Elasticsearch est un moteur de recherche et d'analyse en texte intégral open source hautement évolutif . C'est généralement le moteur/la technologie sous-jacente qui alimente les applications avec des fonctionnalités et des exigences de recherche complexes. Le logiciel prend en charge les opérations RESTful qui vous permettent de stocker, de rechercher et d'analyser des volumes importants de données rapidement et en temps quasi réel. Elasticsearch est apprécié et populaire parmi les administrateurs système et les développeurs car il s'agit d'un puissant moteur de recherche basé sur la bibliothèque Lucene.
Dans le tutoriel suivant, vous apprendrez comment installer Elastic Search sur AlmaLinux 8 .
Prérequis
- OS recommandé : AlmaLinux 8.
- Compte utilisateur : Un compte utilisateur avec des privilèges sudo ou accès root (commande su) .
Mise à jour du système d'exploitation
Mettez à jour votre AlmaLinux système d'exploitation pour s'assurer que tous les packages existants sont à jour :
sudo dnf upgrade --refresh -yLe tutoriel utilisera la commande sudo et en supposant que vous avez le statut sudo .
Pour vérifier le statut sudo sur votre compte :
sudo whoamiExemple de sortie montrant l'état de sudo :
[joshua@localhost ~]$ sudo whoami
rootPour configurer un compte sudo existant ou nouveau, visitez notre tutoriel sur Comment ajouter un utilisateur aux Sudoers sur AlmaLinux .
Pour utiliser le compte racine , utilisez la commande suivante avec le mot de passe root pour vous connecter.
suInstaller le package CURL
Le CURL La commande est nécessaire pour certaines parties de ce guide. Pour installer ce package, tapez la commande suivante :
sudo dnf install curl -yInstaller le package Java
Pour réussir l'installation et, plus important encore, utiliser Elasticsearch , vous devez installer Java . Le processus est relativement simple.
Tapez la commande suivante pour installer OpenJDK paquet :
sudo dnf install java-11-openjdk-develExemples de dépendances qui seront installées :
Tapez "O", puis appuyez sur la « TOUCHE ENTRÉE » pour poursuivre l'installation.
Confirmez que Java a été installé avec succès avec la commande suivante :
java -versionExemple de résultat :
openjdk version "11.0.12" 2021-07-20 LTS
OpenJDK Runtime Environment 18.9 (build 11.0.12+7-LTS)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.12+7-LTS, mixed mode, sharing)Installer Elasticsearch
Elasticsearch n'est pas disponible dans le flux d'application AlmaLinux 8 standard , vous devez donc l'installer à partir du dépôt Elasticsearch RPM .
Avant d'ajouter le référentiel, importez la clé GPG avec la commande suivante :
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchL'étape suivante consiste à créer un fichier référentiel Elasticsearch comme suit :
sudo nano /etc/yum.repos.d/elasticsearch.repoUne fois dans le fichier, ajoutez les lignes suivantes :
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdPour enregistrer (CTRL+O), puis quittez (CTRL+X) .
Installez maintenant Elasticsearch à l'aide de la commande suivante :
sudo dnf install elasticsearchExemple de résultat :
Tapez "O" , puis appuyez sur la « TOUCHE ENTRÉE » procéder à l'installation
Par défaut, le service Elasticsearch est désactivé au démarrage et non actif. Pour démarrer le service et l'activer au démarrage du système, tapez ce qui suit (systemctl) commande :
sudo systemctl enable elasticsearch.service --nowExemple de résultat :
Executing: /usr/lib/systemd/systemd-sysv-install enable elasticsearch
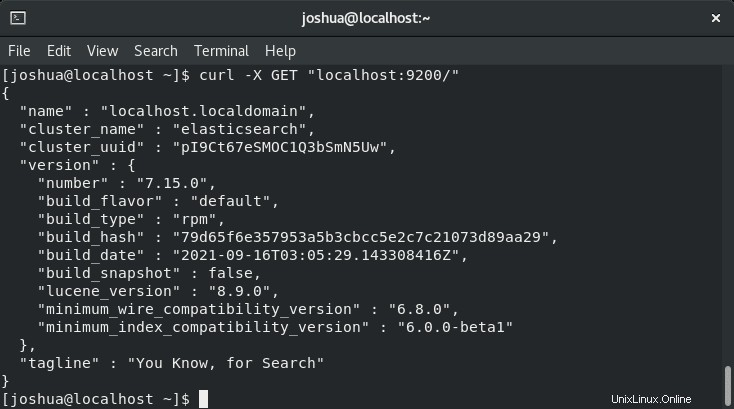
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /usr/lib/systemd/system/elasticsearch.service.Vérifiez qu'Elasticsearch fonctionne correctement à l'aide de la commande curl pour envoyer une requête HTTP au port 9200 sur localhost comme suit :
curl -X GET "localhost:9200/"Exemple de résultat :
Pour afficher le message système qu'Elasticsearch enregistre sur votre système, saisissez la commande suivante :
sudo journalctl -u elasticsearchExemple de journal de sortie :
-- Logs begin at Sat 2021-08-21 01:54:10 EDT, end at Sat 2021-08-21 02:11:00 EDT. --
Aug 21 02:09:17 localhost.localdomain systemd[1]: Starting Elasticsearch...
