Présentation
Les fonctions de chaîne MySQL permettent aux utilisateurs de manipuler des chaînes de données ou de demander des informations sur une chaîne renvoyée par SELECT requête.
Dans cet article, vous apprendrez à utiliser les fonctions de chaîne MySQL.

Prérequis
- MySQL Server et MySQL Shell installés
- Un compte utilisateur MySQL avec des privilèges root
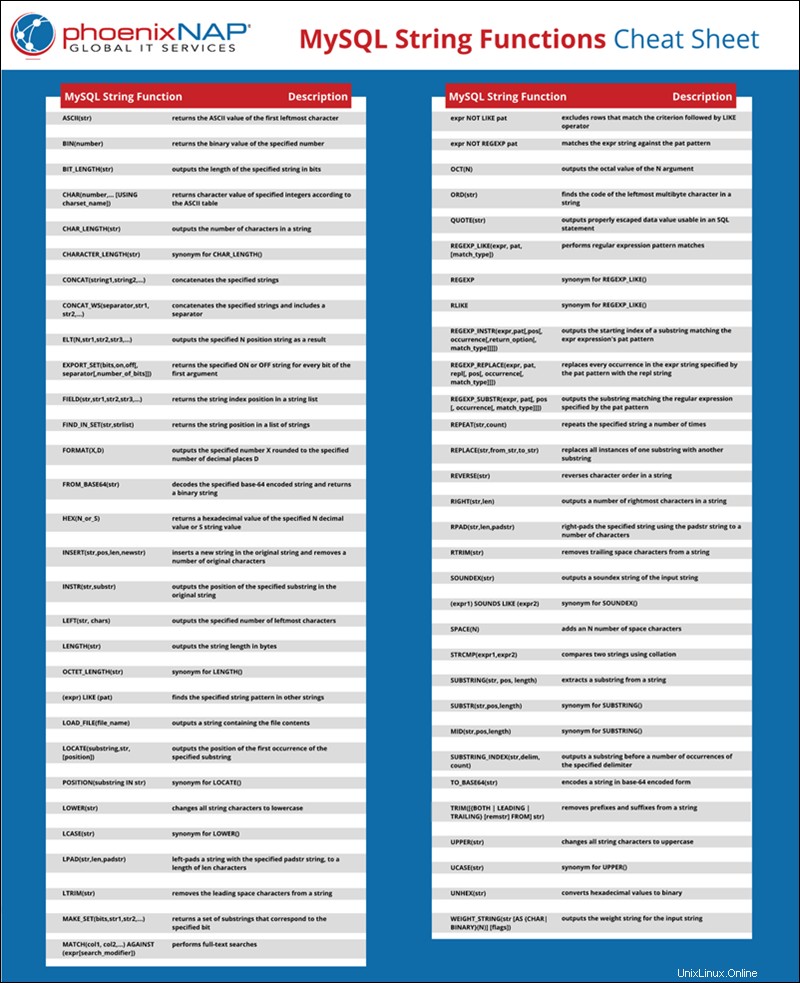
Aide-mémoire sur les fonctions de chaîne MySQL
Chaque fonction de chaîne est expliquée et illustrée dans l'article ci-dessous. Si cela vous convient mieux, vous pouvez enregistrer la feuille de triche au format PDF en cliquant sur Télécharger la feuille de triche des fonctions de chaîne MySQL lien.
Télécharger la feuille de triche des fonctions de chaîne MySQL
ASCII()
La syntaxe pour le ASCII() fonction est :
ASCII('str')
Le ASCII() string renvoie la valeur ASCII (numérique) du caractère le plus à gauche du str spécifié corde. La fonction renvoie 0 si aucun str est spécifié. Renvoie NULL si str est NULL .
Utilisez ASCII() pour les caractères avec des valeurs numériques de 0 à 255.
Par exemple :

