Il n'y a pas si longtemps, j'ai écrit un article couvrant un aperçu des espaces de noms les plus courants. Les informations sont excellentes à avoir et, dans une certaine mesure, je suis sûr que vous pouvez extrapoler comment vous pourriez mettre ces connaissances à profit. Ce n'est pas normalement mon style de laisser les choses si ouvertes. Donc, pour les deux prochains articles, je passe un peu de temps à démontrer quelques-uns des espaces de noms les plus importants à travers l'objectif de la création d'un conteneur Linux primitif. Dans un certain sens, j'écris mes expériences avec les techniques que j'utilise lors du dépannage d'un conteneur Linux sur un site client. Dans cet esprit, je commence par la base de tout conteneur, en particulier lorsque la sécurité est une préoccupation.
Un peu sur les capacités de Linux
La sécurité sur un système Linux peut prendre plusieurs formes. Pour les besoins de cet article, je suis principalement concerné par la sécurité en ce qui concerne les autorisations de fichiers. Pour rappel, tout sur un système Linux est une sorte de fichier, et donc les autorisations de fichiers sont la première ligne de défense contre une application qui peut mal se comporter.
La principale façon dont Linux gère les autorisations de fichiers consiste à implémenter des utilisateurs . Il y a des utilisateurs normaux, pour lequel Linux applique la vérification des privilèges, et il y a le superutilisateur qui contourne la plupart (sinon la totalité) des vérifications. En bref, le modèle Linux d'origine était tout ou rien.
Pour contourner ce problème, certains programmes binaires ont le set uid peu mis sur eux. Ce paramètre permet au programme de s'exécuter en tant qu'utilisateur propriétaire du binaire. Le passwd utilitaire en est un bon exemple. N'importe quel utilisateur peut exécuter cet utilitaire sur le système. Il doit avoir des privilèges élevés sur le système pour interagir avec le shadow fichier, qui stocke les hachages des mots de passe utilisateur sur un système Linux. Alors que le passwd binaire a des vérifications intégrées pour s'assurer qu'un utilisateur normal ne peut pas changer le mot de passe d'un autre utilisateur, de nombreuses applications n'ont pas le même niveau de contrôle, en particulier si l'administrateur système a activé le set uid peu.
fonctionnalités de Linux ont été créés pour fournir une application plus granulaire du modèle de sécurité. Au lieu d'exécuter le binaire en tant que root, vous pouvez appliquer uniquement les fonctionnalités spécifiques dont une application a besoin pour être efficace. À partir du noyau Linux 5.1, il existe 38 fonctionnalités. Les pages de manuel pour les fonctionnalités sont en fait assez bien écrites et décrivent chaque fonctionnalité.
Un ensemble de capacités est la manière dont les capacités peuvent être attribuées aux threads. En bref, il existe cinq ensembles de fonctionnalités au total, mais pour cette discussion, seuls deux d'entre eux sont pertinents :Efficace et Autorisé.
Efficace :Le noyau vérifie chaque action privilégiée et décide d'autoriser ou non un appel système. Si un fil ou un fichier a le effectif capacité, vous êtes autorisé à effectuer l'action liée à la capacité effective.
Autorisé :Les capacités autorisées ne sont pas encore actives. Cependant, si un processus a autorisé capacités, cela signifie que le processus lui-même peut choisir d'élever son privilège en un privilège effectif.
Afin de voir quelles capacités un processus donné peut avoir, vous pouvez exécuter le getpcaps ${PID} commande. La sortie de cette commande sera différente selon la distribution de Linux. Sur RHEL/CentOS, vous obtiendrez une liste complète de fonctionnalités :
[root@CentOS8 ~]# getpcaps $$
Capabilities for `1304': = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read,38,39+ep
Si vous exécutez la commande man 7 capabilities , vous trouverez une liste de toutes ces fonctionnalités avec une description pour chacune. Dans certaines distributions, comme Ubuntu ou Arch, exécuter la même commande donne simplement ceci :
[root@Arch ~]# getpcaps $$
414429: =ep Il y a un espace blanc précédant le = signe. Cet espace blanc est interchangeable avec le mot-clé tous . Comme vous l'avez peut-être deviné, cela signifie que toutes les fonctionnalités disponibles sur le système sont accordées à la fois dans le E efficace et P ensembles de capacités autorisés.