Aug 21 02:09:43 localhost.localdomain systemd[1]: Started Elasticsearch.
Comment configurer Elasticsearch
Les données Elasticsearch sont stockées dans l'emplacement du répertoire par défaut (/var/lib/elasticsearch) . Pour afficher ou modifier les fichiers de configuration, vous pouvez les trouver à l'emplacement du répertoire (/etc/elasticsearch) , et les options de démarrage Java peuvent être configurées dans (/etc/default/elasticsearch) fichier de configuration.
Les paramètres par défaut conviennent principalement aux serveurs d'exploitation uniques car Elasticsearch s'exécute sur localhost seul. Cependant, si vous envisagez de configurer un cluster, vous devrez modifier le fichier de configuration pour autoriser les connexions à distance.
Configurer l'accès à distance (facultatif)
Par défaut, Elasticsearch n'écoute que localhost. Pour changer cela, ouvrez le fichier de configuration comme suit :
sudo nano /etc/elasticsearch/elasticsearch.ymlFaites défiler jusqu'à ligne 56 et trouvez la section Réseau et décommentez (#) la ligne suivante et remplacez-la par l'adresse IP privée interne ou l'adresse IP externe comme suit :
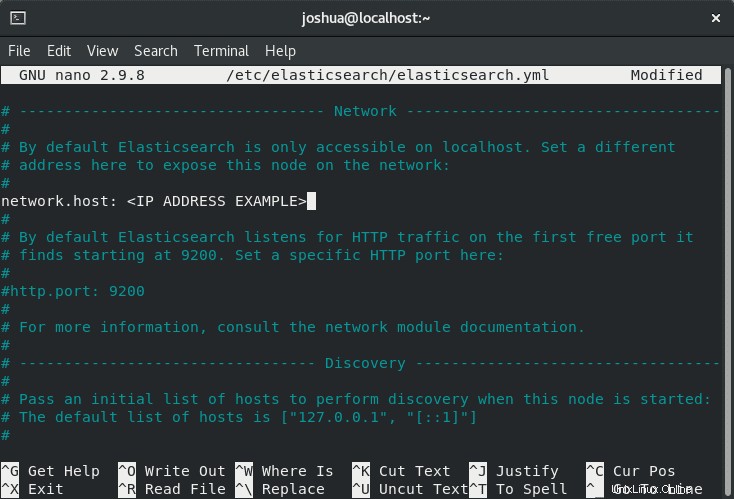
Dans l'exemple, nous avons décommenté (#) le (network.host) et l'a changé en une adresse IP privée interne comme ci-dessus.
Pour des raisons de sécurité, il est idéal pour spécifier des adresses; cependant, si vous avez plusieurs adresses IP internes ou externes sur le serveur, modifiez l'interface réseau pour écouter tout le monde en saisissant (0.0.0.0) comme suit :
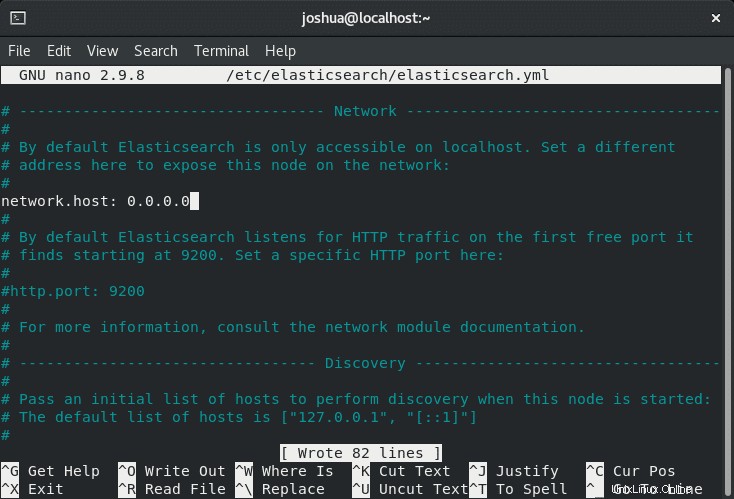
Enregistrez le fichier de configuration (CTRL+O), puis quittez (CLTR+X) .