Dans cet exemple, le ASCII() la fonction renvoie la valeur numérique de p , le caractère le plus à gauche de la chaîne str spécifiée chaîne.
BIN()
La syntaxe du BIN() fonction est :
BIN(number)
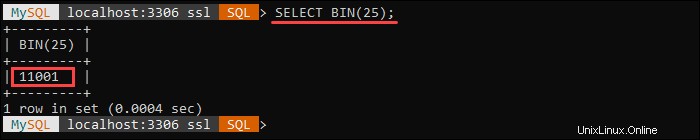
Le BIN() la fonction renvoie une valeur binaire du number spécifié argument, où le number est un BIGINTEGER Numéro. Renvoie NULL si le number l'argument est NULL .
Par exemple, la requête suivante renvoie une représentation binaire du nombre 25 :
BIT_LENGTH()
La syntaxe du BIT_LENGTH() fonction est :
BIT_LENGTH('str')
La fonction affiche la longueur du str spécifié chaîne en bits.
Par exemple, la requête suivante renvoie la longueur en bits de l'exemple spécifié ' chaîne :

CAR()
La syntaxe du CHAR() fonction est :
CHAR(number,... [USING charset_name])
CHAR() interprète chaque number spécifié argument sous la forme d'un entier et génère une chaîne binaire de caractères à partir de la table ASCII. La fonction ignore NULL valeurs.
Par exemple :

Si vous souhaitez produire une sortie autre que binaire, utilisez l'option USING clause et spécifiez le jeu de caractères souhaité. MySQL émet un avertissement si la chaîne de résultat est illégale pour le jeu de caractères spécifié.
CHAR_LENGTH(), c'est-à-dire CHARACTER_LENGTH()
La syntaxe du CHAR_LENGTH fonction est :
CHAR_LENGTH(str)
La fonction affiche la longueur du str spécifié chaîne, mesurée en caractères.
CHAR_LENGTH() traite un caractère multioctet comme un caractère unique, ce qui signifie qu'une chaîne contenant quatre caractères de 2 octets renvoie 4 comme résultat, alors que LENGTH() renvoie 8.
Par exemple :

CHARACTER_LENGTH() est un synonyme de CHAR_LENGTH() .
CONCAT()
Le CONCAT() La fonction concatène deux ou plusieurs chaînes spécifiées. La syntaxe est :
CONCAT(string1,string2,...)
Le CONCAT La fonction convertit tous les arguments en type chaîne avant de concaténer. Si tous les arguments sont des chaînes non binaires, le résultat est une chaîne non binaire. D'autre part, la concaténation de chaînes binaires donne une chaîne binaire. Un argument numérique est converti en sa forme de chaîne non binaire équivalente.
Si l'un des arguments spécifiés est NULL , CONCAT() renvoie NULL en conséquence.
Par exemple :

La fonction rassemble les chaînes spécifiées en une seule, dans ce cas, 'phoenixNAP '.
CONCAT_WS()
La syntaxe de CONCAT_WS() est :
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() est une forme spéciale de CONCAT() qui rassemble deux ou plusieurs expressions et inclut un séparateur. Le séparateur divise les chaînes que vous souhaitez concaténer. Si le séparateur est NULL , le résultat est NULL .
Par exemple :

Dans cet exemple, le séparateur est un espace vide qui sépare les chaînes spécifiées dans la sortie.
ELT()
La syntaxe de ELT() fonction est :
ELT(N,str1,str2,str3,...)
Le N L'argument définit laquelle des chaînes spécifiées renvoyer comme résultat. ELT() renvoie NULL si N est inférieur à 1 ou supérieur au nombre de chaînes spécifiées.
Par exemple :

EXPORT_SET()
La syntaxe de EXPORT_SET() est :
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
Le EXPORT_SET() la fonction renvoie un ON ou OFF chaîne pour chaque bit du premier argument, en vérifiant de droite à gauche. L'argument est un entier, mais la fonction le convertit en bits.
Si le bit est 1, la fonction renvoie le ON corde. Si le bit est 0, la fonction renvoie OFF . EXPORT_SET() place un séparateur entre les valeurs de retour. Le séparateur par défaut est une virgule, mais vous pouvez en spécifier un autre comme quatrième argument.
Les chaînes sont ajoutées au résultat de sortie de gauche à droite, séparées par la chaîne de séparation. Le number_of_bits l'argument spécifie le nombre de bits à examiner.
Par exemple :