Pourquoi est-ce important? Tout d'abord, les ensembles de capacités sont liés à un espace de noms d'utilisateur (dont je parle ci-dessous). Pour l'instant, cela signifie que chaque espace de noms aura son propre ensemble de capacités qui ne s'appliquent qu'à son propre espace de noms. Supposons que vous ayez un espace de noms appelé contraint . Il est possible que contraint il a l'air comme s'il avait toutes les capacités appropriées comme on le voit avec le getpcaps commande. Cependant, si contraint a été créé par un processus et un espace de noms qui ne disposaient pas d'un ensemble complet de fonctionnalités (comme un utilisateur normal), contraint ne peut pas recevoir plus d'autorisations sur un système que le processus de création.
Pour résumer, les capacités, bien qu'elles ne soient pas une technologie d'espace de noms, fonctionnent main dans la main pour déterminer ce que peuvent faire les processus à l'intérieur d'un espace de noms et comment ils peuvent fonctionner.
[ Vous pourriez également apprécier : Exécuter Podman sans racine en tant qu'utilisateur non root ]
L'espace de noms d'utilisateur
Avant de vous plonger dans la création d'un espace de noms d'utilisateur, voici un bref récapitulatif de l'objectif de cet espace de noms. Comme je l'ai expliqué dans un article précédent, les noms d'utilisateur, et finalement le numéro d'identification de l'utilisateur (UID), sont l'une des couches de sécurité qu'un système utilisera pour s'assurer que les personnes et les processus n'accèdent pas à des choses auxquelles ils ne sont pas autorisés.
Théorie de l'espace de noms utilisateur
L'espace de noms d'utilisateur est un moyen pour un conteneur (un ensemble de processus isolés) d'avoir un ensemble d'autorisations différent de celui du système lui-même. Chaque conteneur hérite de ses autorisations de l'utilisateur qui a créé le nouvel espace de noms d'utilisateur. Par exemple, dans la plupart des systèmes Linux, les ID utilisateur standard commencent à 1 000 ou plus. Dans le reste de cette série, j'utilise un utilisateur nommé container-user , qui a les identifiants suivants (les contextes SELinux sont omis pour ces démos) :
uid=1000(container-user) gid=1000(container-user) groups=1000(container-user) Il est important de noter qu'à moins d'être intentionnellement limité par l'administrateur système, tout utilisateur peut, en théorie, créer un nouvel espace de noms d'utilisateur. Ceci, cependant, ne fournit aucun obscurcissement aux administrateurs sur le système lui-même. Les espaces de noms d'utilisateurs sont une hiérarchie. Considérez le schéma ci-dessous :