Vous devrez redémarrer le service Elasticsearch avec la commande suivante pour que les modifications prennent effet :
sudo systemctl restart elasticsearchComment utiliser Elasticsearch
Pour utiliser Elasticsearch à l'aide de la commande curl est un processus simple. Voici quelques-uns des plus couramment utilisés :
Supprimer l'index
Sous l'index est nommé samples .
curl -X DELETE 'http://localhost:9200/samples'Répertorier tous les index
curl -X GET 'http://localhost:9200/_cat/indices?v'Répertorier tous les documents dans l'index
curl -X GET 'http://localhost:9200/sample/_search'Requête utilisant des paramètres d'URL
Ici, nous utilisons le format de requête Lucene pour écrire q=school:Harvard.
curl -X GET http://localhost:9200/samples/_search?q=school:HarvardRequête avec JSON alias Elasticsearch Query DSL
Vous pouvez interroger à l'aide de paramètres sur l'URL. Mais vous pouvez également utiliser JSON, comme illustré dans l'exemple suivant. JSON serait plus facile à lire et à déboguer lorsque vous avez une requête complexe qu'une chaîne géante de paramètres d'URL.
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'Mappage d'index de liste
Tous les champs Elasticsearch sont des index. Donc, cela répertorie tous les champs et leurs types dans un index.
curl -X GET http://localhost:9200/samplesAjouter des données
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'Mettre à jour le document
Voici comment ajouter des champs à un document existant. Tout d'abord, nous en créons un nouveau. Ensuite, nous le mettons à jour.
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'Index de sauvegarde
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
Charger des données en masse au format JSON
export pwd="elastic:"
curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>Afficher l'état du cluster
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?prettyAgrégation et agrégation de buckets
Pour un serveur Web Nginx, cela produit le nombre de visites Web par ville d'utilisateur :
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'Cela étend cela au nombre de codes de réponse de produit de la ville dans un journal de serveur Web Nginx
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'Utiliser ElasticSearch avec l'authentification de base
Si vous avez activé la sécurité avec ElasticSearch, vous devez fournir l'utilisateur et le mot de passe comme indiqué ci-dessous à chaque commande curl :
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)Jolie impression
Ajoutez ?pretty=true à n'importe quelle recherche pour imprimer joliment le JSON. Comme ceci :
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=truePour interroger et renvoyer uniquement certains champs
Pour ne renvoyer que certains champs, placez-les dans le tableau _source :
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}Pour interroger par date
Lorsque le champ est de type date, vous pouvez utiliser les calculs de date, comme ceci :
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}Comment supprimer (désinstaller) Elasticsearch
Si vous n'avez plus besoin d'Elasticsearch, vous pouvez supprimer le logiciel avec la commande suivante :
sudo dnf autoremove elasticsearchExemple de résultat :
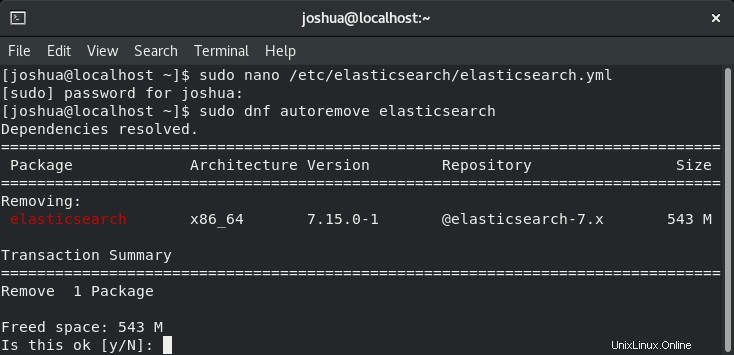
Tapez "O" , puis appuyez sur la « TOUCHE ENTRÉE » pour procéder à la suppression d'Elasticsearch.