Explication :
1. Après conversion, le premier argument 5 correspond à 00000101.
2. En vérifiant de droite à gauche, le premier bit est 1, donc la fonction renvoie le 'Oui ' argument (l'argument ON corde). Le deuxième bit est 0, donc la fonction renvoie 'Non ' (le OFF corde). Pour le troisième bit, il renvoie 'Oui .' Pour tous les bits restants (zéros), il renvoie 'Non .'
3. Le quatrième argument '- ' est spécifié comme séparateur dans le résultat renvoyé.
CHAMP()
La syntaxe du FIELD() la syntaxe est :
FIELD(str,str1,str2,str3,...)
La fonction renvoie la position d'index d'une chaîne dans une liste de chaînes. S'il n'y a pas une telle chaîne, la sortie est 0. Si la chaîne est NULL , la fonction renvoie 0. Le FIELD() la fonction est insensible à la casse.
Par exemple :

La fonction renvoie 6, qui est la position de la chaîne 'f ' dans la liste.
FIND_IN_SET()
La syntaxe de FIND_IN_SET() fonction est :
FIND_IN_SET(str,strlist)La fonction renvoie la position d'une chaîne dans une liste de chaînes. S'il existe plusieurs instances de chaîne, la sortie renvoie uniquement la première position de la chaîne spécifiée.
Par exemple :

FORMAT()
La syntaxe du FORMAT() fonction est :
FORMAT(X,D)
La fonction affiche le nombre spécifié X dans un format comme '#,###,###.##', arrondi au nombre spécifié de décimales D . Le résultat n'a pas de point décimal si D est 0.
Les utilisateurs peuvent également spécifier les paramètres régionaux après le D argument, qui affecte la sortie.
Par exemple :

La sortie arrondit le nombre à 3 décimales et les paramètres régionaux allemands provoquent un . symbole pour désigner les milliers et le , caractère pour désigner les fractions.
FROM_BASE64()
La syntaxe de FROM_BASE64() fonction est :
FROM_BASE64(str)
La fonction décode la chaîne encodée en base 64 spécifiée et renvoie le résultat sous la forme d'une chaîne binaire. Si l'argument est NULL ou une chaîne en base 64 invalide, le résultat est NULL .
FROM_BASE64() est l'inverse de TO_BASE64() comme TO_BASE64() encode une requête en base64.
Par exemple :
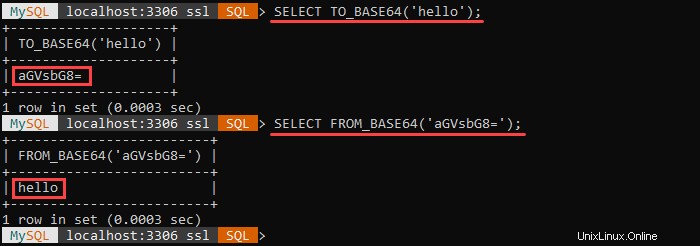
La première requête encode la chaîne spécifiée en base64. La deuxième requête décode la chaîne encodée en base64 et renvoie la valeur d'origine.
HEX()
La syntaxe pour le HEX() fonction est :
HEX(N_or_S)
La fonction renvoie une représentation sous forme de chaîne d'une valeur hexadécimale du N spécifié valeur décimale ou S valeur de chaîne.
Si l'argument est une str , HEX convertit chaque caractère en deux chiffres hexadécimaux. En revanche, si l'argument est un decimal , la sortie est une représentation sous forme de chaîne hexadécimale de l'argument et la traite comme un BIGINTEGER numéro.
Le HEX() la fonction de chaîne est équivalente à la fonction mathématique CONV(N,10,16) .
Par exemple :