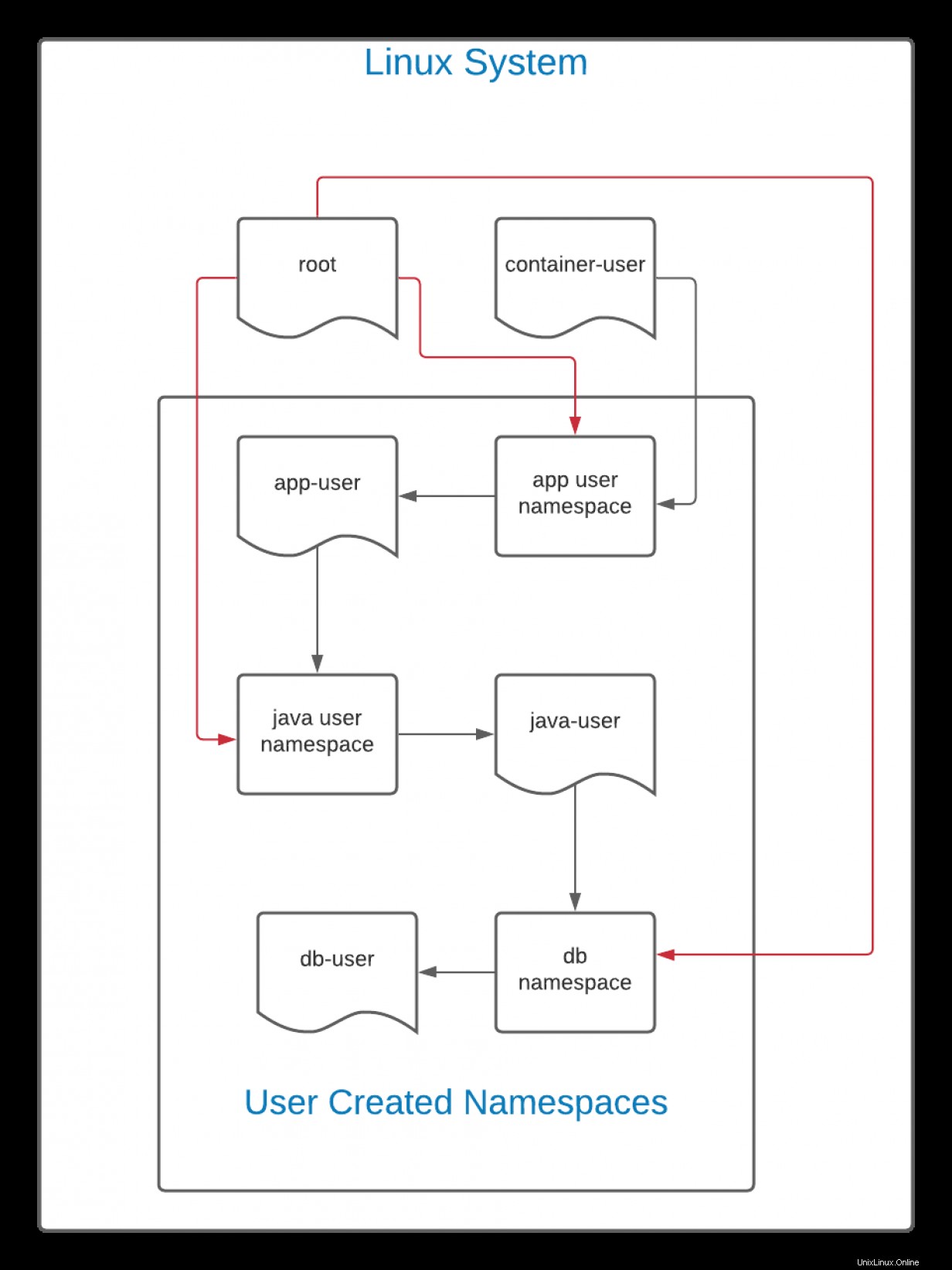
Dans ce schéma, les lignes noires indiquent le flux de création. L'utilisateur utilisateur-conteneur crée un espace de noms pour un utilisateur appelé app-user . En théorie, il s'agirait d'un frontal Web ou d'une autre application. Ensuite, utilisateur de l'application crée un espace de noms d'utilisateur pour java-user . Dans cet espace de noms, java-user crée un espace de noms pour db-user .
Comme il s'agit d'une hiérarchie, container-user peut voir et accéder à tous les fichiers créés par l'un des espaces de noms générés à partir de son UID. De même, parce que la racine l'utilisateur sur le système Linux peut voir et interagir avec tous fichiers sur un système, y compris ceux créés par container-user , la racine l'utilisateur (représenté par la ligne rouge) peut avoir une autorité totale sur tous les espaces de noms.
Cependant, l'inverse n'est pas vrai. L'utilisateur db l'utilisateur, dans ce cas, ne peut pas voir ou interagir avec quoi que ce soit au-dessus. Si le mappage d'ID reste le même (la stratégie par défaut), app-user , utilisateur Java , et db-user ont tous le même UID. Cependant, bien qu'ils partagent le même UID, db-user ne peut pas interagir avec java-user , qui ne peut pas interagir avec app-user , et ainsi de suite.
Toutes les autorisations accordées dans un espace de noms d'utilisateur ne s'appliquent qu'à son propre espace de noms et éventuellement aux espaces de noms en dessous.
Travail avec les espaces de noms d'utilisateurs
Pour créer un nouvel espace de noms d'utilisateur, utilisez simplement le unshare -U commande :
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -U
nobody@app-user$ La commande ci-dessus inclut un PS1 variable qui change simplement le shell afin qu'il soit plus facile de déterminer dans quel espace de noms le shell est actif. Fait intéressant, vous remarquerez que l'utilisateur n'est personne :
nobody@app-user$ whoami
nobody
nobody@app-user$ id
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody) En effet, par défaut, aucun mappage d'ID utilisateur n'a lieu. Lorsqu'aucun mappage n'est défini, l'espace de noms utilise simplement les règles de votre système pour déterminer comment gérer un utilisateur non défini.
