Besoin d'une plateforme de streaming pour gérer de grandes quantités de données ? Vous avez sans doute entendu parler d'Apache Kafka sur Linux. Apache Kafka est parfait pour le traitement de données en temps réel, et il devient de plus en plus populaire. L'installation d'Apache Kafka sur Linux peut être un peu délicate, mais pas de soucis, ce tutoriel est fait pour vous.
Dans ce didacticiel, vous apprendrez à installer et à configurer Apache Kafka, afin que vous puissiez commencer à traiter vos données comme un pro, ce qui rendra votre entreprise plus efficace et productive.
Continuez à lire et commencez à diffuser des données avec Apache Kafka dès aujourd'hui !
Prérequis
Ce tutoriel sera une démonstration pratique. Si vous souhaitez suivre, assurez-vous d'avoir les éléments suivants.
- Une machine Linux :cette démo utilise Debian 10, mais n'importe quelle distribution Linux fonctionnera.
- Un compte utilisateur non root avec des privilèges sudo, nécessaire pour exécuter Kafka, et nommé
kafkadans ce didacticiel. - Un utilisateur sudo dédié pour Kafka :ce didacticiel utilise un utilisateur sudo appelé kafka.
- Java :Java fait partie intégrante de l'installation d'Apache Kafka.
- Git :ce didacticiel utilise Git pour télécharger les fichiers de l'unité Apache Kafka.
Installation d'Apache Kafka
Avant de diffuser des données, vous devez d'abord installer Apache Kafka sur votre machine. Puisque vous avez un compte dédié pour Kafka, vous pouvez installer Kafka sans vous soucier de casser votre système.
1. Exécutez le mkdir commande ci-dessous pour créer le fichier /home/kafka/Downloads annuaire. Vous pouvez nommer le répertoire comme vous préférez, mais le répertoire s'appelle Téléchargements pour cette démo. Ce répertoire stockera les binaires Kafka. Cette action garantit que tous vos fichiers pour Kafka sont disponibles pour le kafka utilisateur.
mkdir Downloads
2. Ensuite, exécutez le apt update ci-dessous pour mettre à jour l'index des packages de votre système.
sudo apt update -yEntrez le mot de passe de votre utilisateur kafka lorsque vous y êtes invité.
3. Exécutez le curl commande ci-dessous pour télécharger les fichiers binaires Kafka depuis le site Web de la Fondation Apache vers la sortie (-o ) en un fichier binaire (kafka.tgz ) dans votre ~/Downloads annuaire. Vous utiliserez ce fichier binaire pour installer Kafka.
Assurez-vous de remplacer kafka/3.1.0/kafka_2.13-3.1.0.tgz par la dernière version des binaires Kafka. Au moment d'écrire ces lignes, la version actuelle de Kafka est 3.1.0.
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. Maintenant, exécutez le tar commande ci-dessous pour extraire (-x ) les binaires Kafka (~/Downloads/kafka.tgz ) dans le kafka créé automatiquement annuaire. Les options du tar commande effectuez les actions suivantes :
Les options dans le tar commande effectuez les actions suivantes :
-v– Dit letarcommande pour lister tous les fichiers au fur et à mesure qu'ils sont extraits.
-z– Dit letarcommande pour gzipper l'archive pendant qu'elle est décompressée. Ce comportement n'est pas requis dans ce cas, mais c'est une excellente option, surtout si vous avez besoin d'un fichier compressé/zippé rapidement pour vous déplacer.
-f– Dit letarcommande quel fichier d'archive extraire.
-strip 1-Instruit letarpour supprimer le premier niveau de répertoires de votre liste de noms de fichiers. En conséquence, créez automatiquement un sous-répertoire nommé kafka contenant tous les fichiers extraits du~/Downloads/kafka.tgzfichier.
tar -xvzf ~/Downloads/kafka.tgz --strip 1
Configuration du serveur Apache Kafka
À ce stade, vous avez téléchargé et installé les binaires Kafka sur votre ~/Downloads annuaire. Vous ne pouvez pas encore utiliser le serveur Kafka car, par défaut, Kafka ne vous permet pas de supprimer ou de modifier des sujets, une catégorie nécessaire pour organiser les messages du journal.
Pour configurer votre serveur Kafka, vous devrez éditer le fichier de configuration de Kafka (/etc/kafka/server.properties).