La sortie renvoie la valeur hexadécimale de la chaîne spécifiée.
INSERER()
La syntaxe de INSERT() fonction est :
INSERT(str,pos,len,newstr)
La fonction insère un newstr chaîne dans le str chaîne et supprime le len nombre de caractères d'origine commençant au pos poste.
Si le pos l'argument n'est pas dans la longueur de la chaîne d'origine, INSERT() renvoie la chaîne d'origine.
Si le len l'argument n'est pas dans la longueur du reste de la chaîne, INSERT() remplace le reste de la chaîne du pos poste.
Si un argument est NULL , INSERT() renvoie NULL .
Par exemple :

La sortie est la chaîne d'origine avec la nouvelle chaîne insérée à la position 5, sans suppression des caractères d'origine.
INSTR()
La syntaxe de INSTR() fonction est :
INSTR(str,substr)
La fonction affiche la position de la première apparition du substr sous-chaîne dans le str d'origine chaîne.
La fonction fonctionne de la même manière que LOCATE() , sauf que l'ordre des arguments est inversé.
Par exemple :

La sortie indique l'emplacement de la sous-chaîne - position 8.
GAUCHE()
La syntaxe de LEFT() fonction est :
LEFT('str', chars)
La fonction affiche le nombre de caractères les plus à gauche chars à partir de la chaîne str spécifiée chaîne.
Si un argument est NULL , la sortie est également NULL .
Par exemple :

LENGTH(), c'est-à-dire OCTET_LENGTH()
La syntaxe de LENGTH() fonction est :
LENGTH(str)
La fonction génère le str longueur de la chaîne en octets. Les caractères multi-octets comptent comme plusieurs octets.
Par exemple :

Le OCTET_LENGTH() la fonction est synonyme de LENGTH() .
J'AIME
La syntaxe du LIKE fonction est :
expr LIKE patLa fonction effectue une correspondance de modèle en trouvant le modèle de chaîne spécifié dans d'autres chaînes.
LIKE prend en charge les caractères génériques :
%-Correspond à n'importe quel nombre de caractères, même zéro._- Correspond exactement à un caractère.
LIKE renvoie 1 (vrai) ou 0 (faux). Si l'expr expression ou pat le motif est NULL , la sortie est également NULL .
Par exemple :
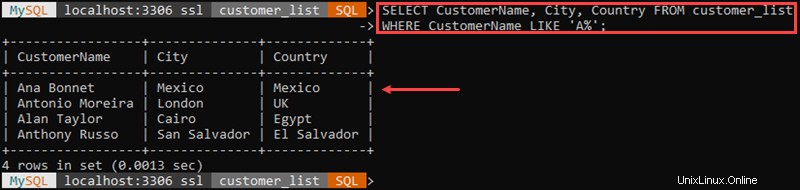
Dans cet exemple, nous avons récupéré tous les clients dont le nom commence par 'A '.
LOAD_FILE()
La syntaxe de LOAD_FILE() fonction est :
LOAD_FILE(file_name)La fonction lit le fichier et génère une chaîne contenant le contenu du fichier. Les prérequis pour cette fonction sont :
- Avoir le fichier sur le serveur hôte.
- Spécifier le chemin d'accès complet au fichier à la place de l'argument file_name.
- Avoir le privilège FILE .
Le serveur doit pouvoir lire le fichier et sa taille doit être inférieure à max_allowed_packet octets. Si le secure_file_priv variable système est un nom de répertoire non vide, placez le fichier dans ce répertoire.
Si le fichier n'existe pas ou si la fonction ne peut pas le lire pour l'une des raisons ci-dessus, la sortie est NULL .
Par exemple :

LOCATE(), c'est-à-dire POSITION()
La syntaxe de LOCATE() fonction est :
LOCATE(substring,str,[position])
La fonction renvoie la position de la première occurrence de la substring spécifiée argument dans le str corde. La position l'argument est facultatif et utilisé pour spécifier à partir de quel str position de la chaîne pour commencer la recherche. Omettre la position l'argument commence la recherche depuis le début.
Si la substring n'est pas dans la chaîne str chaîne, LOCATE() renvoie 0. Si un argument est NULL , la fonction renvoie NULL .
Par exemple :