Cependant, si vous créez l'espace de noms comme ceci :
PS1='\u@app-user$ ' unshare -Ur Le mappage sera automatiquement créé pour vous :
root@app-user$ cat /proc/$$/uid_map
0 1000 1 Ce fichier représente ce qui suit :
ID-inside-ns ID-outside-ns range La gamme La valeur représente le nombre d'utilisateurs à mapper. Par exemple, si c'était 0 1000 4 , le mappage serait ainsi
0 1000
1 1001
2 1002
3 1003 Etc. La plupart du temps, vous ne vous souciez vraiment que de la racine mappage utilisateur, mais l'option est disponible si vous le souhaitez. Que se passe-t-il lorsque vous créez l'utilisateur Java ? espace de noms ?
root@app-user$ PS1='\u@java-user$ ' unshare -Ur
root@java-user$ Comme prévu, l'invite du shell change et vous êtes l'utilisateur root, mais à quoi ressemble le mappage UID ?
root@java-user$ cat /proc/$$/uid_map
0 0 1 Vous voyez que maintenant, vous avez un 0 à 0 cartographie. En effet, l'utilisateur qui instancie le nouvel espace de noms est utilisé pour le processus de mappage d'ID. Depuis que vous étiez root dans l'espace de noms précédent, le nouvel espace de noms a un mappage de root pour raciner . Cependant, depuis root dans l'utilisateur de l'application l'espace de noms n'a pas de racine sur le système, le nouvel espace de noms root non plus utilisateur.
En plus de simplement vérifier le uid_map , vous pouvez également vérifier depuis l'extérieur de l'espace de noms si deux processus se trouvent dans le même espace de noms. Bien sûr, vous devez d'abord trouver le PID du processus, mais avec cela en main, vous pouvez exécuter la commande suivante :
readlink /proc/$PID/ns/user Pour rendre cela plus facile, j'ai exécuté ce qui suit :
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -Ur
root@app-user$ sleep 100000
Dans un autre terminal, j'ai déterré le PID et utilisé le readlink commande sur ce PID ainsi que sur le shell actuel :
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/$$/ns/user
user:[4026531837] Comme vous pouvez le voir, le lien utilisateur est différent. S'ils opéraient dans le même espace de noms, cela ressemblerait à ceci :
[root@localhost ~]# readlink /proc/1424/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275] Le plus grand avantage de l'espace de noms d'utilisateur est la possibilité d'exécuter des conteneurs sans privilèges root. De plus, selon la façon dont vous configurez le mappage UID, vous pouvez complètement éviter d'avoir un superutilisateur dans un espace de noms d'utilisateur donné. Cela signifie qu'il n'est pas possible d'exécuter des processus privilégiés à l'intérieur de ce type d'espace de noms.
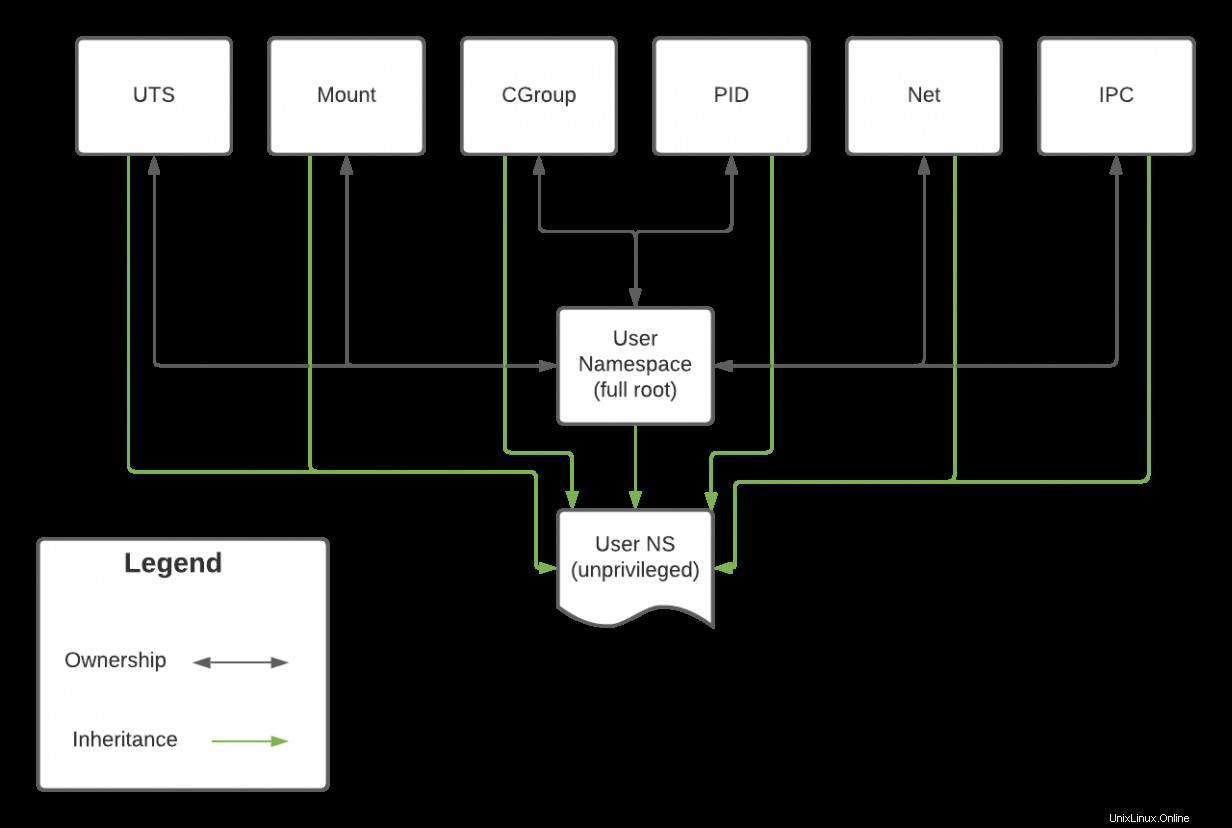
Remarque :L'utilisateur namespace régit chaque espace de noms. Cela signifie que les capacités d'un espace de noms sont directement liées aux capacités de son utilisateur parent espace de noms.