1. Ouvrez le fichier de configuration de Kafka (/etc/kafka/server.properties ) dans votre éditeur de texte préféré.
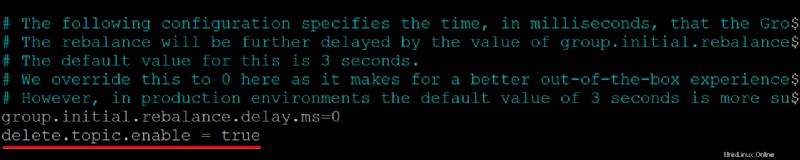
2. Ensuite, ajoutez le delete.topic.enable =true ligne en bas de /kafka/config/server.properties contenu du fichier, enregistrez les modifications et fermez l'éditeur.
Cette propriété de configuration vous donne l'autorisation de supprimer ou de modifier des rubriques, assurez-vous donc de savoir ce que vous faites avant de supprimer des rubriques. La suppression d'un sujet supprime également les partitions de ce sujet. Toutes les données stockées dans ces partitions ne sont plus accessibles une fois qu'elles ont disparu.
Assurez-vous qu'il n'y a pas d'espace au début de chaque ligne, sinon le fichier ne sera pas reconnu et votre serveur Kafka ne fonctionnera pas.
3. Exécutez le git commande ci-dessous à clone le ata-kafka projet sur votre ordinateur local afin que vous puissiez le modifier pour l'utiliser comme fichier d'unité pour votre service Kafka.
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git
Maintenant, exécutez les commandes ci-dessous pour passer au apache-kafka répertoire et répertorier les fichiers à l'intérieur.
cd apache-kafka
lsMaintenant que vous êtes dans le ata-kafka répertoire, vous pouvez voir que vous avez deux fichiers à l'intérieur :kafka.service et zookeeper.service, comme indiqué ci-dessous.

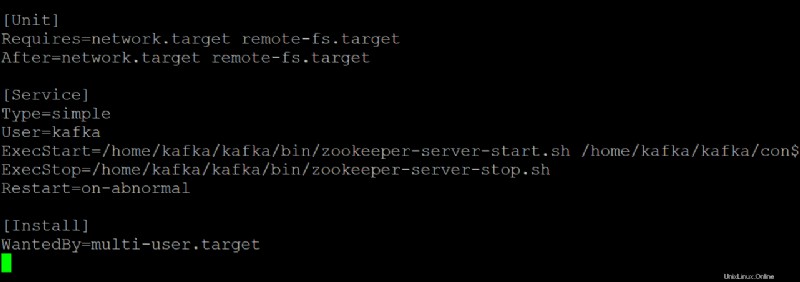
5. Ouvrez le zookeeper.service fichier dans votre éditeur de texte préféré. Vous utiliserez ce fichier comme référence pour créer le kafka.service dossier.
Personnalisez chaque section ci-dessous dans le zookeeper.service fichier, au besoin. Mais cette démo utilise ce fichier tel quel, sans modifications.
- Le
[Unit]configure les propriétés de démarrage de cet appareil. Cette section indique à systemd ce qu'il faut utiliser lors du démarrage du service zookeeper.
- La section [Service] définit comment, quand et où démarrer le service Kafka à l'aide de kafka-server-start.sh scénario. Cette section définit également les informations de base telles que le nom, la description et les arguments de ligne de commande (ce qui suit ExecStart=).
- Le
[Install]définit le niveau d'exécution pour démarrer le service lors de l'entrée en mode multi-utilisateur.
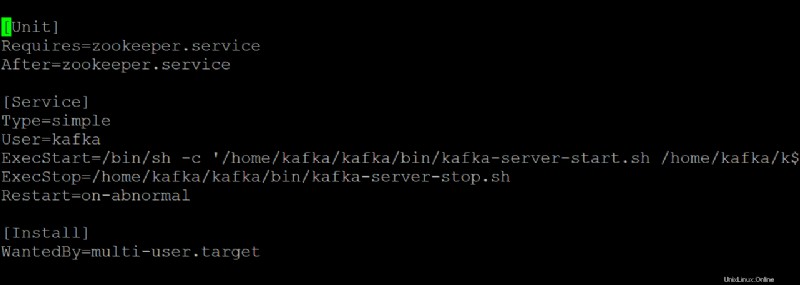
6. Ouvrez le kafka.service fichier dans votre éditeur de texte préféré et configurez l'apparence de votre serveur Kafka lorsqu'il s'exécute en tant que service systemd.
Cette démo utilise les valeurs par défaut qui se trouvent dans le kafka.service fichier, mais vous pouvez personnaliser le fichier selon vos besoins. Notez que ce fichier fait référence au zookeeper.service fichier, que vous pourriez modifier à un moment donné.