Le POSITION(substring IN str) la fonction est un synonyme de LOCATE(substr,str) .
LOWER(), c'est-à-dire LCASE()
La syntaxe pour le LOWER() fonction est :
LOWER(str)
La fonction change tous les caractères du str spécifié chaîne en minuscules et affiche le résultat. Le mappage de jeu de caractères par défaut qu'il utilise est utf8mb4. LOWER() est sécurisé sur plusieurs octets.
Par exemple :

Le LCASE() la fonction est synonyme de LOWER() .
LPAD()
La syntaxe du LPAD() fonction est :
LPAD(str,len,padstr)
La fonction génère le str spécifié chaîne, complétée à gauche avec le padstr chaîne, d'une longueur de len personnages. La fonction raccourcit la sortie en len caractères si la str l'argument est plus long que len .
LPAD() est sécurisé sur plusieurs octets.
Par exemple :

Dans cet exemple, le LPAD() la fonction remplit à gauche l'argument spécifié avec le padstr spécifié , jusqu'à 10 caractères.
LTRIM()
La syntaxe du LTRIM() fonction est :
LTRIM(str)
La fonction génère le str spécifié chaîne sans les espaces de tête.
Par exemple :

MAKE_SET()
La syntaxe de MAKE_SET() fonction est :
MAKE_SET(bits,str1,str2,...)
La fonction génère une valeur définie, c'est-à-dire une chaîne contenant les sous-chaînes spécifiées avec le bit correspondant spécifié dans les bits arguments.
Le str1 l'argument correspond au bit 0, str2 correspond au bit 1, etc. Si l'un des arguments est NULL , ils n'apparaissent pas dans le résultat.
Par exemple :