La racine complète d'origine L'espace de noms d'utilisateur possède tous les espaces de noms d'un système dans le diagramme ci-dessous. Cette relation a le potentiel d'être bidirectionnelle. Si un processus s'exécutant sur le net l'espace de noms s'exécute en tant que root , cela peut avoir un impact sur tous les autres processus appartenant à la racine espace de noms d'utilisateur. Cependant, bien que la création d'un espace de noms d'utilisateur non privilégié permette à ce nouvel espace de noms d'utilisateur d'accéder aux ressources d'autres espaces de noms, il ne peut pas les modifier car il ne les possède pas. Ainsi, alors qu'un processus dans l'espace de noms non privilégié peut ping une IP (qui s'appuie sur le net espace de noms), il ne peut pas modifier la configuration réseau de l'hôte.
Beaucoup de choses en dehors de ce que vous pensez en tant que conteneurs Linux utilisent des espaces de noms. Le format d'emballage Linux Flatpak utilise des espaces de noms d'utilisateurs ainsi que d'autres technologies afin de fournir un bac à sable d'application. Flatpaks regroupe toutes les bibliothèques d'une application dans le même fichier de distribution de packages. Cela permet à une machine Linux de recevoir les applications les plus récentes sans avoir à se soucier de savoir si vous avez la bonne version de glibc installé, par exemple. La possibilité de les avoir dans leur propre espace de noms d'utilisateur signifie que (en théorie) un processus qui se comporte mal à l'intérieur du flatpak ne peut pas modifier (ou peut-être même accéder) à des fichiers ou processus en dehors de l'espace de noms.
[ Vous débutez avec les conteneurs ? Découvrez ce cours gratuit. Déploiement d'applications conteneurisées :présentation technique. ]
Conclusion
L'utilisation d'espaces de noms d'utilisateurs ne résout pas à elle seule le problème que Flatpak et d'autres tentent de résoudre. Bien que les espaces de noms d'utilisateurs fassent partie intégrante de l'histoire de la sécurité et des capacités des autres espaces de noms, ils ne fournissent pas grand-chose par eux-mêmes. Il y a beaucoup à considérer lors de la création de nouveaux espaces de noms isolés. Dans le prochain article, je regarderai comment utiliser le montage espace de noms en conjonction avec l'espace de noms de l'utilisateur pour créer un chroot -like environnement avec des espaces de noms.
Si vous recherchez des défis pour vous aider à mieux comprendre, essayez de mapper une gamme d'utilisateurs dans le nouvel espace de noms. Que se passe-t-il si vous mappez toute la plage dans un espace de noms ? Est-il possible de devenir l'utilisateur apache dans un espace de noms non privilégié ? Quelles sont les implications de sécurité pour l'écriture d'un mauvais uid_map dossier? (Astuce :Vous aurez besoin de deux coques ouvertes; un pour créer et vivre à l'intérieur du nouvel espace de noms et l'autre pour écrire le uid_map et gid_map des dossiers. Si vous rencontrez des difficultés avec cela, envoyez-moi un message sur Twitter @linuxovens).