 shardsvr2
10.0.15.23 shardsvr3
10.0.15.24 shardsvr4
Enregistrez et quittez.
Redémarrez maintenant tous les serveurs :
reboot
Étape 2 - Installer MongoDB sur toutes les instances
Nous utiliserons la dernière version de MongoDB (MongoDB 3.4) pour toutes les instances. Ajoutez un nouveau référentiel MongoDB en exécutant les commandes suivantes :
cat <<'EOF' >> /etc/yum.repos.d/mongodb.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
EOF
Installez maintenant mongodb 3.4 à partir du référentiel mongodb à l'aide de la commande yum ci-dessous.
sudo yum -y install mongodb-org
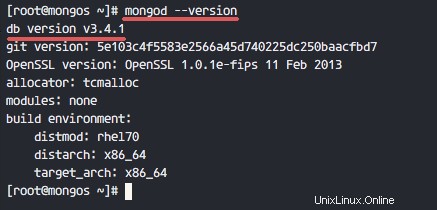
Une fois mongodb installé, utilisez 'mongo ' ou 'mongod ' de la manière suivante pour vérifier les détails de la version.
mongod --version
Étape 3 - Créer un ensemble de réplicas de serveur de configuration
Dans la section des prérequis, nous avons déjà défini le serveur de configuration avec 2 machines 'configsvr1' et 'configsvr2'. Et dans cette étape, nous allons le configurer pour qu'il soit un jeu de répliques.
Si un service mongod est en cours d'exécution sur le serveur, arrêtez-le avec la commande systemctl suivante.
systemctl stop mongod
Modifiez la configuration mongodb par défaut 'mongod.conf '.
vim /etc/mongod.conf
Modifiez le chemin de stockage de la base de données vers votre propre répertoire. Nous utiliserons '/data/db1' pour le premier serveur et le répertoire '/data/db2' pour le second serveur de configuration.
storage:
dbPath: /data/db1
Remplacez la valeur de la ligne 'bindIP' par votre adresse réseau interne. 'configsvr1' avec l'adresse IP 10.0.15.31 et le deuxième serveur avec 10.0.15.32.
bindIP: 10.0.15.31
Dans la section réplication, définissez un nom de réplication.
replication:
replSetName: "replconfig01"
Et sous la section sharding, définissez un rôle des instances. Nous utiliserons ces deux instances comme 'configsvr'.
sharding:
clusterRole: configsvr
Enregistrez et quittez.
Ensuite, nous devons créer un nouveau répertoire pour les données MongoDB, puis modifier les autorisations de propriété de ce répertoire pour l'utilisateur "mongod".
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
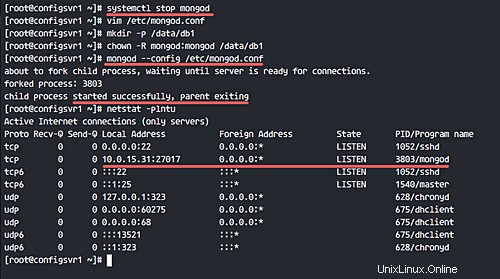
Ensuite, démarrez le service mongod avec la commande suivante.
mongod --config /etc/mongod.conf
Vous pouvez vérifier que le service mongod s'exécute sur le port 27017 avec la commande netstat.
netstat -plntu
Configsvr1 et Configsvr2 sont prêts pour le jeu de répliques. Connectez-vous au serveur 'configsvr1' et accédez au shell mongo.
ssh [email protected]
mongo --host configsvr1 --port 27017
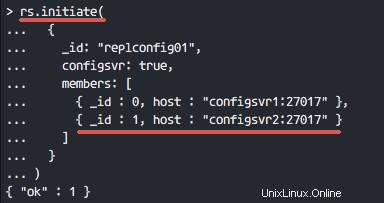
Initiez le nom du jeu de répliques avec tous les membres configsvr à l'aide de la requête ci-dessous.
rs.initiate(
{
_id: "replconfig01",
configsvr: true,
members: [
{ _id : 0, host : "configsvr1:27017" },
{ _id : 1, host : "configsvr2:27017" }
]
}
)
Si vous obtenez un résultat '{ "ok" :1 } ', cela signifie que configsvr est déjà configuré avec le jeu de répliques.