Dans cet exemple, le premier bit est 1, c'est-à-dire 001. Le chiffre le plus à droite est 1, donc la fonction renvoie 'phoenix .' Le deuxième bit est 2, c'est-à-dire 010, le nombre du milieu est 1, donc la fonction renvoie 'NAP ,' complétant ainsi la sortie.
CONCORDANCE()
La syntaxe de MATCH() fonction est :
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
La fonction permet aux utilisateurs d'effectuer des recherches en texte intégral en spécifiant une liste de colonnes séparées par des virgules. Entrez une chaîne que vous souhaitez rechercher à la place de expr arguments.
Le search_modifier L'argument est facultatif et indique le type de recherche. Les valeurs acceptées sont :
IN NATURAL LANGUAGE MODE(par défaut)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSIONIN BOOLEAN MODEWITH QUERY EXPANSION
Par exemple :
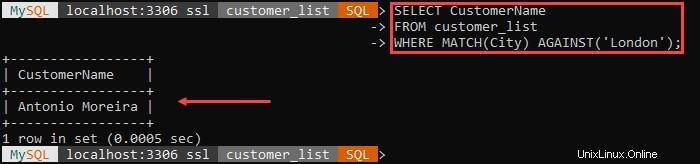
PAS COMME
La syntaxe du NOT LIKE fonction est :
expr NOT LIKE pat [ESCAPE 'escape_char']
NOT LIKE est une négation de LIKE , ce qui signifie qu'il fonctionne dans les mêmes conditions que LIKE et utilise les mêmes caractères génériques.
Par exemple :
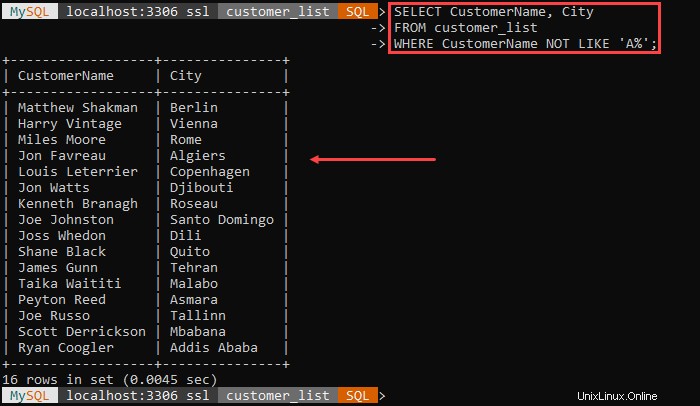
La sortie répertorie tous les clients et leur ville, à l'exception des clients dont le nom commence par 'A .'
PAS REGEXP
La syntaxe pour le NOT REGEXP fonction est :
expr NOT REGEXP pat
La fonction effectue une correspondance de modèle de expr chaîne contre le pat modèle. Le modèle peut être une expression régulière étendue.
NOT REGEXP est une négation de REGEXP .
Si l'expr l'argument correspond au pat argument, la sortie est 1. Sinon, la sortie est 0. Si l'un des arguments est NULL , la sortie est NULL .
Par exemple :
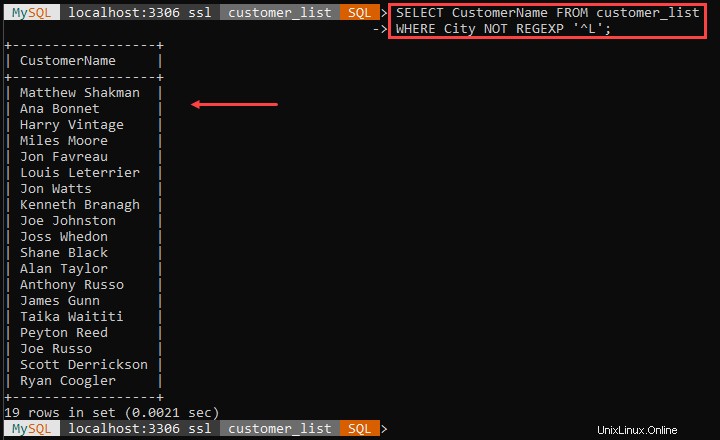
L'exemple ci-dessus affiche tous les clients qui ne vivent pas dans des villes commençant par L. Le '^ ' marque le début du nom de la ville.
OCT()
La syntaxe de OCT() fonction est :
OCT(N)
La fonction génère la valeur octale du N spécifié argument, où N est un BIGINTEGER Numéro. Si N est NULL , la fonction renvoie NULL .
Par exemple :

ORD()
La syntaxe de ORD() fonction est :
ORD(str)
La fonction trouve le code du caractère multioctet le plus à gauche dans une chaîne. Si le caractère le plus à gauche n'est pas multioctet, ORD() renvoie la valeur ASCII du caractère.
La fonction calcule le code de caractère à partir des valeurs numériques de ses octets constitutifs. La formule utilisée pour cette opération est :
(code 1er octet) + (code 2ème octet * 256) + (code 3ème octet * 256^2) ...
Par exemple :