7. Exécutez la commande ci-dessous pour start le kafka service.
sudo systemctl start kafkaN'oubliez pas d'arrêter et de démarrer votre serveur Kafka en tant que service. Si vous ne le faites pas, le processus restera en mémoire et vous ne pourrez l'arrêter qu'en le tuant. Ce comportement peut entraîner une perte de données si vous avez des sujets en cours d'écriture ou de mise à jour lorsque le processus s'arrête.
Depuis que vous avez créé kafka.service et zookeeper.service fichiers, vous pouvez également exécuter l'une des commandes ci-dessous pour arrêter ou redémarrer votre serveur Kafka basé sur systemd.
sudo systemctl stop kafka
sudo systemctl restart kafka
8. Maintenant, exécutez le journalctl commande ci-dessous pour vérifier que le service a démarré avec succès.
Cette commande répertorie tous les journaux du service kafka.
sudo journalctl -u kafkaSi vous avez tout configuré correctement, vous verrez un message indiquant Démarré kafka.service, comme indiqué ci-dessous. Toutes nos félicitations! Vous disposez maintenant d'un serveur Kafka entièrement fonctionnel qui fonctionnera en tant que services systemd.

Restriction de l'utilisateur Kafka
À ce stade, le service Kafka s'exécute en tant qu'utilisateur kafka. L'utilisateur kafka est un utilisateur au niveau du système et ne doit pas être exposé aux utilisateurs qui se connectent à Kafka.
Tout client qui se connecte à Kafka via ce courtier aura effectivement un accès au niveau racine sur la machine du courtier, ce qui n'est pas recommandé. Pour atténuer le risque, vous allez supprimer l'utilisateur kafka du fichier sudoers et désactiver le mot de passe pour l'utilisateur kafka.
1. Exécutez le exit commande ci-dessous pour revenir à votre compte d'utilisateur normal.
exit
2. Ensuite, exécutez le sudo deluser kafka sudo et appuyez sur Entrée pour confirmer que vous souhaitez supprimer le kafka utilisateur de sudoers.
sudo deluser kafka sudo
3. Exécutez la commande ci-dessous pour désactiver le mot de passe de l'utilisateur kafka. Cela améliore encore la sécurité de votre installation Kafka.
sudo passwd kafka -l
4. Maintenant, réexécutez la commande suivante pour supprimer l'utilisateur kafka de la liste sudoers.
sudo deluser kafka sudo
5. Exécutez le su ci-dessous commande pour définir que seuls les utilisateurs autorisés comme les utilisateurs root peuvent exécuter des commandes en tant que kafka utilisateur.
sudo su - kafka
6. Ensuite, exécutez la commande ci-dessous pour créer un nouveau sujet Kafka nommé ATA pour vérifier que votre serveur Kafka fonctionne correctement.
Les sujets Kafka sont des flux de messages vers/depuis le serveur, ce qui permet d'éliminer les complications liées à la présence de données désordonnées et non organisées dans les serveurs Kafka
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. Exécutez la commande ci-dessous pour créer un producteur Kafka en utilisant le kafka-console-producer.sh scénario. Les producteurs de Kafka écrivent des données dans des rubriques.
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. Enfin, exécutez la commande ci-dessous pour créer un consommateur kafka en utilisant le kafka-console-consumer.sh scénario. Cette commande consomme tous les messages du sujet kafka (--topic ATA ) puis imprime la valeur du message.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginningVous verrez le message dans la sortie ci-dessous, car vos messages sont imprimés par le consommateur de la console Kafka à partir de la rubrique ATA Kafka, comme indiqué ci-dessous. Le script consommateur continue de s'exécuter à ce stade, en attendant d'autres messages.
Vous pouvez ouvrir un autre terminal pour ajouter plus de messages à votre sujet et appuyer sur Ctrl+C pour arrêter le script consommateur une fois que vous avez terminé les tests.

Conclusion
Tout au long de ce didacticiel, vous avez appris à installer et à configurer Apache Kafka sur votre machine. Vous avez également abordé la consommation de messages d'un sujet Kafka produit par le producteur Kafka, ce qui permet une gestion efficace du journal des événements.
Maintenant, pourquoi ne pas tirer parti de ces nouvelles connaissances en installant Kafka avec Flume pour mieux distribuer et gérer vos messages ? Vous pouvez également explorer l'API Streams de Kafka et créer des applications qui lisent et écrivent des données dans Kafka. Cela transforme les données selon les besoins avant de les écrire sur un autre système comme HDFS, HBase ou Elasticsearch.