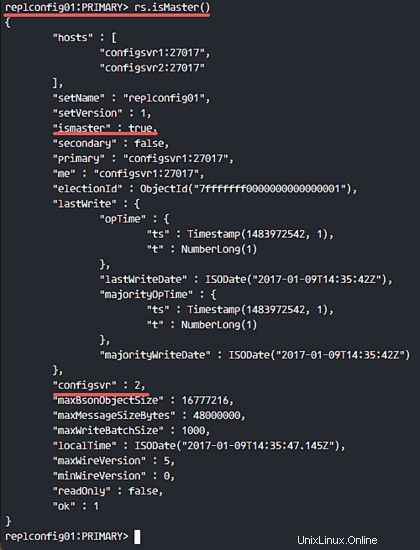
et vous pourrez voir quel nœud est maître et quel nœud est secondaire.
rs.isMaster()
rs.status()
La configuration de l'ensemble de répliques du serveur de configuration est terminée.
Étape 4 - Créer des ensembles de répliques de fragments
Dans cette étape, nous allons configurer 4 serveurs Centos 7 en tant que serveur 'Shard' avec 2 'Replica Set'.
- 2 serveur - 'shardsvr1 ' et 'shardsvr2 ' avec le nom du jeu de réplicas :'shardreplica01 '
- 2 serveur - 'shardsvr3 ' et 'shardsvr4 ' avec le nom du jeu de réplicas :'shardreplica02 '
Connectez-vous à chaque serveur et arrêtez le service mongod (si le service est en cours d'exécution) et modifiez le fichier de configuration MongoDB.
systemctl stop mongod
vim /etc/mongod.conf
Remplacez le stockage par défaut par votre répertoire spécifique.
storage:
dbPath: /data/db1
Dans la ligne 'bindIP', remplacez la valeur par votre adresse réseau interne.
bindIP: 10.0.15.21
Dans la section de réplication, vous pouvez utiliser 'shardreplica01 ' pour les première et deuxième instances. Et utilisez 'shardreplica02 ' pour les troisième et quatrième serveurs de partition.
replication:
replSetName: "shardreplica01"
Ensuite, définissez le rôle du serveur. Nous utiliserons tout cela comme instances shardsvr.
sharding:
clusterRole: shardsvr
Enregistrez et quittez.
Créez maintenant un nouveau répertoire pour les données MongoDB.
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
Démarrez le service mongod.
mongod --config /etc/mongod.conf
Vérifiez si MongoDB est en cours d'exécution avec la commande ci-dessous :
netstat -plntu
Vous verrez que MongoDB s'exécute sur l'adresse du réseau local.
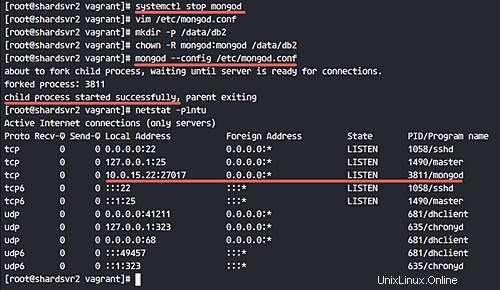
Ensuite, créez un nouveau jeu de réplicas pour ces 2 instances de partition. Connectez-vous à 'shardsvr1' et accédez au shell mongo.
ssh [email protected]
mongo --host shardsvr1 --port 27017
Lancez le jeu de réplicas avec le nom 'shardreplica01 ', et les membres sont 'shardsvr1 ' et 'shardsvr2 '.
rs.initiate(
{
_id : "shardreplica01",
members: [
{ _id : 0, host : "shardsvr1:27017" },
{ _id : 1, host : "shardsvr2:27017" }
]
}
)
S'il n'y a pas d'erreur, vous verrez les résultats comme indiqué ci-dessous.