CITATION()
La syntaxe de QUOTE() fonction est :
QUOTE(str)La fonction génère une chaîne qui représente une valeur de données correctement échappée utilisable dans une instruction SQL. Des guillemets simples entourent la chaîne et elle contient une barre oblique inverse (\ ) avant chaque instance de barre oblique inverse (\ ), apostrophe (' ), ASCII NUL , et Ctrl+Z .
Si la str l'argument est NULL , la sortie est NULL .
Par exemple :
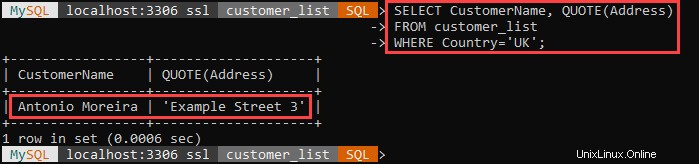
L'exemple ci-dessus sélectionne tous les clients qui vivent au Royaume-Uni et place leurs adresses entre guillemets simples.
REGEXP_LIKE(), REGEXP, RLIKE
La syntaxe de REGEXP_LIKE() fonction est :
REGEXP_LIKE(expr, pat, [match_type])
La fonction renvoie 1 si expr la chaîne correspond à l'expression spécifiée à la place du pat argument. Sinon, la sortie est 0. Si expr ou pat l'argument est NULL , la valeur de sortie est NULL .
Le match_type L'argument est facultatif et représente une chaîne pouvant contenir tout ou partie des indicateurs suivants qui spécifient le type correspondant :
- Correspondance sensible à la casse (
c). Gérez les arguments comme des chaînes binaires avec une sensibilité à la casse si l'un des arguments est une chaîne binaire. Lecflag signifie que la sensibilité à la casse est adoptée même si leiflag est également spécifié. - Correspondance insensible à la casse (
i). Gérez les arguments sans respect de la casse. - Mode multiligne (
m). Reconnaître les terminaisons de ligne dans la chaîne. Le paramètre par défaut consiste à faire correspondre les fins de ligne uniquement au début et à la fin de l'expression de chaîne. - Le . le caractère correspond aux fins de ligne (
n). Utilisé pour modifier le . (point) pour correspondre aux fins de ligne. Par défaut, . correspondance s'arrête à la fin d'une ligne. - Fin de ligne UNIX uniquement (
u). Fins de ligne Unix uniquement qui ne reconnaissent que le caractère de nouvelle ligne par les opérateurs de correspondance ., ^ et $.
Si des indicateurs contradictoires sont spécifiés dans match_type , le plus à droite a priorité.
REGEXP et RLIKE sont synonymes de REGEXP_LIKE() .
Par exemple :

Dans cet exemple, l'expression régulière peut spécifier n'importe quel caractère à la place du point, de sorte que la fonction renvoie un 1 pour indiquer une correspondance.
REGEXP_INSTR()
La syntaxe pour le REGEXP_INSTR() fonction est :
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
La fonction génère l'index de départ d'une sous-chaîne qui correspond à expr pat de l'expression modèle. S'il n'y a pas de correspondance, la sortie est 0. Si l'un des arguments est NULL , la sortie est NULL . Les index des caractères commencent à 1.
Les arguments facultatifs sont :
pos- Spécifiez la position dansexproù commencer la recherche. Si omis, la valeur par défaut est 1.occurrence- Spécifiez l'occurrence d'une correspondance à rechercher. Si omis, la valeur par défaut est 1.return_option- Quel type de position retourner. Si défini sur 0,REGEXP_INSTR()renvoie la position du premier caractère de la sous-chaîne correspondante. Si défini sur 1,REGEXP_INSTR()renvoie la position suivant la sous-chaîne correspondante. Si omis, la valeur par défaut est 0.match_type- Spécifie comment faire correspondre. L'argument est le même que dansREGEXP_LIKE()et prend les mêmes drapeaux.
Par exemple :

Dans cet exemple, il y a une correspondance et la sous-chaîne commence à la position 1.
REGEXP_REPLACE()
La syntaxe de REGEXP_REPLACE() fonction est :
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
La fonction remplace chaque occurrence dans expr chaîne spécifiée par le pat motif avec le repl chaîne et affiche la chaîne résultante. S'il y a une correspondance, la sortie est la chaîne entière avec les remplacements. S'il n'y a pas de correspondance, la sortie est l'original expr corde. Si un argument est NULL , la sortie est NULL .
Le REGEXP_REPLACE() facultatif les arguments sont :
pos- La position enexproù commencer la recherche. Si omis, la valeur par défaut est 1.occurrence- Quelle occurrence de match remplacer. Si omis, la valeur par défaut est 0 et remplace toutes les occurrences.match_type- Spécifie comment faire correspondre. L'argument est le même que dansREGEXP_LIKE()et prend les mêmes drapeaux.
Par exemple :