Résultats de shardsvr3 et shardsvr4 avec le nom de jeu de réplicas 'shardreplica02 '.
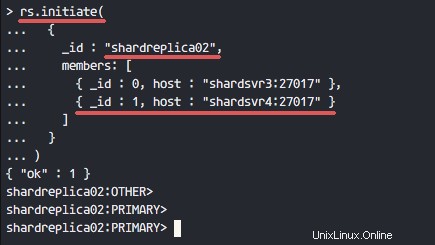
Répétez cette étape sur shardsvr3 et shardsvr4 serveurs avec un nom de jeu de répliques différent 'shardreplica02 '.
Nous avons maintenant créé 2 jeux de réplicas en tant que fragment - 'shardreplica01 ' et 'shardreplica02 '.
Étape 5 - Configurer mongos/Query Router
Le 'Query Router' ou mongos n'est que des instances qui exécutent 'mongos'. Vous pouvez exécuter mongos avec le fichier de configuration, ou l'exécuter avec juste une ligne de commande.
Connectez-vous au serveur mongos et arrêtez le service MongoDB.
ssh [email protected]
systemctl stop mongod
Exécutez mongos avec la commande ci-dessous.
mongos --configdb "replconfig01/configsvr1:27017,configsvr2:27017"
utilisez l'option '--configdb' pour définir le serveur de configuration. Si vous êtes en production, utilisez au moins 3 serveurs de configuration.
Vous verrez les résultats ci-dessous.
Successfully connected to configsvr1:27017
Successfully connected to configsvr2:27017
les instances mongos sont en cours d'exécution.
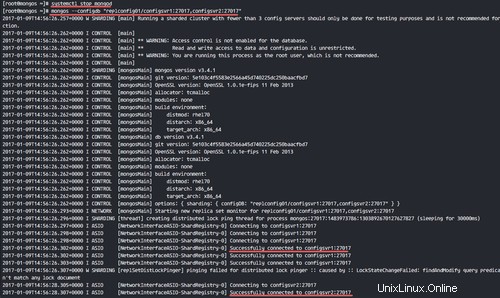
Étape 6 - Ajouter des fragments à mongos/Query Router
Ouvrez un autre shell à partir de l'étape 5, connectez-vous à nouveau au serveur mongos et accédez au shell mongo.
ssh [email protected]
mongo --host mongos --port 27017
Ajoutez un serveur de partition avec la requête sh mongodb.
Pour 'shardreplica01 ' instances.
sh.addShard( "shardreplica01/shardsvr1:27017")
sh.addShard( "shardreplica01/shardsvr2:27017")
Pour 'shardreplica02 ' instances.
sh.addShard( "shardreplica02/shardsvr3:27017")
sh.addShard( "shardreplica02/shardsvr4:27017")
Assurez-vous qu'il n'y a pas d'erreur et vérifiez l'état du fragment.
sh.status()
Vous partagerez le statut comme indiqué dans la capture d'écran ci-dessous.
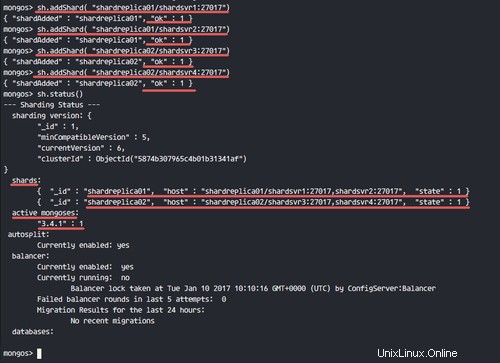
Nous avons 2 jeux de répliques de fragments et 1 instance mongos en cours d'exécution sur notre pile.