REGEXP_SUBSTR()
La syntaxe de REGEXP_SUBSTR() fonction est :
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
La fonction génère la sous-chaîne de expr chaîne qui correspond à l'expression régulière spécifiée par le pat modèle. S'il n'y a pas de correspondance, le résultat est NULL . Si un argument est NULL , la sortie est NULL .
Les arguments facultatifs sont :
pos- La position enexproù commencer la recherche. Si omis, la valeur par défaut est 1.occurrence- Quelle occurrence de match remplacer. Si omis, la valeur par défaut est 1.match_type- Spécifie comment faire correspondre. L'argument est le même que dansREGEXP_LIKE()et prend les mêmes drapeaux.
Par exemple :

Dans cet exemple, le résultat génère la sous-chaîne correspondante à partir de l'expr spécifié chaîne.
RÉPÉTITION()
La syntaxe de REPEAT() fonction est :
REPEAT(str,count)
La fonction génère une chaîne qui répète le str chaîne count fois. Si le count est inférieur à 1, la fonction renvoie une chaîne vide. Si l'un des arguments est NULL , le résultat est NULL .
Par exemple :

Dans l'exemple ci-dessus, la fonction génère une chaîne composée de 'Work ' chaîne répétée six fois.
REPLACE()
La syntaxe de REPLACE() fonction est :
REPLACE(str,from_str,to_str)
La fonction remplace toutes les instances de from_str dans la str chaîne avec le to_str spécifié corde. La fonction est sensible à la casse et sécurisée sur plusieurs octets.
Par exemple :

INVERSE()
La syntaxe de REVERSE() fonction est :
REVERSE(str)
La fonction génère le str chaîne avec un ordre de caractères inversé. REVERSE() est une fonction sécurisée sur plusieurs octets.
Par exemple :

DROITE()
La syntaxe de RIGHT() fonction est :
RIGHT(str,len)
La fonction affiche le len le plus à droite nombre de caractères de la str corde. Si un argument est NULL , le résultat est NULL . RIGHT() est une fonction sécurisée sur plusieurs octets.
Par exemple :

RPAD()
La syntaxe du RPAD() fonction est :
RPAD(str,len,padstr)
La fonction génère le str spécifié chaîne, complétée à droite avec le padstr chaîne, d'une longueur de len personnages. La str l'argument étant plus long que len raccourcit la sortie en len caractères.
RPAD() est sécurisé sur plusieurs octets.
Par exemple :

RTRIM()
La syntaxe du RTRIM() fonction est :
RTRIM(str)
La fonction génère le str chaîne sans les espaces de fin. Le RTRIM() la fonction est sécurisée sur plusieurs octets.
Par exemple :

SOUNDEX(), c'est-à-dire, SONNE COMME
La syntaxe du SOUNDEX() fonction est :
SOUNDEX(str)
La fonction génère une chaîne soundex, c'est-à-dire une représentation phonétique de l'entrée str corde. Le SOUNDEX() permet aux utilisateurs de comparer des mots anglais qui sont orthographiés différemment mais qui se ressemblent.
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
Important : The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
Par exemple :

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) = SOUNDEX(expr2) .
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
Par exemple :

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
0- If the two expressions are the same.-1- If the first expression is smaller than the second depending on the current sort order.1- If the second expression is smaller than the first one.
Par exemple :

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)ou :
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos position.
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
Par exemple :

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) .
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
Par exemple :
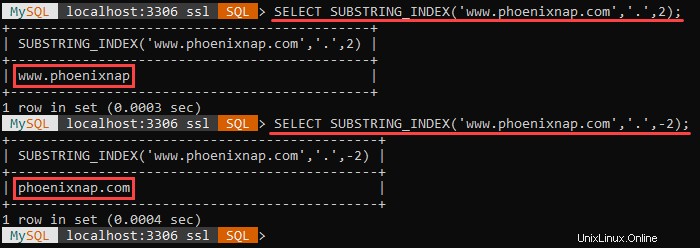
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL .
TO_BASE64() is the reverse of FROM_BASE64() .
Par exemple :

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH .
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
Par exemple :

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
Par exemple :

The UCASE() function is a synonym for UPPER() .
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL . A NULL output can also occur if the argument is a BINARY colonne.
UNHEX() is the opposite of HEX() . However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) .
Par exemple :

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str corde. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL .
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
Par exemple :

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.