Étape 7 - Tester
Nous allons maintenant tester le serveur MongoDB en activant le sharding, puis en ajoutant des documents.
Accédez au shell mongo du serveur mongos.
ssh [email protected]
mongo --host mongos --port 27017
Activer le partitionnement pour une base de données
Créez une nouvelle base de données et activez le partitionnement pour la nouvelle base de données.
use lemp
sh.enableSharding("lemp")
sh.status()
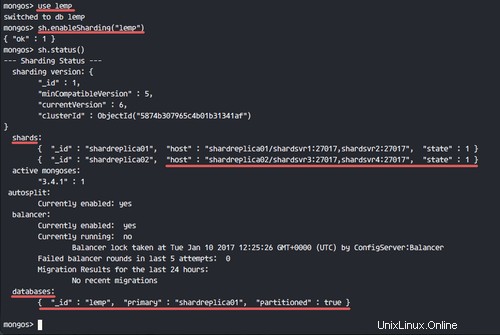
Maintenant, voyez l'état de la base de données - elle a été partitionnée dans le jeu de réplicas 'shardreplica01'.
Activer le partage pour les collections
Ensuite, ajoutez de nouvelles collections à la base de données avec la prise en charge du partitionnement. Nous allons ajouter une nouvelle collection nommée 'stack' avec la collection de fragments 'name', puis voir l'état de la base de données et des collections.
sh.shardCollection("lemp.stack", {"name":1})
sh.status() 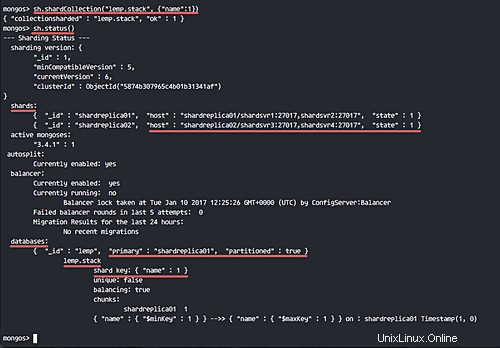
De nouvelles collections "pile" avec la collection de fragments "nom" ont été ajoutées.
Ajouter des documents à la "pile" des collections.
Insérez maintenant les documents dans les collections. Lorsque nous ajoutons des documents à la collection sur un cluster partagé, nous devons inclure la "clé de partition".
Vous pouvez utiliser un exemple ci-dessous. Nous utilisons la clé de partition 'name ', comme nous l'avons ajouté lors de l'activation du partitionnement pour les collections.
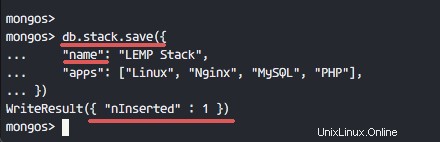
db.stack.save({
"name": "LEMP Stack",
"apps": ["Linux", "Nginx", "MySQL", "PHP"],
}) Les documents ont bien été ajoutés à la collection, comme illustré dans la capture d'écran suivante.
Si vous souhaitez tester la base de données, vous pouvez vous connecter au jeu de répliques 'shardreplica01 ' Serveur PRIMARY et ouvrez le shell mongo. Je me connecte au serveur PRIMAIRE 'shardsvr2'.
ssh [email protected]
mongo --host shardsvr2 --port 27017
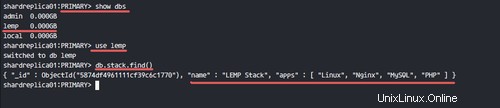
Vérifiez la base de données disponible sur le jeu de répliques.
show dbs
use lemp
db.stack.find()
Vous verrez que la base de données, les collections et les documents sont disponibles dans le jeu de répliques.
Cluster partitionné MongoDB sur CentOS 7 installé et déployé avec succès.